Flink Job执行流程分析
之前写过一篇文章分析过Flink的基本架构,当时大概了解了JobManager、TaskManager、Slot等概念,本文主要是想了解下Flink中Job的执行流程,老是把Job执行当成一个黑盒总感觉难受。
之前说过Flink Job Client负责讲任务提交给JobManager执行,Client可以和JobManager通信获取作业的执行状态。JobManager负责接收Flink作业、资源管理(Slot)、task调度、Checkpoint发起等等,TaskManager负责真正执行任务。TaskManager负责从JobManager 接收需要部署的任务,然后使用 Slot 资源启动执行Task。
JobManager启动任务:
DisPatcher类(该类用于接受任务,每个Job会对应启动一个JobManager,我的任务基本上都是Yarn Single Job,所以暂时不详细了解这 个类了)中的runJob(JobGraph jobGraph)方法看进去,可以看到它分成了两步:
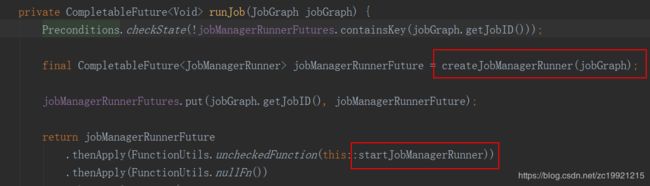
首先是JobManager的创建,注释是创建了ha、leaderElection以及JobMaster(内部有rpc、heartbeat、slotPool、scheduler、backpressure、checkpoint等服务)看注释:
The job master is responsible for the execution of a single * {@link JobGraph}.
slotPool用于管理TaskManager和slot资源,scheduler用于jobGraph的拆分以及调度,后续有时间再仔细研究吧:

启动没啥好说的,调用了它的start()方法启动,内部会启动JobMaster。启动RPC并调度作业执行,并发送给TaskManager,内部逻辑挺复杂的...后续再细研究吧:

TaskManager的启动:
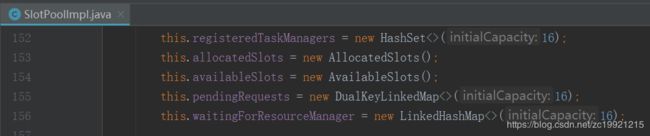
从TaskManagerRunner类中看进去,和JobManager一样,也是创建了rpc、metric、ha等服务,核心的是它的startTaskManager()方法,里面创建了kvStateService(看注释,保存Key State用的?)、broadcastVariableManager、Slot等等...太多了,不一一例举了,这里说下Slot,确实是平分了TaskManager中的内存:


然后会调用start方法,向JobManager发送ControlMessages.START消息,表示TaskManager已经启动了,可以执行任务了。
TaskManager执行用户任务过程:
之前说过Client会讲用户逻辑转化成StreamGraph结构,然后根据Chain将多个SubTask(算子子任务)串联在一起执行,这个结构称为JobGraph。然后将JobGraph发送给JobManager,JobManager会讲任务并行化,称为ExecutionGraph,调用startScheduling()方法最终生成物理执行图分发给TaskManager执行。
TaskExecutor对象的submitTask()方法会接收JobManager发送过来的TDD对象(代表chain在一起的Task)执行,看类注释:

首先会初始化一些信息,重要的是会初始化一个Task类,这个类实现了Runnable,是一个线程,作用如下:

初始化Task时,内部会初始化ResultPartitionWriter[] 和IndexedInputGate[],分别用来发送Task的结果和接受上游Task的数据(这两个东东还是反压有关,后续了解下...)。初始化完毕之后,就调用start()方法把线程给运行起来了。来看下Task的run()方法,了解下Task线程是如何运行起来的,忽略掉一些细节,核心是下面这几行代码:
反射创建一个StreamTask类,invoke最终会执行到用户的代码逻辑: // we must make strictly sure that the invokable is accessible to the cancel() call // by the time we switched to running. this.invokable = invokable;// run the invokable invokable.invoke();
invoke内部分成了beforeInvoke()、runMailboxLoop()、afterInvoke()这三步,beforeInvoke()主要是init task相关环境、比如open state,并且它会根据用户的输入创建不同类型的Process(后面会说道):

runMailboxLoop()是真正执行用户方法:
可以看出来任务正常情况下是会一直不停的运行: while (runMailboxStep(localMailbox, defaultActionContext)) { }内部会调用上面说的process,执行用户代码
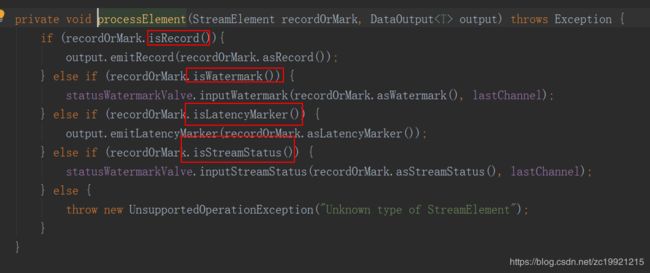
protected void processInput(MailboxDefaultAction.Controller controller) throws Exception { InputStatus status = inputProcessor.processInput();根据数据的不同类型,执行不同的操作,如下图所示:
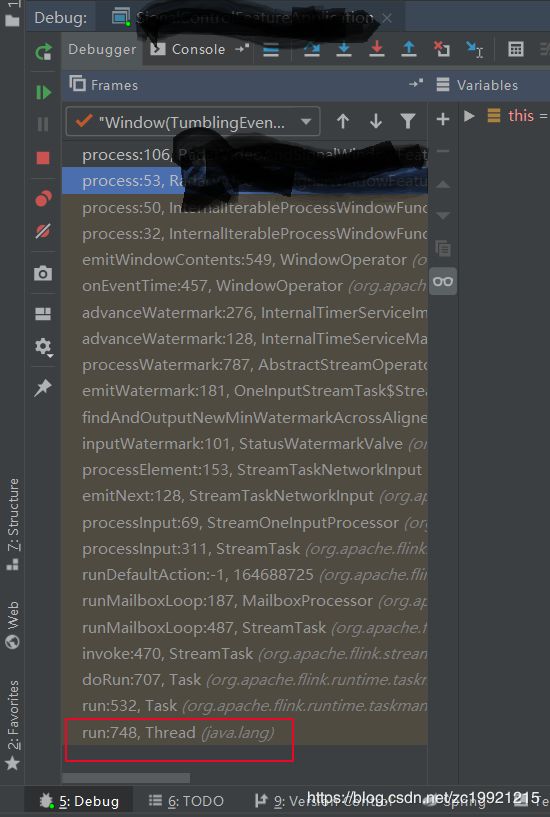
以当时调试WaterMark为例,看下面这张图片就可以了解方法的调用栈了:
最后总结一下:
Client负责讲用户代码转成JobGraph,提交给JobManager执行。
JobManager负责Flink作业、资源管理(Slot)、task调度、Checkpoint发起等等。JobManager接受JobGraph,将其转变成ExecutionGraph,再将其转变成TDD(Task Deployment Descriper),发送给TaskManager执行。
TaskManager负责真正执行任务。TaskManager从JobManager接收TDD对象,每个对象都会启动一个线程,每个线程都有对应的输入输出空间:InputGate和ResultPartition,根据用户选择的算子创建不同的Process,然后不停的执行用户代码。
(ps: 总感觉Flink和Spark很像,后续再了解下Graph之间是如何转化的,还有Flink的反压)
参考:
https://www.cnblogs.com/nicekk/p/11561836.html(Flink中的角色介绍)
https://www.lagou.com/lgeduarticle/7771.html(TaskManager执行)
https://zhuanlan.zhihu.com/p/22736103(Graph转化)
https://www.cnblogs.com/ljygz/p/11504220.html(Task执行流程)
https://developer.aliyun.com/ask/128756?spm=a2c6h.13159736(JobManager 与 JobMaster)
https://www.cnblogs.com/bethunebtj/p/9168274.html(Flink Graph的生成)