经典DNN论文简读:AlexNet、VGGNet、GooLeNet、ResNet
本文主要介绍四种经典的卷积神经网络,分别是AlexNet、VGGNet、GooLeNet、ResNet,这四种网络都是为了图像分类而设计,而且其分别获得ILSVRC比赛分类项目2012年冠军、2014年亚军、2014年冠军、2015年冠军。这四个网络算是卷积神经网络最经典的四个网络框架,其中包含着许多影响深远的新技术和新结构,网络的深度也逐步的加深,对本文主要简单介绍着四种网络框架,以及各自的创新之处。
1、AlexNet
原文:click here:ImageNet Classification with Deep Convolutional Neural Networks
这篇文章的网络是在2012年的ImageNet竞赛中取得冠军的一个模型整理后发表的文章。作者是多伦多大学的Alex Krizhevsky等人。Alex Krizhevsky其实是深度学习三巨头之一、2018年图领奖得主Hinton。
AlexNet主要有8层,其中分为5层卷积层以及3层全连接层,整个网络有六亿多个连接以及有六千万个参数、六十五万个神经元,网络输入为224*224像素的Image,网络框架如下:
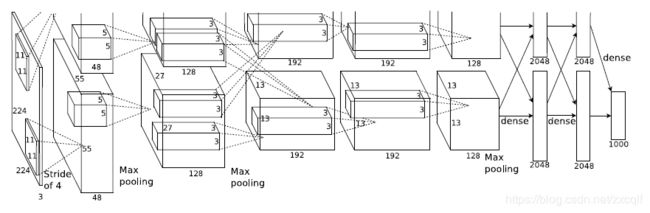
该网络之所以成为经典是因为其首次应用了许多新的技术,例如ReLu、Dropout、MaxPool等等:
- 使用ReLu(Rectified Linear Units)作为卷积层的激活函数
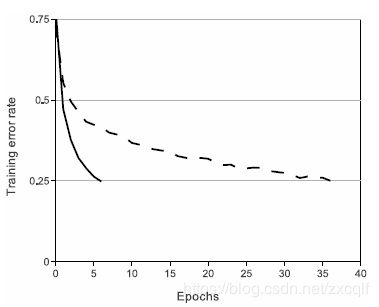
如下图所示,实线为ReLu激活函数,虚线为tanh激活函数由图可以看出,在梯度下降训练时间方面,使用饱和非线性激活函数比非饱和非线性慢得多,采用ReLu作为激活函数的DNN的训练过程要快得多。虽然Relu激活函数在很早之前就已经被提出,但是直到AlexNet的出现才将其发扬光大。同时该激活函数也解决了一直以来采用Sigmoid激活函数存在的梯度弥散的问题,这也为后续深度网络的不断加深做了铺垫。
- LRN层的提出
局部归一化,对局部神经元的活动创建竞争机制,使得其中响应较大的值变得相对更大,并且抑制响应较小的神经元,作者认为这么做可以提高模型的泛化能力,但是这种方法被后续(VGGNet)证明作用其实不大。
- 使用overlapping Pool
在卷积神经网络中采用可重叠的最大池化,此前的神经网络中普遍使用平均池化。最大池化和平均池化的优点在于:其避免了平均池化的模糊化效果,池化层之间的重叠也进一步提升特征的丰富性。
- 为避免过拟合,在训练过程采用数据增强以及Dropout
所谓的数据增强是指,利用当前数据集,通过一些人为的操作,增加训练集的数量,比如说对图像进行切割、旋转、加入噪声等。本文的数据增强主要采用两种方式:生成图像平移和水平反射;改变训练图像中RGB通道的强度。
Dropout操作是指在训练的过程中随机性的让神经元失活,从而促使尽可能多的神经元学习到其更为本质的特征,从而避免模型的过拟合。
2、VGGNet
原文:click here:Very Deep Convolutional Networks for Large-Scale Image Recognition
VGGNet是由牛津大学计算机视觉组参加图像分类竞赛时提出的,VGG即Visual Geometry Group,VGGNet相对于AlexNet来说,其在深度上翻了一番,最深可达19层,所以叫做Very Deep,但是和ResNet比起来,这个深度简直小儿科。
插播一条,我很认同GooLeNet论文中的一句话想要改善DNN的最直接的方法就是增加网络的size,有两种方式,一种是增加网络的深度,比如增加网络层数;另一种是增加网络的宽度,如单层的神经元数目等;本文VGGNet就是以增加网络深度来实现分类精度的提升。VGGNet框图如下:
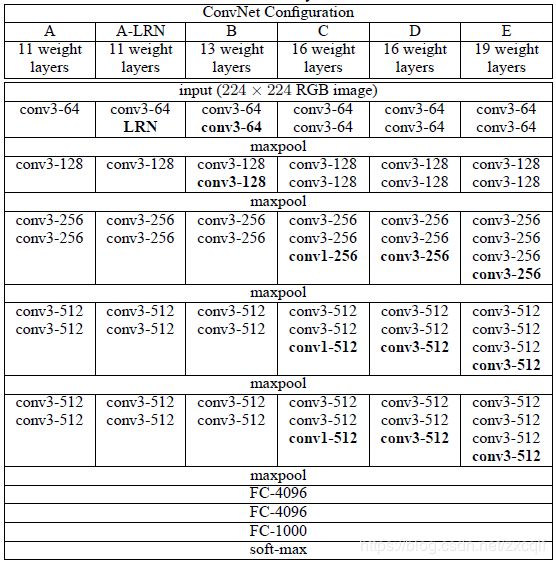
该网络主要分为5段卷积层+3个全连接层组成,之所以说是“5段”,可以通过上表也可以看出来,VGGNet的网络结构类似于AlexNet(5卷积层+3全连接层),只不过VGGNet的卷积采用的是类似于封装好的多次卷积操作作为1个卷积段,共五段。为什么要采取这种操作?因为作者认为对于卷积操作来说,5*5卷积核的卷积层效果相当于2个3*3卷积核的卷积层,7*7卷积核的卷积层效果相当于3个3*3卷积核的卷积层,及通过小卷积核的多次卷积操作实现类似大卷积核对更大区域特征提取效果。
这么替换有什么好处?首先多个卷积层的串联使得卷积网络对特征的学习能力更强;其次这也减少了参数的数量,3*3*3<7*7;当然,我觉得最重要的是其通过减小卷积核,增加卷积层数,使得非线性激活函数的使用次数增加(非线性激活函数使用次数增加了2-3倍),使得网络的非线性增强,这也是增加1*1卷积层的主要原因。
论文在此基础上设计了A~E 5中网络框架,证明了:
- LRN层的作用其实不大;
- 越深的网络效果相对来说越好;
- 3*3的卷积核优于1*1,因为其可学习更大空间的特征。
3、GooLeNet
原文:click here:Going deeper with convolutions
如题目所说,该网络的一大特点是“更深”,该网络框架的网络层数达到了22层,同时该网络的另一大特点是虽然层数更多了但是参数量更少,只有大概五百万的参数数量。
GooLeNet ,这个名字也可以看出其对于卷积网络的开山之作LeNet的慢慢敬意,该网络基本特点总结如下:
- 模型更深,表达能力更强;
- 去除全连接层而是利用全局平均池化,将最终维度变为1*1;
- 设计Inception Module,提高参数的利用率。
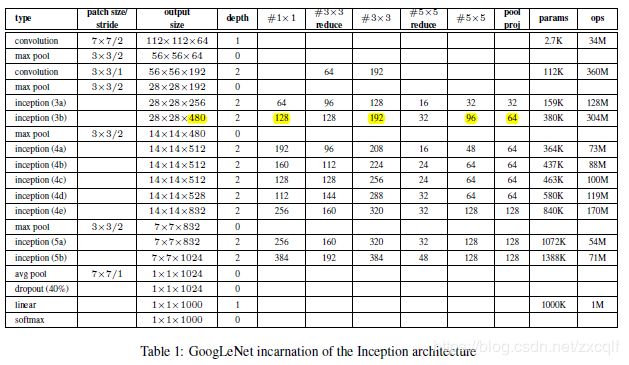
网络框架如下图:
Inception Module:
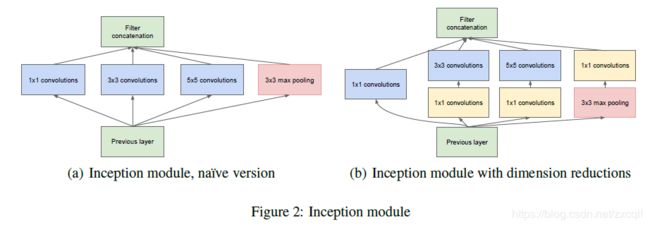
我的理解是,这么做的好处在于,即增加了网络的深度(类似于VGGNet卷积段操作),由增加了网络的宽度。这一部分是借鉴了NIN的思想,总的来说就是Inception Module就类似于大网络中的小网络,其结构可以反复的堆叠在一起形成大网络,但他和NIN相比优点在于增加了分支。之前的网络宽度增加主要是通过增加网络层的通道数,这么做一大缺点是计算量加大同时容易过拟合;此外一个通道对应一个卷积核,每一个卷积核又只能提取一种特征,所以一个通道只能做一种特征处理。
再看Inception Module,这么 做好处在于其拥有更强的能力,允许在输出通道之间进行信息组合,所以效果更明显。看(b)网络结构:四个分支都用到了1*1卷积进行低成本的跨通道特征变化;第二和第三分支先进行1*1卷积,后进行3*3或者5*5卷积,相当于两次特征变换;第四个分支先进行3*3最大池化操作后进行1*1卷积操作。不同尺寸的卷积以及最大池化增加了网络对不同尺度的适应性。最后四个分支通过聚合操作合并(在通道数维度上聚合)。
此外通过表格网络框架,我们可以看出,越靠后,3*3和5*5这两个大面积卷积核的占比越来越大,这是因为作者希望越靠后,其可以捕捉更高阶的抽象特征。
4、ResNet
原文:click here:Deep Residual Learning for Image Recognition
这篇论文就比较强了,首先对于网络深度来说,其可以达到逆天的152层,其次ResNet网络还获得2016 CVPR best paper,获得了ILSVRC2015的分类任务第一名,足见其性能的强悍。文章的卓越之处也就是目前很对网络中都引入了的Skip connection.
都知道神经网络的深度对于其性能的提升至关重要,但是为什么之前没有人无脑增加网络深度呢?因为一味的增加网络深度会出现很多的问题,网络层数越多越深其训练难度就越大,其次还面临着梯度消散以及梯度爆炸等问题。ResNet 借鉴了发明LSTM网络的Schmidhuber教授提出的Highway Network,网络中的skip connection就像是一条信息的告诉公路,直接将前段的信息传输到后层,避免了由于网络深度增加造成的信息损失。此外网络深度的增加会出现Degradation问题,即网络准确率会先上升达到饱和,再持续增加深度的话会导致精度不升反降。
基本原理如图:
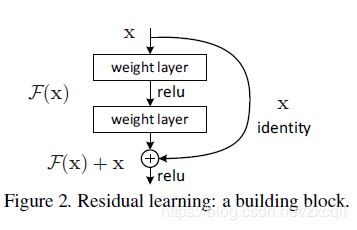
这么设计的优点在于传统的卷积层或者全连接层串联,在信息传递时或多或少会存在着信息损耗,ResNet这种连接方式,将输入信息绕道直接送到输出,保证了信息的完整性。
基本公式(每个block):
H(x) = F(x) + x
对于输入x 与block输出H(x) 同维度的情况下,H(x) = F( x, {Wi}) + x
对于输入x 与block输出H(x) 不同维度的情况下,H(x) = F( x, {Wi}) + Ws * x , Ws为线性映射,将x与H(x)同维度。
至此,这几个经典的神经网络算是有多了解了