取代Python多进程!高性能分布式执行框架 - Berkeley Ray

前言
随着机器学习算法和技术的进步,出现了越来越多需要在多台机器并行计算的机器学习应用。然而,在集群计算设备上运行的机器学习算法目前仍是专门设计的。尽管对于特定的用例而言(如参数服务器或超参数搜索),这些解决方案的效果很好,同时 AI 领域之外也存在一些高质量的分布式系统(如 Hadoop 和 Spark),但前沿开发者们仍然常常需要从头构建自己的系统,这意味着需要耗费大量时间和精力。
例如,应用一个简单概念的算法,如在强化学习中的进化策略(论文《Evolution Strategies as a Scalable Alternative to Reinforcement Learning》)。算法包含数十行伪代码,其中的 Python 实现也并不多。然而,在较大的机器或集群上运行它需要更多的软件工程工作。作者的实现包含了上千行代码,以及必须定义的通信协议、信息序列化、反序列化策略,以及各种数据处理策略。
Ray 的目标之一在于:让开发者可以用一个运行在笔记本电脑上的原型算法,仅需添加数行代码就能轻松转为适合于计算机集群运行的(或单个多核心计算机的)高性能分布式应用。这样的框架需要包含手动优化系统的性能优势,同时又不需要用户关心那些调度、数据传输和硬件错误等问题。
本文对Ray进行介绍,以帮助大家更快地了解Ray是什么,并且与Native Python进行对比。如有描述不当的地方,欢迎不吝指正。
Python高性能分布式执行框架-Ray
- 前言
- 一、Hello, Ray
- 1. 简介
- 2. 性能表现
- 2.1 可扩展性和表现性能
- 2.2 容错性
- 2.3 RL 应用
- 二、WHY: 为何有这么高的性能
- 1. 语言和计算模型
- 1.1 编程模型
- 1.2 计算模型
- 2. 架构
- 3. Ray 高级库
- 3.1 Tune
- 3.2 RLlib
- 3.3 Ray Serve
- 三、Have A TRY
- 1. 简单开始
- 2. 模拟器的虚构示例
- 3. 参数服务器示例
- 四、Ray V.S. Python
- 4.1 Put 和 Get
- 4.2 Ray 中的异步计算
- 4.3 远程功能
- 4.4 表达任务之间的依赖关系
- 4.5 有效地对值进行聚合
- 4.6 从类到actor
- 4.7 actor句柄
一、Hello, Ray
1. 简介
正如前言部分所述,
Ray是UC Berkeley RISELab新推出的高性能分布式执行框架,它使用了和传统分布式计算系统不一样的架构和对分布式计算的抽象方式,具有比Spark更优异的计算性能。Ray是一个基于Python的分布式执行引擎。相同的代码可以在单个机器上运行以实现高效的多处理,并且可以在群集上用于大量的计算。

- 官方链接:https://github.com/ray-project/ray
- 论文链接:https://arxiv.org/pdf/1712.05889.pdf
让我们最后再来看一下分布式执行架构Ray的高性能。如果想看Python的对比,可直接跳过这部分。
2. 性能表现
2.1 可扩展性和表现性能
- 端到端可扩展性。 GCS 的主要优势是增强系统的横向可扩展性。我们可以观察到几乎线性的任务吞吐量增长。在 60 节点,Ray 可以达到超过每秒 100 万个任务的吞吐量,并线性地在 100 个节点上超过每秒 180 万个任务。最右边的数据点显示,Ray 可以在不到一分钟的时间处理 1 亿个任务(54s)。

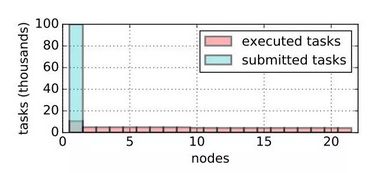
- 全局调度器的主要职责是在整个系统中保持负载平衡。 Driver 在第一个节点提交了 100K 任务,由全局调度器平衡分配给 21 个可用节点。
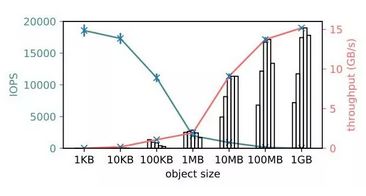
- 对象存储性能。 对于大对象,单一客户端吞吐量超过了 15GB/s(红色),对于小对象,对象存储 IOPS 达到 18K(青色),每次操作时间约 56 微秒。
2.2 容错性
- 从对象失败中恢复。 随着 worker 节点被终结,活跃的局部调度器会自动触发丢失对象重建。在重建期间,driver 最初提交的任务被搁置,因为它们的依赖关系不能满足。但是整体的任务吞吐量保持稳定,完全利用可用资源,直到丢失的依赖项被重建。
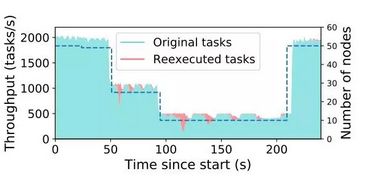
-
分布式任务的完全透明容错。 虚线表示集群中的节点数。曲线显示新任务(青色)和重新执行任务(红色)的吞吐量,到 210s 时,越来越多的节点加回到系统,Ray 可以完全恢复到初始的任务吞吐量。
-
从 actor 失败中恢复。 通过将每个 actor 的方法调用编码到依赖关系图中,我们可以重用同一对象重构机制。

t=200s 时,我们停止 10 个节点中的 2 个,导致集群中 2000 个 actor 中的 400 个需要在剩余节点上恢复。(a)显示的是没有中间节点状态被存储的极端情况。调用丢失的 actor 的方法必须重新串行执行(t = 210-330s)。丢失的角色将自动分布在可用节点上,吞吐量在重建后完全恢复。(b)显示的是同样工作负载下,每 10 次方法调用每个 actor 自动进行了一次 checkpoint 存储。节点失效后,大部分重建是通过执行 checkpoint 任务重建 actor 的状态(t = 210-270s)。
- GCS 复制消耗。 为了使 GCS 容错,我们复制每个数据库碎片。当客户端写入 GCS 的一个碎片时,它将写入复制到所有副本。通过减少 GCS 的碎片数量,我们人为地使 GCS 成为工作负载的瓶颈,双向复制的开销小于 10%。
2.3 RL 应用
我们用 Ray 实现了两种 RL 算法,与专为这两种算法设计的系统进行对比,Ray 可以赶上甚至超越特定的系统。除此之外,使用 Ray 在集群上分布这些算法只需要在算法实现中修改很少几行代码。
- ES 算法(Evolution Strategies)
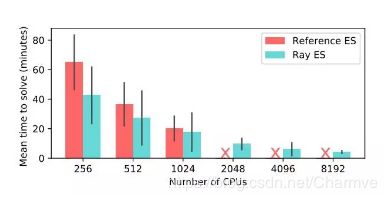
Ray 和参考系统实现 ES 算法在 Humanoid v1 任务上达到 6000 分所需时间对比。
在 Ray 上实现的 ES 算法可以很好地扩展到 8192 核,而特制的系统在 1024 核后便无法运行。在 8192 核上,我们取得了中值为 3.7 分钟的效果,比目前最好效果快两倍。
- PPO 算法(Proximal Policy Optimization)
为了评估 Ray 在单一节点和更小 RL 工作负载的性能,我们在 Ray 上实现了 PPO 算法,与 OpenMPI 实现的算法进行对比。
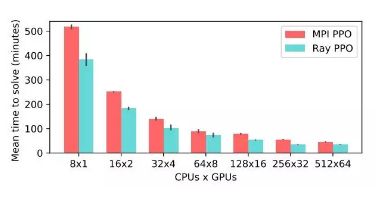
MPI 和 Ray 实现 PPO 算法在 Humanoid v1 任务上达到 6000 分所需时间对比。
用 Ray 实现的 PPO 算法超越了特殊的 MPI 实现,并且使用 GPU 更少。
二、WHY: 为何有这么高的性能
博主青藤木鸟 Muniao’s blog在试用之后,简单总结一下:
- 极简 Python API 接口:在函数或者类定义时加上
ray.remote的装饰器并做一些微小改变,就能将单机代码变为分布式代码。这意味着不仅可以远程执行纯函数,还可以远程注册一个类(Actor模型),在其中维护大量context(成员变量),并远程调用其成员方法来改变这些上下文。 - 高效数据存储和传输:每个节点上通过共享内存(多进程访问无需拷贝)维护了一块局部的对象存储,然后利用专门优化过的 Apache Arrow格式来进行不同节点间的数据交换。
- 动态图计算模型:这一点得益于前两点,将远程调用返回的 future 句柄传给其他的远程函数或者角色方法,即通过远程函数的嵌套调用构建复杂的计算拓扑,并基于对象存储的发布订阅模式来进行动态触发执行。
- 全局状态维护:将全局的控制状态(而非数据)利用 Redis 分片来维护,使得其他组件可以方便的进行平滑扩展和错误恢复。当然,每个 redis 分片通过 chain-replica 来避免单点。
- 去中心化的调度:调度器分散在各个节点上;根据 GCS 拉取全局负载状态信息,然后随机选择一个合乎资源约束的可用节点。
这部分来自作者:青藤木鸟 Muniao’s blog 转载请注明出处
当然,还有一些需要优化的地方,比如 Job 级别的封装(以进行多租户资源配给),待优化的垃圾回收算法(针对对象存储,现在只是粗暴的 LRU),多语言支持(最近支持了Java,但不知道好不好用)等等。但是瑕不掩瑜,其架构设计和实现思路还是有很多可以借鉴的地方。
1. 语言和计算模型
Ray 实现了动态任务图计算模型,即:Ray 将应用建模为一个在运行过程中动态生成依赖的任务图。在此模型之上,Ray 提供了角色模型(Actor) 和 并行任务模型(task-parallel) 的编程范式。Ray 对混合计算范式的支持使其有别于与像 CIEL 一样只提供并行任务抽象和像 Orleans 或 Akka 一样只提供角色模型抽象的系统。
1.1 编程模型
- 任务模型(Tasks)
一个任务表示一个在无状态工作进程执行的远程函数(remote function)。当一个远程函数被调用的时候,表示任务结果的 future 会立即被返回(也就是说所有的远程函数调用都是异步的,调用后会立即返回一个任务句柄)。可以将 Futures传给 ray.get() 以阻塞的方式获取结果,也可以将 Futures 作为参数传给其他远程函数,以非阻塞、事件触发的方式进行执行(后者是构造动态拓扑图的精髓)。Futures 的这两个特性让用户在构造并行任务的同时指定其依赖关系。下表是 Ray 的所有 API(相当简洁而强大,但是实现起来会有很多坑,毕竟所有装饰有 ray.remote 的函数或者类及其上下文都要序列化后传给远端节点,序列化用的和 PySpark 一样的 cloudpickle)。

远程函数作用于不可变的物体上,并且应该是无状态的并且没有副作用的:这些函数的输出仅取决于他们的输入(纯函数)。这意味着幂等性(idempotence),获取结果出错时只需要重新执行该函数即可,从而简化容错设计。
- 角色模型(Actors)
一个角色对象代表一个有状态的计算过程。每个角色对象暴露了一组可以被远程调用,并且按调用顺序依次执行的成员方法(即在同一个角色对象内是串行执行的,以保证角色状态正确的进行更新)。一个角色方法的执行过程和普通任务一样,也会在远端(每个角色对象会对应一个远端进程)执行并且立即返回一个 future;但不同的是,角色方法会运行在一个有状态(stateful)的工作进程上。一个角色对象的句柄(handle)可以传递给其他角色对象或者远程任务,从而使他们能够在该角色对象上调用这些成员函数。

表2 比较了任务模型和角色模型在不同维度上的优劣。任务模型利用集群节点的负载信息和依赖数据的位置信息来实现细粒度的负载均衡,即每个任务可以被调度到存储了其所需参数对象的空闲节点上;并且不需要过多的额外开销,因为不需要设置检查点和进行中间状态的恢复。与之相比,角色模型提供了极高效的细粒度的更新支持,因为这些更新作用在内部状态(即角色成员变量所维护的上下文信息)而非外部对象(比如远程对象,需要先同步到本地)。后者通常来说需要进行序列化和反序列化(还需要进行网络传输,因此往往很费时间)。例如,角色模型可以用来实现参数服务器(parameter servers)和基于GPU 的迭代式计算(如训练)。此外,角色模型可以用来包裹第三方仿真器(simulators)或者其他难以序列化的对象(比如某些模型)。
为了满足异构性和可扩展性,我们从三个方面增强了 API 的设计。首先,为了处理长短不一的并发任务,我们引入了 ray.wait() ,它可以等待前 k 个结果满足了就返回;而不是像 ray.get() 一样,必须等待所有结果都满足后才返回。其次,为了处理对不同资源纬度( resource-heterogeneous)需求的任务,我们让用户可以指定所需资源用量(例如装饰器:ray.remote(gpu_nums=1)),从而让调度系统可以高效的管理资源(即提供一种交互手段,让调度系统在调度任务时相对不那么盲目)。最后,为了提灵活性,我们允许构造嵌套远程函数(nested remote functions),意味着在一个远程函数内可以调用另一个远程函数。这对于获得高扩展性是至关重要的,因为它允许多个进程以分布式的方式相互调用(这一点是很强大的,通过合理设计函数,可以使得可以并行部分都变成远程函数,从而提高并行性)。
1.2 计算模型
Ray 采用的动态图计算模型,在该模型中,当输入可用(即任务依赖的所有输入对象都被同步到了任务所在节点上)时,远程函数和角色方法会自动被触发执行。在这一小节,我们会详细描述如何从一个用户程序(图3)来构建计算图(图4)。该程序使用了表1 的API 实现了图2 的伪码。
@ray.remote
def create_policy():
# Initialize the policy randomly. return policy
@ray.remote(num_gpus=1)
class Simulator(object):
def __init__(self):
# Initialize the environment. self.env = Environment()
def rollout(self, policy, num_steps):
observations = []
observation = self.env.current_state()
for _ in range(num_steps):
action = policy(observation)
observation = self.env.step(action)
observations.append(observation)
return observations
@ray.remote(num_gpus=2)
def update_policy(policy, *rollouts):
# Update the policy.
return policy
@ray.remote
def train_policy():
# Create a policy.
policy_id = create_policy.remote()
# Create 10 actors.
simulators = [Simulator.remote() for _ in range(10)] # Do 100 steps of training.
for _ in range(100):
# Perform one rollout on each actor.
rollout_ids = [s.rollout.remote(policy_id)
for s in simulators]
# Update the policy with the rollouts.
policy_id =
update_policy.remote(policy_id, *rollout_ids)
return ray.get(policy_id)
图3:在 Ray 中实现图2逻辑的代码,注意装饰器 @ray.remote 会将被注解的方法或类声明为远程函数或者角色对象。调用远程函数或者角色方法后会立即返回一个 future 句柄,该句柄可以被传递给随后的远程函数或者角色方法,以此来表达数据间的依赖关系。每个角色对象包含一个环境对象 self.env ,这个环境状态为所有角色方法所共享。
在不考虑角色对象的情况下,在一个计算图中有两种类型的点:数据对象(data objects)和远程函数调用(或者说任务)。同样,也有两种类型的边:数据边(data edges)和控制边(control edges)。数据边表达了数据对象任务间的依赖关系。更确切来说,如果数据对象 D 是任务 T 的输出,我们就会增加一条从 T 到 D 的边。类似的,如果 D是 任务 T 的输入,我们就会增加一条 D 到 T 的边。控制边表达了由于远程函数嵌套调用所造成的计算依赖关系,即,如果任务 T1 调用任务 T2, 我们就会增加一条 T1 到 T2 的控制边。
在计算图中,角色方法调用也被表示成了节点。除了一个关键不同点外,他们和任务调用间的依赖关系基本一样。为了表达同一个角色对象上的连续方法调用所形成的状态依赖关系,我们向计算图添加第三种类型的边:在同一个角色对象上,如果角色方法 Mj 紧接着 Mi 被调用,我们就会添加一条 Mi 到 Mj 的状态边(即 Mi 调用后会改变角色对象中的某些状态,或者说成员变量;然后这些变化后的成员变量会作为 Mj 调用的隐式输入;由此,Mi 到 Mj 间形成了某种隐式依赖关系)。这样一来,作用在同一角色对象上的所有方法调用会形成一条由状态边串起来的调用链(chain,见图4)。这条调用链表达了同一角色对象上方法被调用的前后相继的依赖关系。
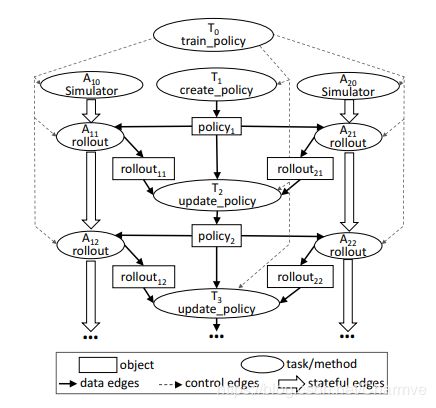
图3:该图与图4 train_policy.remote() 调用相对应。远程函数调用和角色方法调用对应图中的任务(tasks)。该图中显示了两个角色对象A10和A20,每个角色对象的方法调用(被标记为 A1i 和 A2i 的两个任务)之间都有状态边(stateful edge)连接,表示这些调用间共享可变的角色状态。从 train_policy 到被其调用的任务间有控制边连接。为了并行地训练多种策略,我们可以调用 train_policy.remote()多次。
状态边让我们将角色对象嵌入到无状态的任务图中,因为他们表达出了共享状态、前后相继的两个角色方法调用之间的隐式数据依赖关系。状态边的添加还可以让我们维护谱系图(lineage),如其他数据流系统一样,我们也会跟踪数据的谱系关系以在必要的时候进行数据的重建。通过显式的将状态边引入数据谱系图中,我们可以方便的对数据进行重建,不管这些数据是远程函数产生的还是角色方法产生的(小节4.2.3中会详细讲)。
2. 架构
Ray是使用什么样的架构对分布式计算做出如上抽象的呢?下图给出了Ray的系统架构。(来自Ray论文,Click here)
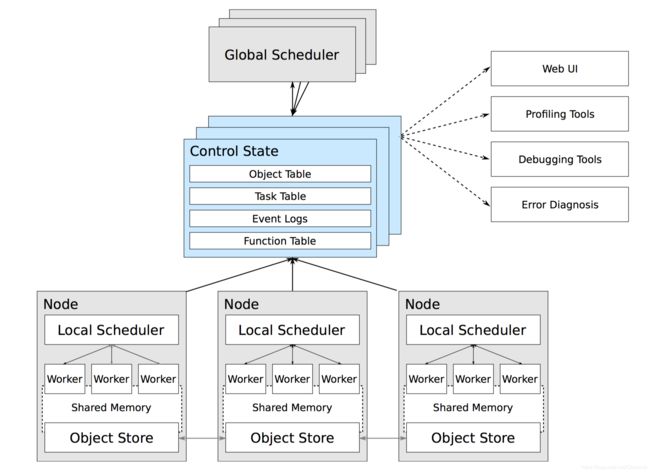
作为分布式计算系统,Ray仍旧遵循了典型的Master-Slave的设计:Master负责全局协调和状态维护,Slave执行分布式计算任务。不过和传统的分布式计算系统不同的是,Ray使用了混合任务调度的思路。在集群部署模式下,Ray启动了以下关键组件:
- GlobalScheduler: Master上启动了一个全局调度器,用于接收本地调度器提交的任务,并将任务分发给合适的本地任务调度器执行。
- RedisServer: Master上启动了一到多个RedisServer用于保存分布式任务的状态信息(ControlState),包括对象机器的映射、任务描述、任务debug信息等。
- LocalScheduler: 每个Slave上启动了一个本地调度器,用于提交任务到全局调度器,以及分配任务给当前机器的Worker进程。
- Worker: 每个Slave上可以启动多个Worker进程执行分布式任务,并将计算结果存储到ObjectStore。
- ObjectStore: 每个Slave上启动了一个ObjectStore存储只读数据对象,Worker可以通过共享内存的方式访问这些对象数据,这样可以有效地减少内存拷贝和对象序列化成本。ObjectStore底层由Apache Arrow实现。
- Plasma(现在改名为arrow):每个Slave上的ObjectStore都由一个名为Plasma的对象管理器进行管理,它可以在Worker访问本地ObjectStore上不存在的远程数据对象时,主动拉取其它Slave上的对象数据到当前机器。
需要说明的是,Ray的论文中提及,全局调度器可以启动一到多个,而目前Ray的实现文档里讨论的内容都是基于一个全局调度器的情况。我猜测可能是Ray尚在建设中,一些机制还未完善,后续读者可以留意此处的细节变化。
Ray的任务也是通过类似Spark中Driver的概念的方式进行提交的,有所不同的是:
- Spark的Driver提交的是任务DAG,一旦提交则不可更改。
- 而Ray提交的是更细粒度的remote function,任务DAG依赖关系由函数依赖关系自由定制。
论文给出的架构图里并未画出Driver的概念,因此我在其基础上做了一些修改和扩充。
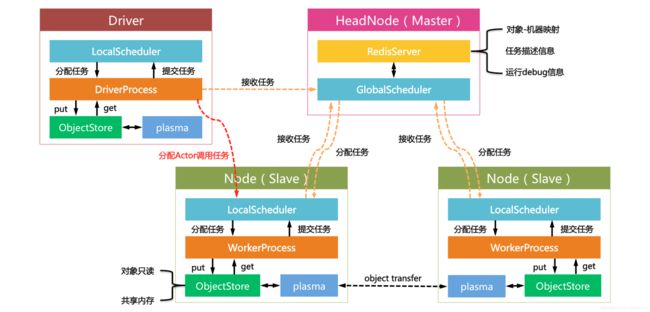
Ray的Driver节点和和Slave节点启动的组件几乎相同,不过却有以下区别:
- Driver上的工作进程DriverProcess一般只有一个,即用户启动的PythonShell。Slave可以根据需要创建多个WorkerProcess。
- Driver只能提交任务,却不能接收来自全局调度器分配的任务。Slave可以提交任务,也可以接收全局调度器分配的任务。
- Driver可以主动绕过全局调度器给Slave发送Actor调用任务(此处设计是否合理尚不讨论)。Slave只能接收全局调度器分配的计算任务。
3. Ray 高级库
- Tune: Scalable Hyperparameter Tuning 可伸缩超参数调整
- RLlib: Scalable Reinforcement Learning 可扩展的强化学习
- RaySGD: Distributed Training Wrappers 分布式培训包装
- Ray Serve: Scalable and Programmable Serving 可扩展和可编程服务
3.1 Tune
Tune是用于任何规模的超参数调整的库。
- 用不到10行代码启动多节点分布式超参数扫描。
- 支持任何深度学习框架,包括PyTorch,PyTorch Lightning,TensorFlow和Keras。
- 使用TensorBoard可视化结果。
- 在可扩展的SOTA算法中进行选择,例如基于人口的培训(PBT),Vizier的中值停止规则,HyperBand / ASHA。
- Tune与许多优化库(例如Facebook Ax,HyperOpt和贝叶斯优化)集成在一起,可以透明地扩展它们。
下面的这个例子,运行并行网格搜索以优化示例目标函数。要运行这个例子,先执行以下这条指令。
$ pip install ray[tune]
from ray import tune
def objective(step, alpha, beta):
return (0.1 + alpha * step / 100)**(-1) + beta * 0.1
def training_function(config):
# Hyperparameters
alpha, beta = config["alpha"], config["beta"]
for step in range(10):
# Iterative training function - can be any arbitrary training procedure.
intermediate_score = objective(step, alpha, beta)
# Feed the score back back to Tune.
tune.report(mean_loss=intermediate_score)
analysis = tune.run(
training_function,
config={
"alpha": tune.grid_search([0.001, 0.01, 0.1]),
"beta": tune.choice([1, 2, 3])
})
print("Best config: ", analysis.get_best_config(metric="mean_loss"))
# Get a dataframe for analyzing trial results.
df = analysis.dataframe()
如果已安装TensorBoard,则自动显示所有试用结果:
tensorboard --logdir ~/ray_results
3.2 RLlib
RLlib是在Ray之上构建的用于增强学习的开源库,它为各种应用程序提供高可伸缩性和统一的API。
pip install tensorflow # or tensorflow-gpu
pip install ray[rllib] # also recommended: ray[debug]
import gym
from gym.spaces import Discrete, Box
from ray import tune
class SimpleCorridor(gym.Env):
def __init__(self, config):
self.end_pos = config["corridor_length"]
self.cur_pos = 0
self.action_space = Discrete(2)
self.observation_space = Box(0.0, self.end_pos, shape=(1, ))
def reset(self):
self.cur_pos = 0
return [self.cur_pos]
def step(self, action):
if action == 0 and self.cur_pos > 0:
self.cur_pos -= 1
elif action == 1:
self.cur_pos += 1
done = self.cur_pos >= self.end_pos
return [self.cur_pos], 1 if done else 0, done, {}
tune.run(
"PPO",
config={
"env": SimpleCorridor,
"num_workers": 4,
"env_config": {"corridor_length": 5}})
3.3 Ray Serve
Ray Serve是基于Ray构建的可伸缩模型服务库, 它有以下特点:
- 框架不可知(Framework Agnostic):使用相同的工具包即可提供服务,从使用PyTorch或Tensorflow&Keras等框架构建的深度学习模型到Scikit-Learn模型或任意业务逻辑。
- Python优先(Python First):使用纯Python代码配置服务的模型-不再需要YAML或JSON配置。
- 面向性能(Performance Oriented):启用批处理,流水线处理和GPU加速,以提高模型的吞吐量。
- 本机组合(Composition Native):允许您将多个模型组合在一起以创建单个预测,从而创建“模型管道”。
- 水平可扩展(Horizontally Scalable):服务可以随着您添加更多计算机而线性扩展。 使您的基于ML的服务能够处理不断增长的流量。
下面这个示例运行一个scikit-learn梯度提升分类器。在运行前需要执行以下语句:
$ pip install scikit-learn
$ pip install "ray[serve]"
from ray import serve
import pickle
import requests
from sklearn.datasets import load_iris
from sklearn.ensemble import GradientBoostingClassifier
# Train model
iris_dataset = load_iris()
model = GradientBoostingClassifier()
model.fit(iris_dataset["data"], iris_dataset["target"])
# Define Ray Serve model,
class BoostingModel:
def __init__(self):
self.model = model
self.label_list = iris_dataset["target_names"].tolist()
def __call__(self, flask_request):
payload = flask_request.json["vector"]
print("Worker: received flask request with data", payload)
prediction = self.model.predict([payload])[0]
human_name = self.label_list[prediction]
return {"result": human_name}
# Deploy model
serve.init()
serve.create_backend("iris:v1", BoostingModel)
serve.create_endpoint("iris_classifier", backend="iris:v1", route="/iris")
# Query it!
sample_request_input = {"vector": [1.2, 1.0, 1.1, 0.9]}
response = requests.get("http://localhost:8000/iris", json=sample_request_input)
print(response.text)
# Result:
# {
# "result": "versicolor"
# }
三、Have A TRY
Ray是一个基于Python的分布式执行引擎。相同的代码可以在单个机器上运行以实现高效的多处理,并且可以在群集上用于大量的计算。
使用Ray时,涉及以下几个过程:
- 多个工作进行执行任务,并将结果村存储在对象库中,每个进程是一个独立的处理单位。
- 每个节点的存储不可变的对象在共享内存中,并允许进程在相同节点上高效复制和反序列化对象
- 一个全局调度器调度接收任务,并将它们分配到其他地方节点运行
- 一个driver是用户控制的python程序。例如,如果用户正在运行脚本或使用python shell,那么driver就是运行的脚本或者python进程。driver与工作程序类似,都可以将任务提交给本地调度程序,并从对象存储中获取对象,但不同之处在于本地调度程序不会讲任务分配给要执行的driver
- 一个Redis服务器维护大量的系统状态,例如,他跟踪哪些对象在哪些机器上以及任务规范(而不是数据)上,他可以直接用于调试目的的查询。
NOTE: As of Ray 0.8.1, Python 2 is no longer supported.
1. 简单开始
并行执行Python函数。
import ray
ray.init()
@ray.remote
def f(x):
return x * x
futures = [f.remote(i) for i in range(4)]
print(ray.get(futures))
要使用Ray的角色模型(Actors):
import ray
ray.init()
@ray.remote
class Counter(object):
def __init__(self):
self.n = 0
def increment(self):
self.n += 1
def read(self):
return self.n
counters = [Counter.remote() for i in range(4)]
[c.increment.remote() for c in counters]
futures = [c.read.remote() for c in counters]
print(ray.get(futures))
Ray程序可以在单台计算机上运行,也可以无缝扩展到大型群集。 要在云中执行上述Ray脚本,只需下载这个文件并运行:
ray submit [CLUSTER.YAML] example.py --start
2. 模拟器的虚构示例
仅用远程函数和上述的任务所无法完成的一件事是在相同的共享可变状态上执行多个任务。这在很多机器学习场景中都出现过,其中共享状态可能是模拟器的状态、神经网络的权重或其它。Ray 使用 actor 抽象以封装多个任务之间共享的可变状态。以下是关于 Atari 模拟器的虚构示例:
import gym
@ray.remote
class Simulator(object):
def __init__(self):
self.env = gym.make("Pong-v0")
self.env.reset()
def step(self, action):
return self.env.step(action)
# Create a simulator, this will start a remote process that will run
# all methods for this actor.
simulator = Simulator.remote()
observations = []
for _ in range(4):
# Take action 0 in the simulator. This call does not block and
# it returns a future.
observations.append(simulator.step.remote(0))
Actor 可以很灵活地应用。例如,actor 可以封装模拟器或神经网络策略,并且可以用于分布式训练(作为参数服务器),或者在实际应用中提供策略。
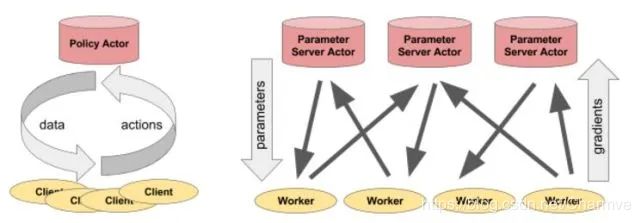
3. 参数服务器示例
一个参数服务器可以作为一个 Ray actor 按如下代码实现:
@ray.remote
class ParameterServer(object):
def __init__(self, keys, values):
# These values will be mutated, so we must create a local copy.
values = [value.copy() for value in values]
self.parameters = dict(zip(keys, values))
def get(self, keys):
return [self.parameters[key] for key in keys]
def update(self, keys, values):
# This update function adds to the existing values, but the update
# function can be defined arbitrarily.
for key, value in zip(keys, values):
self.parameters[key] += value
这里有更完整的示例:http://ray.readthedocs.io/en/latest/example-parameter-server.html
执行以下代码初始化参数服务器:
parameter_server = ParameterServer.remote(initial_keys, initial_values)
执行以下代码,创建 4 个长时间运行的持续恢复和更新参数的工作进程:
@ray.remote
def worker_task(parameter_server):
while True:
keys = ['key1', 'key2', 'key3']
# Get the latest parameters.
values = ray.get(parameter_server.get.remote(keys))
# Compute some parameter updates.
updates = …
# Update the parameters.
parameter_server.update.remote(keys, updates)
# Start 4 long-running tasks.
for _ in range(4):
worker_task.remote(parameter_server)
四、Ray V.S. Python
概念插播:不可变远程对象
在Ray中,我们可以创建和计算对象。我们将这些对象称为远程对象使用对象ID来引用它们。远程对象存储在对象存储中,并且群集中每个节点都有一个对象存储。在集群设置中,我们可能实际上并不知道每个对象所在的机器。一个对象ID本质上是一个唯一的ID可以被用来指代一个远程对象。如果您对Futures熟悉,我们的对象ID在概念上是相似的。
我们假设远程对象是不可变的。也就是说,它们的值在创建后不能改变。这允许远程对象在多个对象存储中被复制,而不需要同步副本。
4.1 Put 和 Get
命令ray.get和ray.put可用于Python对象之间进行转换和对象ID,如示于以下的例子。
x = "example"
ray.put (x ) #ObjectID(b49a32d72057bdcfc4dda35584b3d838aad89f5d)
该命令ray.put(x)将由工作进程或驱动程序进程运行(驱动程序进程是运行脚本的进程)。它需要一个Python对象,并将其复制到本地对象存储区(这里的本地手段在同一个节点上)。一旦对象被存储在对象存储中,其值就不能被改变。
另外,ray.put(x)返回一个对象ID,它本质上是一个可以用来引用新创建的远程对象的ID。如果我们把对象ID保存在一个变量中,那么我们就可以传入远程函数,这些远程函数将在相应的远程对象上运行
ray.x_id = ray.put(x)
该命令ray.get(x_id)获取一个对象ID,并从相应的远程对象中创建一个Python对象。对于像数组这样的对象,我们可以使用共享内存,避免复制对象。对于其他对象,这将对象从对象存储复制到工作进程的堆。如果与对象ID相对应的远程对象x_id不是与调用的worker相同的节点上ray.get(x_id),则远程对象将首先从具有该远程对象的对象库转移到需要它的对象库。
x_id = ray.get("example")
ray.get(x_id ) #“example”
如果与对象ID对应的远程对象x_id尚未创建,则该命令ray.get(x_id)将等待,直到创建远程对象。
一个非常常见的用例ray.get是获取对象ID的列表。在这种情况下,你可以调用ray.get(object_ids), 其中object_ids的对象ID的列表。
result_ids = [ ray.put(i) for i in range(10)]
ray.get(result_ids) #[0,1,2,3,4,5,6,7,8,9]
4.2 Ray 中的异步计算
Ray允许任意Python函数异步执行。这是通过将Python函数指定为远程函数来完成的。
例如,一个普通的Python函数看起来像这样。
def add1 (a , b ):
return a + b
一个远程函数看起来像这样。
@ray.remote
def add2 (a , b ):
return a + b
4.3 远程功能
然而调用返回并导致Python解释器阻塞,直到计算完成,调用 立即返回一个对象ID并创建一个任务。该任务将由系统调度并异步执行(可能在不同的机器上)。当任务完成执行时,其返回值将被存储在对象存储中。
x_id = add2.remote(1 , 2)
ray.get(x_id ) #3
以下简单示例演示了如何使用异步任务来并行化计算。
import time
def f1():
time.sleep(1)
@ray.remote
def f2():
time.sleep(1)
#以下需要十秒。
[f1() for _ in range(10)]
#以下需要一秒(假设系统至少有10个CPU)。
ray.get([ f2.remote() for _ in range(10)])
提交任务和执行任务之间存在明显的区别。当调用远程函数时,执行该函数的任务将被提交给本地调度程序,并立即返回任务输出的对象ID。但是,在系统实际上在工作人员上安排任务之前,任务不会被执行。任务执行不是懒惰地完成的。系统将输入数据移动到任务中,一旦输入相关性可用并且有足够的资源进行计算,任务将立即执行。
提交任务时,每个参数可以通过值或对象ID传入。例如,这些行具有相同的行为。
add2.remote(1, 2)
add2.remote(1, ray.put(2))
add2.remote(ray.put(1), ray.put(2))
远程函数永远不会返回实际值,它们总是返回对象ID。
当远程函数被实际执行时,它对Python对象进行操作。也就是说,如果使用任何对象ID调用远程函数,系统将从对象存储中检索相应的对象。
请注意,远程函数可以返回多个对象ID。
@ray.remote(num_return_vals=3)
def return_multiple():
return 1, 2, 3
a_id, b_id, c_id = return_multiple.remote()
4.4 表达任务之间的依赖关系
程序员可以通过将一个任务的对象ID输出作为参数传递给另一个任务来表达任务之间的依赖关系。例如,我们可以启动三个任务,每个任务都依赖于前一个任务。
@ray.remote
def f(x):
return x + 1
x = f.remote(0)
y = f.remote(x)
z = f.remote(y)
ray.get(z) # 3
上面的第二个任务将不会执行,直到第一个任务完成,第三个任务将不会执行直到第二个任务完成。在这个例子中,没有并行的机会。
编写任务的能力可以很容易地表达有趣的依赖关系。考虑下面的一个树减少的实现。
import numpy as np
@ray.remote
def generate_data():
return np.random.normal(size=1000)
@ray.remote
def aggregate_data(x, y):
return x + y
# Generate some random data. This launches 100 tasks that will be scheduled on
# various nodes. The resulting data will be distributed around the cluster.
data = [generate_data.remote() for _ in range(100)]
# Perform a tree reduce.
while len(data) > 1:
data.append(aggregate_data.remote(data.pop(0), data.pop(0)))
# Fetch the result.
ray.get(data)
4.5 有效地对值进行聚合
我们可以以更复杂的方式使用任务依赖。例如,假设我们希望将8个值聚合在一起。在我们的示例中,我们将进行整数加法,但在很多应用程序中,跨多台计算机聚合大型向量可能会造成性能瓶颈。在这个时候,只要修改一行代码就可以将聚合的运行时间从线性降为对数级别,即聚合值的数量。
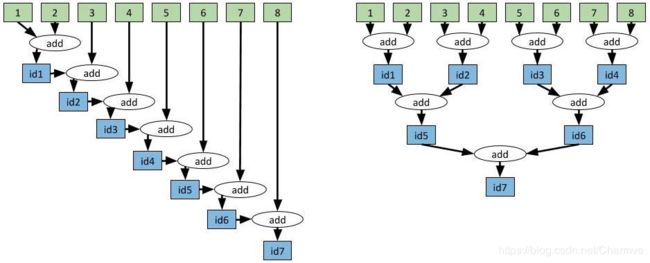
如上所述,要将一个任务的输出作为输入提供给后续任务,只需将第一个任务返回的future作为参数传给第二个任务。Ray的调度程序会自动考虑任务依赖关系。在第一个任务完成之前不会执行第二个任务,第一个任务的输出将自动被发送给执行第二个任务的机器。
import time
@ray.remote
def add(x, y):
time.sleep(1)
return x + y
# Aggregate the values slowly. This approach takes O(n) where n is the
# number of values being aggregated. In this case, 7 seconds.
id1 = add.remote(1, 2)
id2 = add.remote(id1, 3)
id3 = add.remote(id2, 4)
id4 = add.remote(id3, 5)
id5 = add.remote(id4, 6)
id6 = add.remote(id5, 7)
id7 = add.remote(id6, 8)
result = ray.get(id7)
# Aggregate the values in a tree-structured pattern. This approach
# takes O(log(n)). In this case, 3 seconds.
id1 = add.remote(1, 2)
id2 = add.remote(3, 4)
id3 = add.remote(5, 6)
id4 = add.remote(7, 8)
id5 = add.remote(id1, id2)
id6 = add.remote(id3, id4)
id7 = add.remote(id5, id6)
result = ray.get(id7)
code1 以线性方式聚合值与以树形结构方式聚合值的对比
上面的代码非常清晰,但请注意,这两种方法都可以使用while循环来实现,这种方式更为简洁。
# Slow approach.
values = [1, 2, 3, 4, 5, 6, 7, 8]
while len(values) > 1:
values = [add.remote(values[0], values[1])] + values[2:]
result = ray.get(values[0])
# Fast approach.
values = [1, 2, 3, 4, 5, 6, 7, 8]
while len(values) > 1:
values = values[2:] + [add.remote(values[0], values[1])]
result = ray.get(values[0])
更简洁的聚合实现方案。两个代码块之间的唯一区别是“add.remote”的输出是放在列表的前面还是后面。
4.6 从类到actor
在不使用类的情况下开发有趣的应用程序很具挑战性,在分布式环境中也是如此。
你可以使用@ray.remote装饰器声明一个Python类。在实例化类时,Ray会创建一个新的“actor”,这是一个运行在集群中并持有类对象副本的进程。对这个actor的方法调用转变为在actor进程上运行的任务,并且可以访问和改变actor的状态。通过这种方式,可以在多个任务之间共享可变状态,这是远程函数无法做到的。
各个actor按顺序执行方法(每个方法都是原子方法),因此不存在竞态条件。可以通过创建多个actor来实现并行性。
@ray.remote
class Counter(object):
def __init__(self):
self.x = 0
def inc(self):
self.x += 1
def get_value(self):
return self.x
# Create an actor process.
c = Counter.remote()
# Check the actor's counter value.
print(ray.get(c.get_value.remote())) # 0
# Increment the counter twice and check the value again.
c.inc.remote()
c.inc.remote()
print(ray.get(c.get_value.remote())) # 2
code2 将Python类实例化为actor
上面的例子是actor最简单的用法。Counter.remote()创建一个新的actor进程,它持有一个Counter对象副本。对c.get_value.remote()和c.inc.remote()的调用会在远程actor进程上执行任务并改变actor的状态。
4.7 actor句柄
在上面的示例中,我们只在主Python脚本中调用actor的方法。actor的一个最强大的地方在于我们可以将句柄传给它,让其他actor或其他任务都调用同一actor的方法。
以下示例创建了一个可以保存消息的actor。几个worker任务反复将消息推送给actor,主Python脚本定期读取消息。
import time
@ray.remote
class MessageActor(object):
def __init__(self):
self.messages = []
def add_message(self, message):
self.messages.append(message)
def get_and_clear_messages(self):
messages = self.messages
self.messages = []
return messages
# Define a remote function which loops around and pushes
# messages to the actor.
@ray.remote
def worker(message_actor, j):
for i in range(100):
time.sleep(1)
message_actor.add_message.remote(
"Message {} from actor {}.".format(i, j))
# Create a message actor.
message_actor = MessageActor.remote()
# Start 3 tasks that push messages to the actor.
[worker.remote(message_actor, j) for j in range(3)]
# Periodically get the messages and print them.
for _ in range(100):
new_messages = ray.get(message_actor.get_and_clear_messages.remote())
print("New messages:", new_messages)
time.sleep(1)
# This script prints something like the following:
# New messages: []
# New messages: ['Message 0 from actor 1.', 'Message 0 from actor 0.']
# New messages: ['Message 0 from actor 2.', 'Message 1 from actor 1.', 'Message 1 from actor 0.', 'Message 1 from actor 2.']
# New messages: ['Message 2 from actor 1.', 'Message 2 from actor 0.', 'Message 2 from actor 2.']
# New messages: ['Message 3 from actor 2.', 'Message 3 from actor 1.', 'Message 3 from actor 0.']
# New messages: ['Message 4 from actor 2.', 'Message 4 from actor 0.', 'Message 4 from actor 1.']
# New messages: ['Message 5 from actor 2.', 'Message 5 from actor 0.', 'Message 5 from actor 1.']
code3 在多个并发任务中调用actor的方法
actor非常强大。你可以通过它将Python类实例化为微服务,可以从其他actor和任务(甚至其他应用程序中)查询这个微服务。
任务和actor是Ray提供的核心抽象。这两个概念非常通用,可用于实现复杂的应用程序,包括用于强化学习、超参数调整、加速Pandas等Ray内置库。
参考资料:
[1] Ray. https://rise.cs.berkeley.edu/projects/ray/
[2] Ray paper. https://www.usenix.org/system/files/osdi18-moritz.pdf
[3] GitHub. https://github.com/ray-project/ray
[4] Documents. https://docs.ray.io/en/latest/index.html
[5] Blog: https://ray-project.github.io
[6] Ray: A Distributed System for AI. Robert Nishihara and Philipp Moritz. Jan 9, 2018 https://bair.berkeley.edu/blog/2018/01/09/ray/
[7] 高性能分布式执行框架——Ray https://www.cnblogs.com/fanzhidongyzby/p/7901139.html
[8] 取代 Python 多进程!伯克利开源分布式框架 Ray https://blog.csdn.net/weixin_33918114/article/details/89122027
[9] UC Berkeley提出新型分布式执行框架Ray:有望取代Spark https://blog.csdn.net/weixin_34101784/article/details/87945299
[10] 基于python的高性能实时并行机器学习框架之Ray介绍 https://blog.csdn.net/lck5602/article/details/78665520
[11] UC Berkeley提出新型分布式框架Ray:实时动态学习的开端 https://blog.csdn.net/uwr44uouqcnsuqb60zk2/article/details/78869192
[12] 继 Spark 之后,UC Berkeley 推出新一代 AI 计算引擎 ——Ray https://www.qtmuniao.com/2019/04/06/ray/