商品销售数据建模及分析
一、概述
本篇的数据集及程序代码上传在个人github上
本文针对所给的酒类商品销售数据集进行了以下两大类分析:
(1) 统计分析类
- 酒种的销售统计
- 地区的销售统计
(2) 建模分析类
- 相似用户反馈
- 相似商品反馈
- 协同过滤推荐
- 感兴趣用户推荐
- 地域优先推荐
- 用户流失度分析
- 高价值用户分析
其中用户流失度分析及高价值用户分析依赖更加完整的数据集(订单的时间序列及单次订单消费金额等信息),本篇暂时不讨论
二、总体分析
2.1 逻辑架构
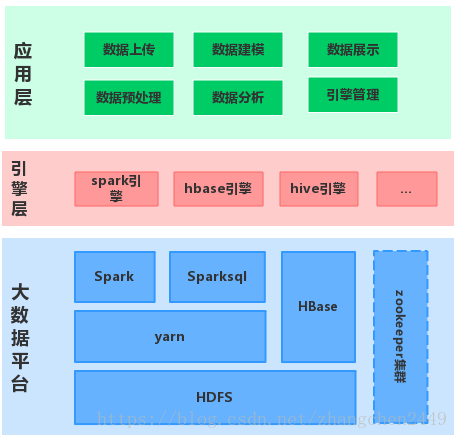
其中主要的技术选型如下:
- HBase:数据存储
主要存储预处理之后的商品及用户基本信息以及用户购买行为信息。 - Spark:离线数据分析
从HBase中读取用户行为数据,构建基于Machine Learning的数据模型 - HDFS:模型及特征矩阵存储
导出Spark学习出的稳定数据模型及特征矩阵到HDFS中 - Zepplin:数据可视化
支持多种数据展示效果:列表、柱状图、饼图等。在intepreter支持下可方便对接HBase和Spark - Zookeeper:分布式集群管理
分布式HBase、Spark等组件使用Zookeeper来管理集群
注:其实数据样本记录不多,所以没有使用Flume(数据采集)、Kafka(数据传输)及Storm(实时数据分析)等组件
2.2 物理部署
建议三台以上机器搭建大数据分析及应用平台,软件部署情况可参考如下:
| 机器别名 | 安装软件 |
|---|---|
| Machine01 | Hadoop-2.6.4, spark-1.6.5, HBase-1.2.2, ZK-3.4.8, zeppelin-0.6.2 |
| Machine02 | Hadoop-2.6.4, spark-1.6.5, HBase-1.2.2, ZK-3.4.8 |
| Machine03 | Hadoop-2.6.4, spark-1.6.5, HBase-1.2.2, ZK-3.4.8 |
三、详细分析
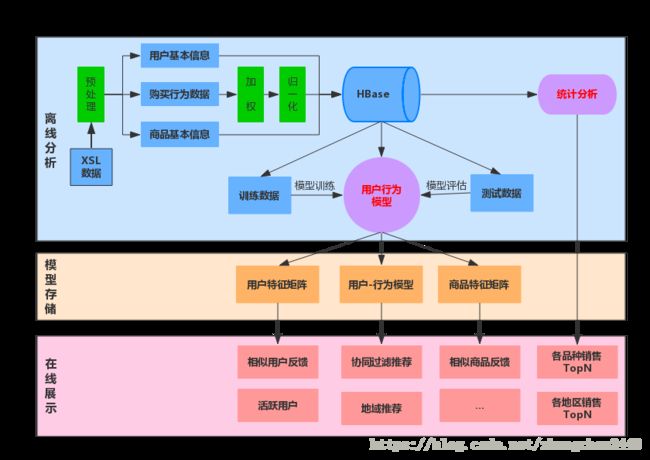
3.1 运行时架构
3.2 数据预处理
针对原始的xsl数据,这里进行了预处理,处理后的结果存在HBase中:
- brand-info表:酒品牌基本信息,包含品牌名称,所属分类以及编号信息
| 主键(row key) | 列簇(Family) | 列(Column) | 含义(Description) |
| ID (酒品牌编号) | brandinfo | brand | 品牌名称 |
| category | 所属分类 |
- user-info表:包含两个列簇,userinfo列簇包含用户名称,地址等基本信息,orderinfo列簇存储用户购买的酒品牌的编号列表
| 主键(row key) | 列簇(Family) | 列(Column) | 含义(Description) |
| ID (用户Id) | userinfo | name | 用户名称 |
| 邮箱 | |||
| phone | 手机号码 | ||
| province | 省 | ||
| city | 市 | ||
| zone | 区 | ||
| min | 最小购买能力 | ||
| max | 最大购买能力 | ||
| ordernum | 订单数 | ||
| orderinfo | orderindexs | 用户购买的品牌id列表 |
3.3 统计分析
主要是利用基于spark的mapreduce能力按照品种和地域对酒的销售情况进行了统计,统计结果存储在HBase中
- cate-sale表:存储品牌,销售记录
| 主键(row key) | 列簇(Family) | 列(Column) | 含义(Description) |
| brand (品牌) | catesale | salenum | 某品牌的销售数量 |
- zone-sale表:存储地区及销售记录,其中主键的组成方式为”省市区_品牌”
| 主键(row key) | 列簇(Family) | 列(Column) | 含义(Description) |
| key (组合主键) | zonesale | salenum | 某地区某品牌的销售数量 |
3.4 建模分析
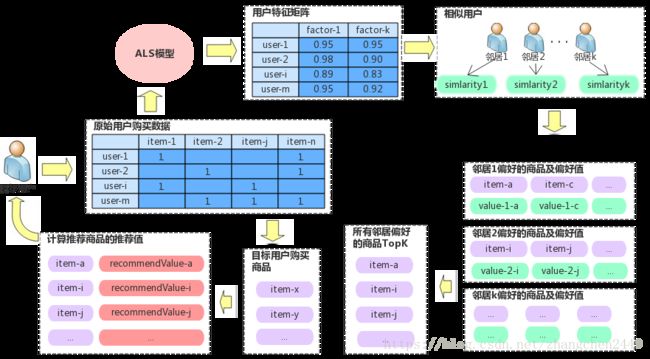
3.4.1 ALS 矩阵分解模型

该模型的原理直观的表示为上图,交替最小二乘算法(ALS)将可将高维的用户-评分矩阵 R R 分解为两个低维的用户特征矩阵 U U 和商品特征矩阵 V V 。使得 R,U,V R , U , V 满足: R≈UTV R ≈ U T V 。其中维数 k k 作为算法的参数输入,即隐藏因子。该模型一方 main可以解决原始用户评分矩阵可能存在的数据稀疏问题,另一方面 分解后的用户特征矩阵和商品特征矩阵可用于后续的协同过滤推荐及相似用户挖掘等。
我们在数据预处理部分已经对用户和酒品牌进行了编号,这里将所有用户的购买记录转化为用户评分矩阵(例如:编号为3的用户购买了编号为5的酒,则有用户评分矩阵 R R 的第三行第五列元素 r3,5=1 r 3 , 5 = 1 ),为了得到用户特征矩阵 U U 和商品特征矩阵 V V ,需要对以下公式进行最小化求值。
argminU,V∑{i,j|ri,j≠0}(ri,j−uTivj)2+λ(∑inui||ui||2+∑invj||vj||2) arg min U , V ∑ { i , j | r i , j ≠ 0 } ( r i , j − u i T v j ) 2 + λ ( ∑ i n u i | | u i | | 2 + ∑ i n v j | | v j | | 2 )
其中 λ λ 是正则化系数, nui n u i 为用户 I I 有购买过的商品数 nvj n v j 为商品j总计被购买的次数。这种防止过拟合的正则化方案被称作加权 λ λ 正则化。模型训练的过程如下:

3.4.2 余弦相似度模型
余弦相似度模型,是在提取出待评估个体(用户或商品)的特征矩阵之后,采用如下公式计算出待评估个体之间的相似度(数值越大越相似)
因此只要构造出个体(用户或商品)的特征举证,就可以利用该模型计算出某个用户的相似用户以及某个商品的相似商品。这里的特征矩阵可以直接采用ALS模型中分解出来的用户特征矩阵及商品特征矩阵。也可以根据实际情况融入多维特征,例如将地域特征加入用户特征矩阵中,计算出的相似用户就带有地域相近的含义。
3.4.3 协同过滤推荐模型
协同过滤推荐由分为基于用户的协同过滤推荐和基于物品的协同过滤推荐
1. 基于用户的协同过滤推荐
该算法先寻找与目标用户有相同喜好的邻居(也即相似度高的邻居用户),然后根据相似用户的喜好产生向目标用户的推荐。显然我们在余弦相似度模型中已经建立了用户和其相似用户的度量标准,这里可以直接选择目标用户相似度高的数个用户的购买记录为目标用户推荐
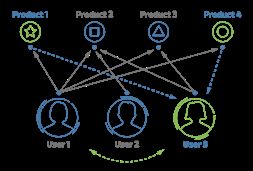
2. 基于物品的协同过滤推荐
该算法先根据所有用户对物品或者信息的评价,发现物品和物品之间的相似度,然后根据用户的历史偏好信息将类似的物品推荐给该用户。显然我们在余弦相似度模型中已经建立了物品及其相似物品的度量标准,这里可以根据目标用户的购买记录选择和其已经购买物品相似度最高的数个物品为目标用户推荐。

3.5 整体流程图
四、结果展示
选用Zepplin作为结果展示的工具,基于网页notebook提供交互式数据分析及可视化。分析维度及结果如下:
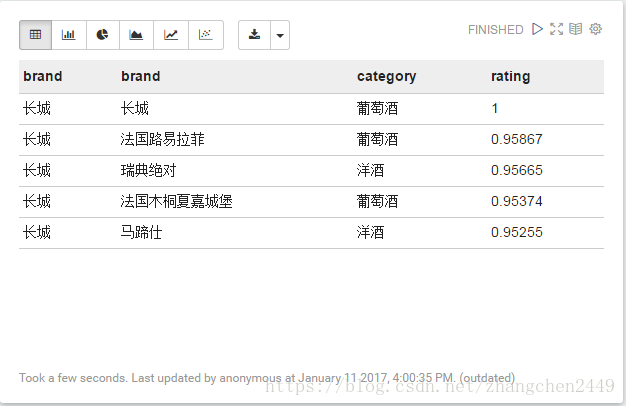
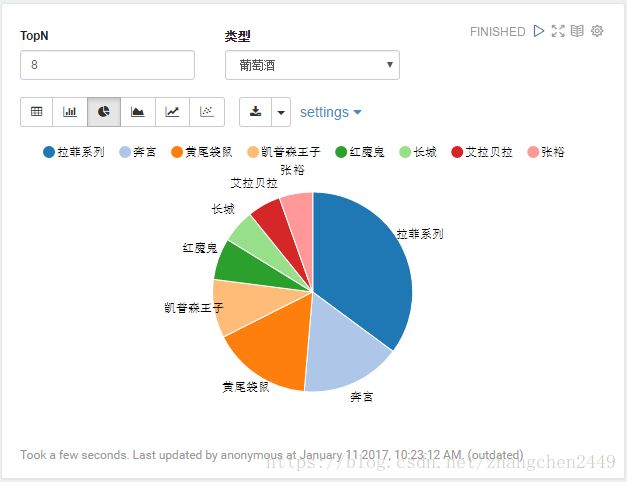
1. 酒种的销售统计
统计某种类型酒的TopN的销售情况,其中类型以下拉框的形式选择,TopN为可编辑的文本框。支持多种展示形式,后面不再赘述

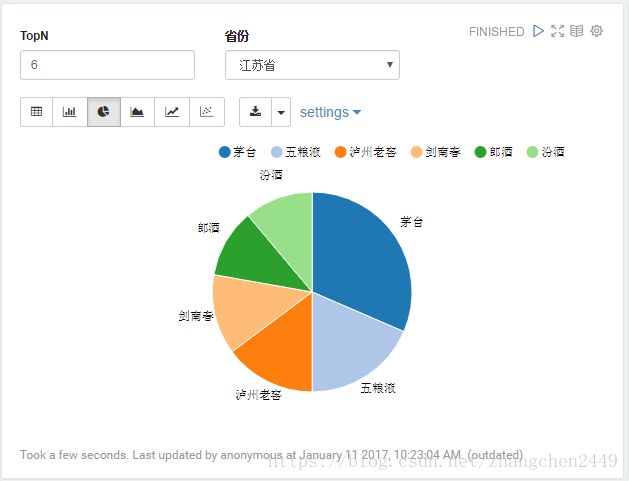
2. 地区的销售统计
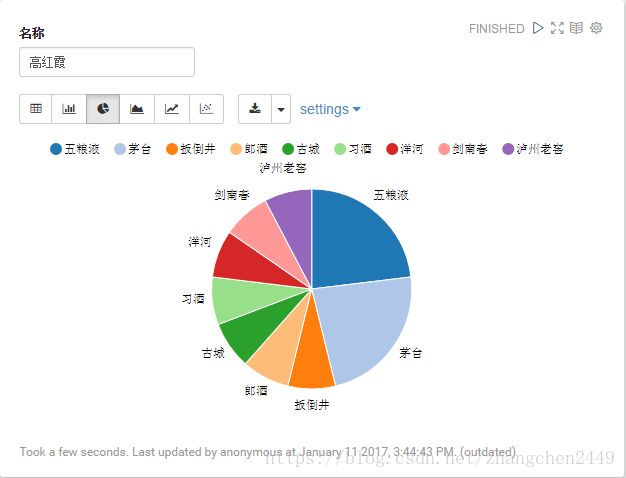
3. 地域优先推荐
针对指定用户(输入用户名称或编号),推荐其附近的人购买的品牌
4. 协同过滤推荐

5. 感兴趣用户推荐
针对某一品牌,挖掘可能对该品牌该兴趣的用户
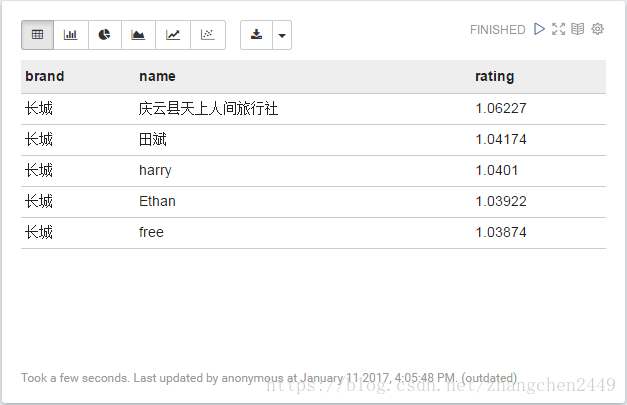
6. 相似用户反馈
针对某一用户,挖掘其相似购买行为的用户及相似度度量值

7. 相似商品反馈