新型冠状肺炎之下,运用python采集央视网新闻频道再运用wordcloud生成词云,看民意关注关键词!

回 复 潘多拉 送 你 一 个 特 别 推 送![]()
疫情之下,更不要忘记学习!
![]()

中央电视台是国媒,央视网的新联栏目每天都会发布与民生息息相关的各种新联,2019年12月份以来,从钟南山教授权威发布武汉发现的病毒可以“人传人”开始,举全国之力抗击新型冠状病毒就紧罗密布的展示了,中视网新联频道发布新闻中有哪些高频词,一起来看。
 最终效果
最终效果
#!/usr/bin/python # -*- coding: UTF-8 -*- import requests import json import logging import codecs import json import time,datetime import re from pymongo import MongoClient import sys from lxml import etree from lxml import html from urllib.parse import urlparse
引入脚本依赖的python库;
MONGO_URI = 'localhost'
MONGO_DATABASE = 'cctv'
client=MongoClient('127.0.0.1',27017)
db=client['cctv']
collection=db['daynews1']
连接本地mongodb。
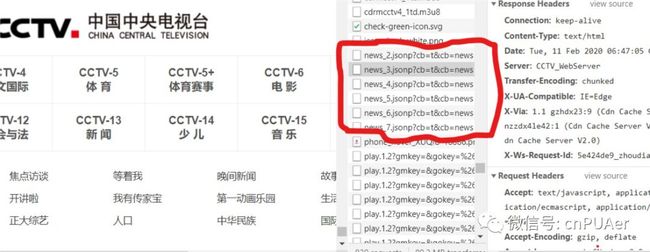
分析央视网新闻频道得出数据请求规律
CRAWL_START=False #因为我把下面的结巴分词,wordclond生成词云都放在了这一个文件里,所以你看到了我定义了一个CRAWL_START的常量。为False就不会执行爬虫了,只会执行下面结巴分词完然后生成词云的逻辑if CRAWL_START:
#获取到当前时间
dt=datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
# logger = logging.getLogger(__name__)
LOG_FILENAME='test.log'
logging.basicConfig(filename=LOG_FILENAME,level=logging.INFO)#控制台编码如果与文件编码或抓取过来数据编码不一致会报错 很多打印进日志也方便查看
headers = {#请求头信息
'User-Agent': 'Mozilla/5.0 (Linux; Android 7.1; Mi A1 Build/N2G47H) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.83 Mobile Safari/537.36',
}
def logger(msg):
# logging.info('\n')
logging.info('\n'+str(dt)+'>>>>>>>>>>>>>>>:'+msg)
#list数据结构转字符串下面会用到
def listToString(s):
# initialize an empty string
str1 = ""
# traverse in the string
for ele in s:
str1 += ele
# return string
return str1
print('程序开始执行')#爬虫主体开始
start_time=datetime.datetime.now()#记录开始时间 后边也记了结束时间 记录脚本运行时间 方便优化性能
logging.info('>>>>>开始执行时间'+time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
for i in range(1,8,1):
url='http://news.cctv.com/2019/07/gaiban/cmsdatainterface/page/china_%d.jsonp?cb=t&cb=chin' % (i)
# logger(url)
res=requests.get(url,headers=headers)#requests发起get讲求
res.encoding = 'utf-8'#对请求结果指定编码与文件编码一致
res=str(res.text.replace('china','',1))#返回的json结构前有'china'使返回数据不能直接使用,云掉头部'china'字符,使其成为标准的json字串
# res=json.dumps(res)
# json_data=json.loads(res)
pattern=re.compile('\((.*)\)')#字串外部有括号,json标准是在“{}”中间,因此指定此正则规则
matches=re.search(pattern,res)#从带括号的json数据中警醒“{}”符号中标准的json数据
bbb=eval(matches.group(1))#group(0)通常是全部数据,group(1)是我们目标数据,经过eval转成list
data_list = bbb['data']['list']#定位我们要loop的部分
insert_list_data = []
for elem in data_list:#循环json中的一条条数据
logger(elem['url'])
inner_url = elem['url']
if inner_url:
urlarray = urlparse(inner_url)
netloc = urlarray[1] if urlarray[1] else ''
if "news" not in netloc or netloc == '':#只采集news.cctv.com中的数据,不是则遍历下一条
logging.info('不是news,请检查')
continue
res = requests.get(inner_url)
res = html.fromstring(res.content)#用dom解析,所以转成可处理的结构
# aaa = etree.tostring(res)
insert_data = {}
h1 = res.xpath('//h1/text()')[0]#标题
h1 = h1.__str__()
try:#因为新联详情也有不同的结构,要对不同页面兼容,所以用了try catch进行兼容
content = res.xpath('//div[@class="content_area"]//text()')
content = listToString(content)
content = content.strip()
if not content:#无内容的直接跳出当前逻辑,遍历下一条
continue
editor = res.xpath('//div[@class="zebian"]//text()')
editor_string = listToString(editor).strip()
editor_string = editor_string.replace("\r\n", "|").replace(" ", "")#编辑信息
info = res.xpath('//div[@class="info1"]//text()')[0]
info = info.__str__()#包含有来源和发布日期
logging.info(info)
if info:
info_res = info.split('|')
created_by = info_res[0] if info_res[0] else ''#来源
array = time.strptime(str(info_res[1]).lstrip(" "), u"%Y年%m月%d日 %H:%M")
created_at = int(time.mktime(array)) if array else ''#发布日期
else:
created_by = ''
created_at = ''
except Exception as e:#逻辑同上
content = res.xpath('//div[@id="text_area"]//text()')
content = listToString(content)
content = content.strip()
if not content:
continue
editor = res.xpath('//div[@class="relevance"]//text()')
editor_string = listToString(editor).strip()
editor_string = editor_string.replace("\r\n", "|").replace(" ", "")
info = res.xpath('//span[@class="info"]//i[1]//text()')
if info:
created_by = info[1] if info[1] else ''
array = time.strptime(str(info[2]).lstrip(" "), u"%Y年%m月%d日 %H:%M")
created_at = int(time.mktime(array)) if array else ''
else:
created_by = ''
created_at = ''
finally:
logging.info('无处理规则,请检查,当前处理的url是:' + str(test_url))
#汇总数据成dict
insert_data = {'title': h1, 'url':inner_url, 'content': content, 'editor': editor_string, 'created_by': created_by,'created_at': created_at}
logging.info(insert_data)
#dict结构数据往list数据结构中添加,方便后边mongodb一次插入,避免组好一条插入一次损耗性能
insert_list_data.append(insert_data)
logging.info(insert_list_data)
if insert_list_data:
collection.insert_many(insert_list_data,ordered=False)#入库
print('>>>>插入数据库成功,入库数据条数:'+str(len(insert_list_data)))
else:
pass
end_time = datetime.datetime.now()#结束时间
duration = end_time - start_time#脚本运行时间
logging.info('>>>>>结束执行时间' + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())))
print('程序总共执行时间为:')
print(duration)
执行脚本,数据写库,并直接登录mongo查看数据是否写库正常,有没有出现乱码之类
看写完库的数据把标题打印出来看看效果,看有没有乱码之类
import jieba_fast as jieba
import jieba.analyse
import jieba.posseg as pseg
import codecs,sys,os
from string import punctuation
from pathlib import Path
from os import path
import collections
import numpy as np
import wordcloud
from PIL import Image
import matplotlib.pyplot as plt
from contextlib import ExitStack
from itertools import zip_longest
#定义成类,规范一些
class Statistics(object):
#初始化中完成mongodb连接,注意与上面连接方式对比
def __init__(self):
self.connection=MongoClient('127.0.0.1',27017)
self.db=self.connection.cctv
self.collection=self.db.daynews1
#封装从collection取出所有数据方法
def get_all(self):
return self.collection.find()
#把主体内容简单处理一下写进test1.txt文件(在main部分先要执行这个方法)
def extract_one(self,file=None):
add_punc = ',。、【 】 “”:;()《》‘’{}?!⑦()、%^>℃:.”“^-——=&#@¥'
all_punc = punctuation + add_punc
ins = Statistics()
path_str = Path(file)
if not path_str.exists() or not path_str.is_file():
data_list = self.get_all()
large_text = ''
for item in data_list:
large_text += str(item['content'])
codecs.open("test1.txt", 'w', encoding="utf-8").write(large_text)
print('执行完毕')
print('打开文件')
f = codecs.open(file, 'r+', encoding='utf-8')
line_number = 1
line = f.readline()
while line:
print('----->>>>>执行', line_number, ' -------------')
line_seg = " ".join(jieba.cut(line))
test_line = line_seg.split(' ')
res = []
for elem in test_line:
res.append(elem)
if elem in all_punc:
res.remove(elem)
line_seg2 = " ".join(jieba.cut(''.join(res)))
target = codecs.open('output1.txt', 'w+', encoding='utf-8')
target.writelines(line_seg2)
line_number = line_number + 1
line = f.readline()
f.close()
target.close()
exit()
#弃用
def parse_multiple_files1(self,flist=[]):
output=[]
with ExitStack() as stack:
files=[stack.enter_context(codecs.open(fname,'r+',encoding='utf-8')) for fname in flist]
print(files)
for lines in zip_longest(*files):
output.append(str(lines).replace('\r\n',''))
exit()
return output
#停用词文件合并处理,下面会用到
def parse_multiple_files(self,flist=[]):
output=[]
if flist:
for item in flist:
fp=codecs.open(item,'r+',encoding='utf-8')
wordlist=fp.readlines()
for word in wordlist:
output.append(word.strip())
return output
else:
return []
#读取mongodb中存的数据中的正文部分来生成词云(extract_one执行完成后已经生成test1.txt文件)
def extract_two(self,file=None):
#初始化读取
fn=codecs.open(file,'r+',encoding='utf-8')
string_data=fn.read()
fn.close()
# 文本预处理
pattern = re.compile('[’!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~。“”、:?,【】!()——↓0-9a-zA-Z\.\.\.\.\.\.]+')
# pattern = re.compile(u'\t|\n|\.|-|:|;|\)|\(|\?|"')
string_data = re.sub(pattern, '', string_data) # 将不符合模式的字符去除
#去掉一些没被过滤的特殊字符
string_data = string_data.replace('\n', '')
string_data = string_data.replace('\u3000', '')
string_data = string_data.replace('\r', '')
string_data = string_data.replace(' ', '')
logging.info(string_data)
# 文本分词
seg_list_exact = jieba.cut(string_data, cut_all=False) # 精确模式分词
object_list = []
#自定义停用词列表,具体需求需体分析,把你想移除的都可以加进来
remove_words_custom = [u'的', u',', u'和', u'是', u'随着', u'对于', u'对', u'等', u'能', u'都', u'。',
u' ', u'、', u'中', u'在', u'了', u'通常', u'如果', u'我们', u'需要',u'月',u'日'] # 自定义去除词库
remove_words = self.parse_multiple_files(['中文停用词表.txt','哈工大停用词表.txt','四川大学机器智能实验室停用词库.txt','百度停用词表.txt'])
remove_words=remove_words_custom+remove_words#通过停用词和自定义停用词合并
for word in seg_list_exact: # 循环读出每个分词
if word not in remove_words: # 不在停用词列表中的词,才会被加入制造词云的列表中
logging.info('\n')
logging.info(word)
object_list.append(word) # 分词追加到列表
logging.info(object_list)
# 词频统计
word_counts = collections.Counter(object_list) # 对分词做词频统计
word_counts_top10 = word_counts.most_common(10) # 获取前10最高频的词
print(word_counts_top10) # 输出检查
# 词频展示
font_path=r'C:\Windows\Fonts\simfang.ttf'
mask = np.array(Image.open('background.jpg')) # 定义词频背景
wc = wordcloud.WordCloud(
background_color='white', # 设置背景颜色
font_path=font_path, # 设置字体格式
mask=mask, # 设置背景图
max_words=200, # 最多显示词数
max_font_size=200 , # 字体最大值
scale=80 # 调整图片清晰度,值越大越清楚
)
wc.generate_from_frequencies(word_counts) # 从字典生成词云
image_colors = wordcloud.ImageColorGenerator(mask) # 从背景图建立颜色方案
wc.recolor(color_func=image_colors) # 将词云颜色设置为背景图方案
plt.figure()
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show() # 显示图像
wc.to_file("bb.jpg") # 将图片输出为文件
if __name__ == '__main__':
ins=Statistics()
#数据爬完之后,先执行这里,然后注释掉
# ins.extract_one('test1.txt')
#生成词云的逻辑,最后一步执行
ins.extract_two('test1.txt')
打完收工,并附上github地址:[email protected]:1060460048/jieba_demo.git。如果只想试试数据,公众号窗口发送关键字"cctv的mongo数据"获取。(部分图片来自互联网,侵删)
CnPuaer∣一个专注效率脱单的公众号


长按,识别二维码,加关注