一、概述
函数装饰器用于在源码中“标记”函数,以某种方式增加函数的行为。这是一项强大的功能,但是若想要掌握,必须理解闭包。
除了在装饰器中有用处之外,闭包还是回调异步编程和函数式编程风格的基础。
二、装饰器的基础知识
装饰器是可调用的对象,其参数是另一函数(被装饰的函数)。
假如有一个名为decorate的装饰器
@decorate
def target**():
print('runing target()')
上述代码的效果与下述写法一样:
def target():
print('running target()')
target = decorate(target)
两个代码执行完之后的结果都为decorate(target)返回的内容。
使用装饰器把函数替换成另一个函数
定义一个装饰器deco返回inner函数对象
使用deco装饰target
def deco(func):
def inner():
print('running inner()')
return inner
@deco
def target():
print('running target()')
下面进行结果输出:
调用被装饰的target其实会运行inner
>>> target()
running inner()
>>> print(target)
.inner at 0x104549510>
三、Python何时执行装饰器
装饰器的一个关键特性是,它们在被装饰的函数定义之后立即运行。这通常是在导入时(即Python加载模块时)
registry = []
def register(func):
print('running register(%s)'%func)
registry.append(func)
return func
@register
def f1():
print('running f1()')
@register
def f2():
print('running f2()')
def f3():
print('running f3()')
if __name__ == '__main__':
print('----running----')
print('registry ->',registry)
f1()
f2()
f3()
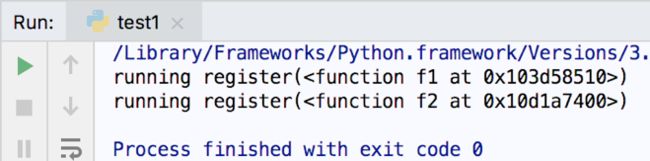
执行结果如下:
running register(
running register(
----running----
registry -> [
running f1()
running f2()
running f3()
从结果可以看出,register在模块中其他函数之前运行了两次。调用register时,传给他的参数是被装饰的函数,例如
在其他文件中导入的话可看到结果
>>> test.registry
[, ]
综上所述:函数装饰器在导入模块时立即执行,而被装饰的函数只在明确调用时运行。
四、使用装饰器改进“策略”模式
定义一个装饰器promotion用于给列表promos存储内容。
充分利用了装饰器的执行顺序。
优点:
促销策略中无需使用特殊的名称表示(一般用_promo结尾表示为折扣策略)
@promotion装饰器突出了被装饰的函数的作用,便于临时禁用某个促销策略,只需要把装饰器注释掉
促销折扣策略可用在其他模块中定义,只需要使用@promotion装饰即可。
promos = []
def promotion(promo_func):
promos.append(promo_func)
return promo_func
@promotion
def fidelity(order):
'''为积分1000或以上的顾客提供5%的折扣'''
return order.total() * 0.5 if order.customer.fidelity >= 1000 else 0
@promotion
def bulk_item(order):
'''单个商品20个或以上时提供10%的折扣'''
discount = 0
for item in order.cart:
if item.quantity >= 20:
discount += item.total() * .1
return discount
@promotion
def large_order(order):
'''订单中的不同商品达到10个或以上的时候提供4%的折扣'''
distinct_items = {item.product for item in order.cart}
if len(distinct_items) >= 10:
return order.total() * .04
return 0
def best_promo(order):
'''选择可用的最佳折扣'''
return max(promo(order) for promo in promos)
五、实现一个简单的装饰器
一个简单的装饰器,输出函数的运行时间
import time
def clock(func):
def clocked(*args): # 接受任意个定位参数
t0 = time.perf_counter() # 返回系统运行时间
result = func(*args)
elapsed = time.perf_counter() - t0
name = func.__name__
arg_str = ','.join(repr(arg) for arg in args)
print('[%0.8fs]%s(%s) -> %r' % (elapsed, name, arg_str, result))
return result
return clocked
该函数实现了
记录出事时间t0
调用传入的函数保存结果
计算经过的时间
格式化收集的数据,然后打印出来
返回第二步保存的结果
装饰器的典型行为:把装饰的函数替换成为新函数,二者接受相同的参数,而且(通常)返回被装饰的函数本该返回的值,同时还会做一些额外操作。
import time
from test import clock
@clock
def snooze(seconds):
time.sleep(seconds)
@clock
def factorial(n):
'''doc test'''
return 1 if n < 2 else n * factorial(n - 1)
if __name__ == '__main__':
print('*' * 20, 'Calling snooze(.123)')
snooze(.123)
print('*' * 20, 'Calling factorial(6)')
print('6 != ', factorial(6))
结果:
******************** Calling snooze(.123)
[0.12652330s]snooze(0.123) -> None
******************** Calling factorial(6)
[0.00000174s]factorial(1) -> 1
[0.00003119s]factorial(2) -> 2
[0.00007065s]factorial(3) -> 6
[0.00008813s]factorial(4) -> 24
[0.00010634s]factorial(5) -> 120
[0.00017910s]factorial(6) -> 720
6 != 720
但是会发现我们无法看到被装饰的函数的name和doc属性
print(factorial.__doc__)# None
print(factorial.__name__)# clocked
所以对上文中的clock进行一定的修改,使其支持关键字还有name和doc属性
import time
import functools
def clock(func):
@functools.wraps(func)
def clocked(*args, **kwargs):
t0 = time.time()
result = func(*args, **kwargs)
elapsed = time.time() - t0
name = func.__name__
arg_lst = []
if args:
arg_lst.append(','.join(repr(arg) for arg in args))
if kwargs:
pairs = ['%s=%r' % (k, w) for k, w in sorted(kwargs.items())]
arg_lst.append(','.join(pairs))
arg_str = ','.join(arg_lst)
print('[%0.8fs]%s(%s) -> %r' % (elapsed, name, arg_str, result))
return result
return clocked
六、functools.lru_cache
functools.lru_cache实现了备忘功能,它能把耗时的函数的结果保存起来,避免传入相同的参数时重复计算
使用常规思路写一个斐波纳切数
from test import clock
@clock
def fibonacci(n):
if n < 2:
return n
return fibonacci(n - 2) + fibonacci(n - 1)
if __name__ == '__main__':
print(fibonacci(6))
结果如下:
[0.00000000s]fibonacci(0) -> 0
[0.00000000s]fibonacci(1) -> 1
[0.00004888s]fibonacci(2) -> 1
[0.00000119s]fibonacci(1) -> 1
[0.00000000s]fibonacci(0) -> 0
[0.00000000s]fibonacci(1) -> 1
[0.00001693s]fibonacci(2) -> 1
[0.00003314s]fibonacci(3) -> 2
[0.00010300s]fibonacci(4) -> 3
[0.00000095s]fibonacci(1) -> 1
[0.00000000s]fibonacci(0) -> 0
[0.00000000s]fibonacci(1) -> 1
[0.00001621s]fibonacci(2) -> 1
[0.00003195s]fibonacci(3) -> 2
[0.00000095s]fibonacci(0) -> 0
[0.00000000s]fibonacci(1) -> 1
[0.00001597s]fibonacci(2) -> 1
[0.00000000s]fibonacci(1) -> 1
[0.00000095s]fibonacci(0) -> 0
[0.00000095s]fibonacci(1) -> 1
[0.00001597s]fibonacci(2) -> 1
[0.00003219s]fibonacci(3) -> 2
[0.00006509s]fibonacci(4) -> 3
[0.00011182s]fibonacci(5) -> 5
[0.00023007s]fibonacci(6) -> 8
8
可以看出,除了最后一行,其余输出都是clock装饰器生成的。fibonacci(1)调用了8次,fibonacci(2)调用了5次。
下面使用lru_cache()
from test import clock
import functools
@functools.lru_cache()
@clock
def fibonacci(n):
if n < 2:
return n
return fibonacci(n - 2) + fibonacci(n - 1)
if __name__ == '__main__':
print(fibonacci(6))
结果:
[0.00000000s]fibonacci(0) -> 0
[0.00000000s]fibonacci(1) -> 1
[0.00005698s]fibonacci(2) -> 1
[0.00000095s]fibonacci(3) -> 2
[0.00008106s]fibonacci(4) -> 3
[0.00000095s]fibonacci(5) -> 5
[0.00010085s]fibonacci(6) -> 8
8
可以看出,n的每个值只调用一次函数
@functools.lru_cache(maxsize=128,typed=False)
lru_cache还要两个参数可以调用:
maxsize表示抗议存储多少个调用的结果;
typed表示是否把不同参数类型得到的结果分开保存;
七、functools.singledispatch
首先看一个简单的函数
import html
def htmlize(obj):
content = html.escape(repr(obj))
return '{}'.format(content)
html.escape的作用的是把html文件中的特殊字符(&,<,>,",'等)转换为HTML-safe字符。现在想要对这个函数做一个扩展
·str:把内部的换行符替换为‘
\n’,不使用
使用·int:以十进制和十六进制显示数字
·list:输出一个HTML列表,根据各个元素的类型进行格式化
对于这个需求的解决思路一般是用一长串的if/elif/elif来调用专门的函数解决(当判断输入的内容为str的时候调用例如htmlize_str的方法)。这样不便于模块的拓展,时间一长,htmlize会变得很大,而且与各个专门函数之间的耦合也很紧密。
Python3.4新增的functools.singledispatch装饰器可以把整体方案拆分成多个模块。使用它装饰的普通函数会变成泛函数:根据第一个参数的类型,以不同方式执行相同操作的一组函数。
import html import numbers from collections import abc from functools import singledispatch @singledispatch def htmlize(obj): content = html.escape(repr(obj)) return '{}'.format(content) @htmlize.register(str) def _(text): content = html.escape(text).replace('\n', '
\n') return '{}
'.format(content) @htmlize.register(numbers.Integral) def _(n): return '{0} (0x{0:x})'.format(n) @htmlize.register(tuple) @htmlize.register(abc.MutableSequence) def _(seq): inner = '\n'.join(htmlize(item) for item in seq) return ' \n
' if __name__ == '__main__': print(htmlize({1, 2, 3})) print(htmlize(abs)) print(htmlize('Heimlich & Co.\n- a game')) print(htmlize(42)) print(htmlize(['alpha', 66, {3, 2, 1}])) 结果:- ' + inner + '
\n{1, 2, 3}<built-in function abs>Heimlich & Co.
- a game42 (0x2a)
alpha
{1, 2, 3}@singledispatch标记处理object类型的基函数
各个专门函数使用@《base_function》.register(《type》)装饰
由于专门函数的名称没有意义,所以用下划线_表示
number.Integral是int的虚拟超类,和abc.MutableSequence一样都是抽象基类
最后一个函数表明可以叠放多个register装饰器,让同一个函数支持不同类型
在一个类中为同一个方法定义多个重载变体(def a ,def b,def c),比在一个函数里面使用一长串if/elif/elif块要好。@singledispath的优点是支持模块化扩展,各个模块可以为它支持的各个类型注册一个专门的函数。
八、叠放装饰器
装饰器是函数,所以可以组合起来使用。(在被装饰的函数上应用装饰器)
@d1 @d2 def f(): print('f')上面和下面两者是一样的
def f(): print('f') f = d1(d2(f))九、参数化装饰器
Python把装饰的函数作为第一个参数传递给装饰器函数,如果需要让装饰器接受其他的参数的话,需要创建一个装饰器工厂函数,把参数传递给它,返回一个装饰器,然后再把它应用到要装饰的函数上。将第三章的例子改写一下:
registry = set() def register(active=True): def decorate(func): print('running register(active=%s)->decorate(%s)' % (active, func)) if active: registry.add(func) else: registry.discard(func) return func return decorate @register(active=False) def f1(): print('running f1()') @register() def f2(): print('running f2()') def f3(): print('running f3()')与之前的例子进行对比可以发现decorate这个内部函数是真正的装饰器,它的参数是一个函数,它是一个装饰器,所以必须返回一个函数
register是装饰器工厂函数,因此返回decorate
@register工厂函数必须作为函数调用,并且传入所需的参数,如果有默认值那也需要作为函数调用【@register()】,即要返回真正的装饰器decorate
这个例子的关键是,register()要返回decorate,然后把它应用到被装饰的函数上。
if __name__ == '__main__': print(registry) 图片 3.png
图片 3.png从结果可以看到只有f2加入到了集合中。
装饰器其实就是函数的调用,所以如果不使用@的话
register()(f) register(active=False)(f)修改一下第五章中clock装饰器,给它添加一个功能:让用户输入一个格式化字符串,控制被装饰函数的输出
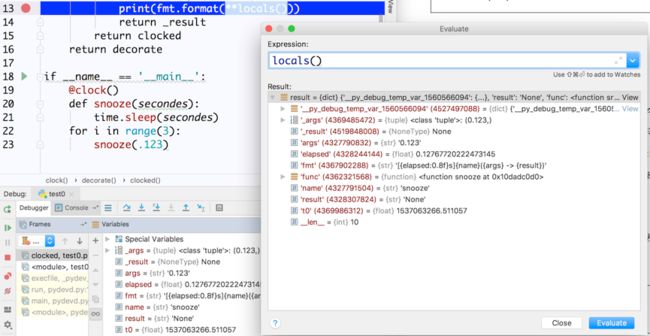
import time DEFAULT_FMT = '[{elapsed:0.8f}s]{name}({args} -> {result})' def clock(fmt=DEFAULT_FMT): def decorate(func): def clocked(*_args): t0 = time.time() _result = func(*_args) elapsed = time.time()-t0 name = func.__name__ args = ','.join(repr(arg) for arg in _args) result = repr(_result) print(fmt.format(**locals())) return _result return clocked return decorate将之前的格式化输出当初默认的参数输入。
clock是参数化装饰器的工厂函数。decorate是真正的装饰器,clocked包装被装饰的函数。
**locals()是为了在fmt中引用clocked的局部变量。
 图片 4.png
图片 4.pngif __name__ == '__main__': @clock() def snooze(secondes): time.sleep(secondes) for i in range(3): snooze(.123)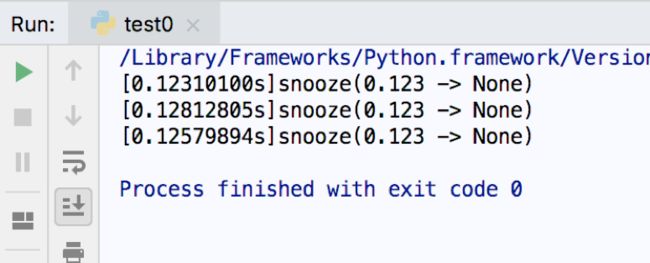 图片 5.png
图片 5.png下面修改下格式化输出的内容:
if __name__ == '__main__': @clock('{name}:{elapsed}s') def snooze(secondes): time.sleep(secondes) for i in range(3): snooze(.123) 图片 6.png
图片 6.pngif __name__ == '__main__': @clock('{name}({args}) dt={elapsed:0.3f}s') def snooze(secondes): time.sleep(secondes) for i in range(3): snooze(.123)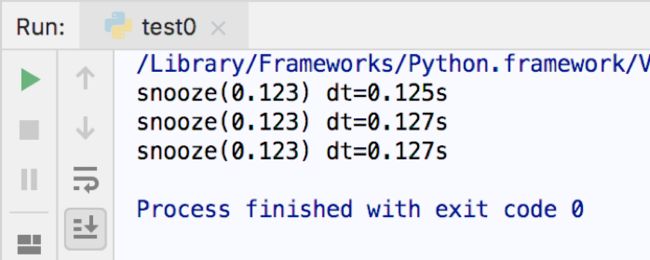 图片 7.png
图片 7.png只要修改的格式化输出的内容包含在clocked的局部变量就可以正常输出了。