P图技术日新月异,有些P图大神的作品,让我们驻足相忘~嗷嗷,如何使用神经网络对这些大神的P图风格进行学习,我们这篇论文就提出了下面的方法。我认为这篇文章能很好的帮助我们去理解浅层的神经网络,然后他提出了一个描述子【文中花很大篇幅介绍这个描述子】作为网络的输入,再然后在选择训练图片上【得到有代表性的图片】,提出了自己的方法。
框架最开始是选择有代表性的图片,比如选出了下面的这个图片。
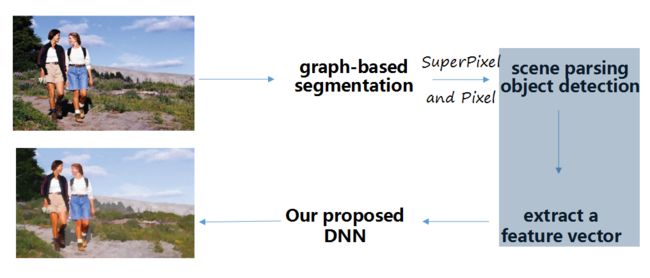
我们需要知道,我们训练的目的是什么?既然提到了神经网络,人家是怎样把一个图片调整的问题使用神经网络去解决呢?
接下来,我们先回答下这两个问题,然后按照框架的流程,依次来解释他是如何做到的。
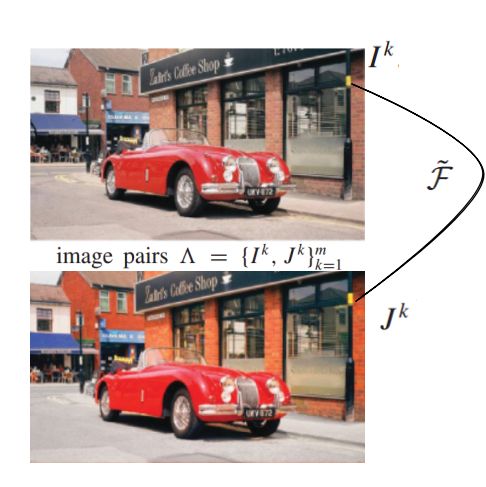
1.训练目的
首先,描述下图片调整的流程,假设,我们存在很多图像对,上面车车的示例只是其中一对,看原图中右上角的黄色标记(右侧黑弧线上起点处),便于理解,把这个黄色的标记看成是一个像素,把这个像素表示为描述子【高维向量】,通过一个映射函数F,得到对应像素的颜色值(黑色弧线下终点,深黄色)。
我们网络训练的目的就是,训练得到一个F映射函数,对于输入的所有描述子,输出得到像素的值与对应像素真实值的差异最小->也就是我们的目标函数。
2.如何使用神经网络去解决图片调整的问题?
神经网络可以表示任意复杂的连续函数,所以可以使用神经网络得到上面提到的映射函数F,【Hornik et al.1989论文下载】,举个可以理解的例子,我假设大家了解了CNN的基础知识了,对于CNN的框架,我们输入是一张 长*宽*通道数 这么大的图片,最终得到的是高维向量表示这张图片。对于我们的图片调整的例子呢?我们输入的是一个高维向量,得到的是调整后对应像素的颜色值。这两个过程都是由多->少的过程,所以,我们也可以用神经网络来解决图片调整的问题。【实际上是神经网络可以解决回归问题(多自变量对一个因变量)】
这两个问题解决完了,我们按照框架流程,依次解释他要做什么和他怎么做到的。
一、选取有代表性的图片
为什么要选取有代表性的图片呢?
基于图像对的增强,需要艺术家对图片操作,得到对应的图片。既然要让艺术家处理,总不能让人家处理上万幅图片吧----累死他了。所以我们要向找出有代表性的图片,选取的是尽量少的图片包含的物体类别最丰富,作为我们的训练样本的同时,让艺术家减少工作量【省钱啊】。
延伸下,如果现实有这种大量数据图像对存在的话,我认为可以把他们用深层的网络直接对图片进行训练。可以参考Let there be Color!
如何选取呢?
首先,我们有一堆原图,如何选出一个有代表性的子集让艺术家来处理,文中提出了交叉熵的方法。第一部分用的是BOW【关于BOW详细介绍请看我的另一篇文章】,然后呢,使用信息熵来选取了。
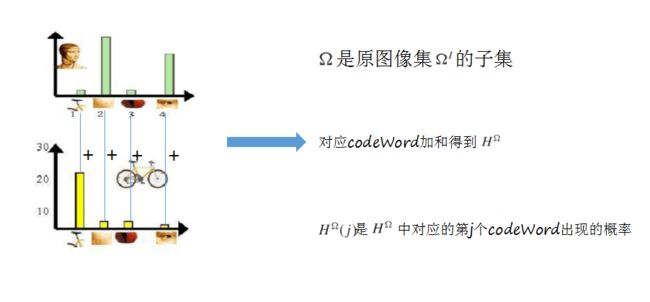

首先,我们知道当一个随机变量均匀分布时,熵值最大,这里的随机变量指的直方图的横坐标物体类别数即BOW中的【codewords】,我们就是想要codeword都尽可能出现,并且出现的概率是一样的,这样选出的图片中的类别就很丰富。
二、选取有代表性的像素点
为什么要选取有代表性的像素呢?
比如,一张图片中人只占图片的一小部分,天空占据整张图片的绝大部分,如果用图片的所有像素进行训练,映射函数中就会包含很多天空的映射信息,导致训练很不平衡。这样就保证了映射函数中不同类别均衡。此外,过度密集的像素会增加训练代价。
如何选取呢?
对一张图片I,我们使用基于图的分割,从每个不规则的区域中,选取固定数量的pixel。
三、新的描述子用于这些有代表性的像素
如何描述?
首先,先使用场景分割,和物体分割。【用于之后的描述】

先进行场景分割,主要分割出草地、路、天空,得到Parsing map。类别数Sp【SceneParsing】
在进行目标分割,主要分割出人、车、建筑物,得到每个类别的detection置信图。最后,把这些融合起来,在每个像素位置,选出置信度最高的值,作为这个像素的类别,得到Detecion map。类别数Od【Object Detection】
然后,将上面两个分割结果合并,合并时,我们把目标分割置信值大于一个阈值的像素label保留,去直接覆盖场景分割的label。对于最终合并的图,会有一些噪声,我们使用了别人的算法解决这些噪声,得到最终的语义标签map。
对于给定分割好的语义图,我们找到之前得到的那些像素点,对这些像素点操作,找出一个P作为示例,下面是得到他的描述子过程。
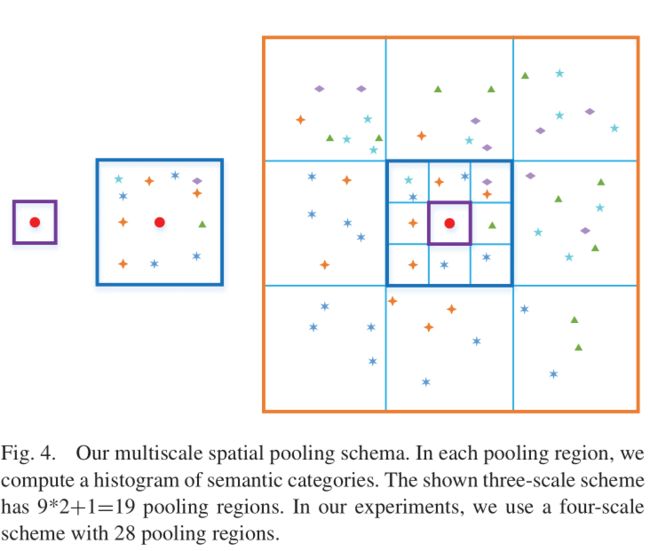
根据分割的结果,在P的周围划出一个正方形区域,区域生成是以等比数列倍数为3生成,如上图所示,根据框里的内容,生成一个直方图,横坐标是 场景类别+物体类别=所有的label标签,类似于bow中的直方图横坐标codeword。纵坐标是划分区域之后对应label类别出现的次数。我们直接串联所有的lebel对应的数值,生成具有上下文意义的描述。试验中,作者使用积分图简化计算,详细可以私信讲。
这样,具有上下文信息的特征就得到了,我们再融合像素本身特征+全局特征得到最终的描述子。
四、我们的深度神经网络模型
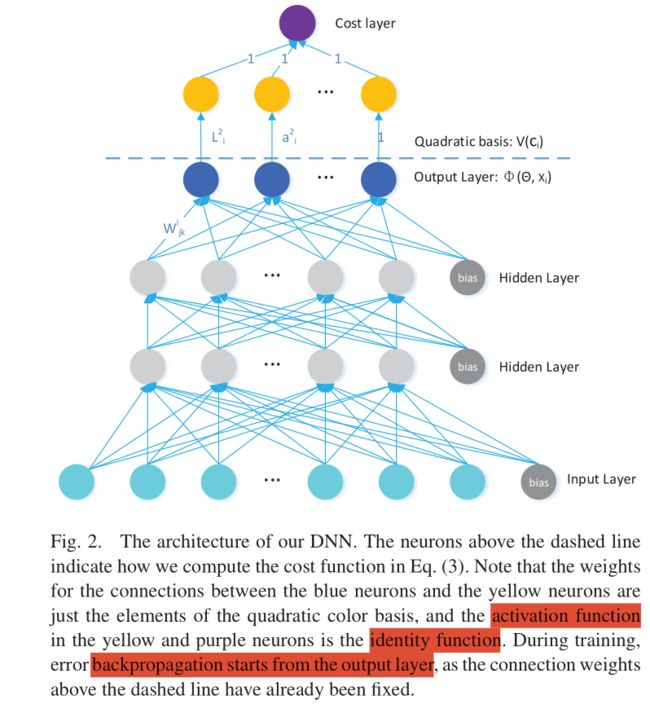
训练模型的输入是我们之前得到的那些描述子,虚线之下的输出是φ(θ,Xv),在我们实验里有30个神经元,把他看为3*10的矩阵,与基向量V(cj)10*1相乘,得到pixel的Lab的值,计算他与真实值的距离——相减的二范数。目标函数就是这个。测试时,输出是像素值。

也就是说,输入到网络中训练的是superPixel那么多个,论文中一张图片7000个。变化的是V(cj),pixel的基向量。
我们测试的时候,选出的也是superpixel中靠近质心的pixel作为输入,得到φ(θ,Xv)这个颜色转换矩阵,对这个superpixel中的所有像素φ(θ,Xv)*V(cj),得到最后颜色值。
然后,我们就大功告成了。
实验部分
实验很多,也很有趣,我们只在这讲两个。
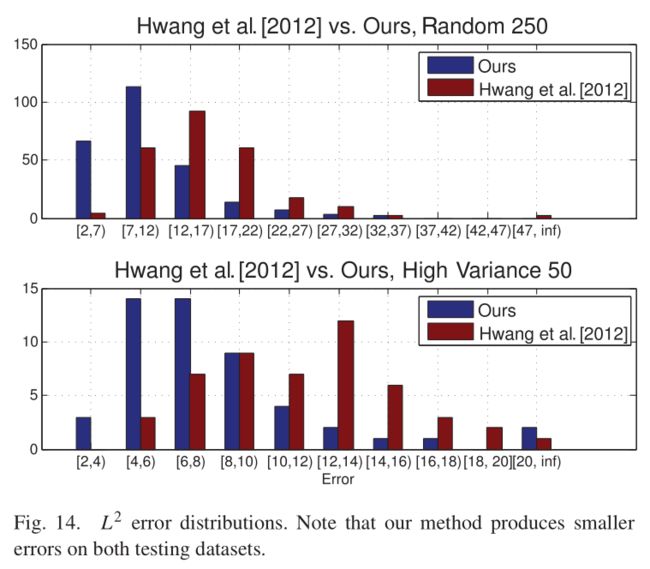
上面的图,两个方法使用相同的数据集,横坐标是像素点L2错误直方图。随机选择250张图的那个直方图,我们的方法出现2-3个错误的图片个数是60多,7--12个错误的有大概110个,我们可以看出,我们的方法出现少量错误的图片占据大部分。
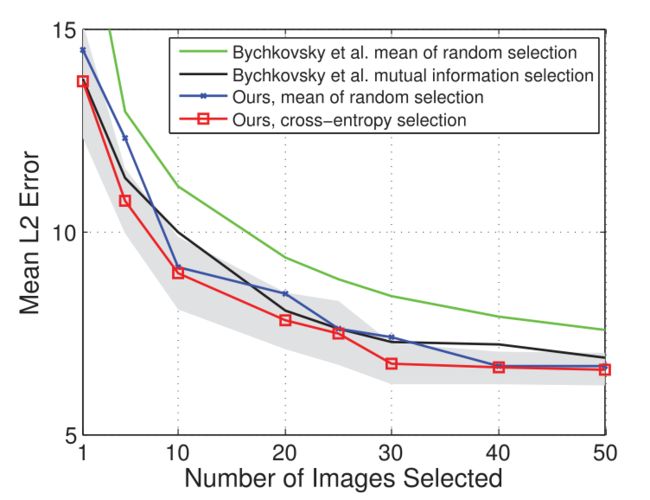
图中,我们可以获取两个信息,选择图片张数超过50张的时候,L2错误不再减少。在选取少量图片的时候,比如10张,我们的错误率最少。
论文讲完了,巨累,该跑实验了,理解的不对的地方欢迎指正。
实验详细介绍:
比较坑的是,实验中中没有给如何选有代表性的图片和如何选有代表性的点,木有办法拿自己的图片在他给的代码里实现
Automatic Photo Adjustment Using Deep Neural Networks 论文实验
Automatic Photo Adjustment Using Deep Neural Networks 论文实验训练测试部分