前端面试必考题:React Hooks原理剖析
为什么要学习 React Hooks 原理
首先,功利点来说:目前前端框架三分天下:React、Vue、Angular,而 React 自从 v16.8.0 版本正式推出 React Hooks 概念后,风势已经从原来的类组件猛地转向函数组件,这是一个在设计模式、心智模型层次,且非常近期的革新,因此只要是你谈到自己会 React ,就一定会在面试中被问到 React Hooks 的原理。
再者,从实际角度出发,了解 React Hooks 原理对我们日常开发调试都有莫大的好处;我们可以认识到 React Hooks 其实也并不是什么黑魔法,我们在开发中碰到的奇奇怪怪的问题,只不过是我们还没有掌握 React Hooks 导致的,也不需要用一些 tricky 的方法来解决。
useState / useReducer
useState 和 useReducer 都是关于状态值的提取和更新,从本质上来说没有区别,从实现上,可以说 useState 是 useReducer 的一个简化版,其背后用的都是同一套逻辑。
React Hooks 如何保存状态
React 官方文档中有提到,React Hooks 保存状态的位置其实与类组件的一致;翻看源码后,我发现这样的说法没错,但又不全面:
两者的状态值都被挂载在组件实例对象 FiberNode 的 memoizedState 属性中。
两者保存状态值的数据结构完全不同;类组件是直接把 state 属性中挂载的这个开发者自定义的对象给保存到 memoizedState 属性中;而 React Hooks 是用链表来保存状态的, memoizedState 属性保存的实际上是这个链表的头指针。
下面我们来看看这个链表的节点是什么样的 —— Hook 对象:
// react-reconciler/src/ReactFiberHooks.js
export type Hook = {
memoizedState: any, // 最新的状态值
baseState: any, // 初始状态值,如`useState(0)`,则初始值为0
baseUpdate: Update | null,
queue: UpdateQueue | null, // 临时保存对状态值的操作,更准确来说是一个链表数据结构中的一个指针
next: Hook | null, // 指向下一个链表节点
};
官方文档一直强调 React Hooks 的调用只能放在函数组件/自定义 Hooks 函数体的顶层,这是因为我们只能通过 Hooks 调用的顺序来与实际保存的数据结构来关联:
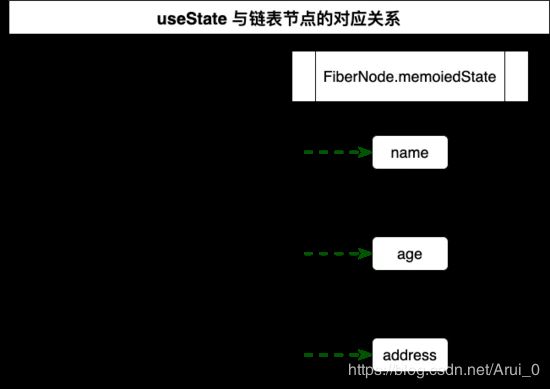
PS:虽然上面一致都是以 useState 和 useReducer 来作为例子说明,但实际上所有 React Hooks 都是用这种链表的方式来保存的。
React Hooks 如何更新状态
熟悉 useState API 的话,我们都知道怎么去更新状态:
const [name, setName] = useState('')
setName('张三')
那么,由 useState 返回的这个用来更新状态的函数(下文称为 dispatcher),运行的原理是怎么样的呢?
当我们在每次调用 dispatcher 时,并不会立刻对状态值进行修改(对的,状态值的更新是异步的),而是创建一条修改操作——在对应 Hook 对象的queue属性挂载的链表上加一个新节点:
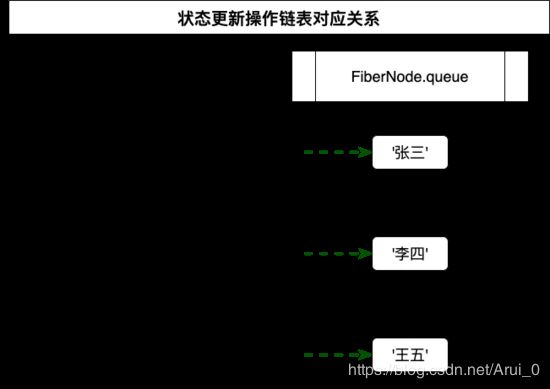
在下次执行函数组件,再次调用 useState 时, React 才会根据每个 Hook 上挂载的更新操作链表来计算最新的状态值。你也许会好奇,为什么要把更新操作都保存起来呢,只保存最新的一次更新操作不就行了吗?你会这样想,大概是忘了 useState 支持这样的语法了吧:
const [name, setName] = useState('')
setName(name => name + 'a')
setName(name => name + 'b')
setName(name => name + 'c')
// 下次执行时就可以得到 name 的最新状态值为'abc'啦
useEffect
useEffect 的保存方式与 useState / useReducer类似,也是以链表的形式挂载在 FiberNode.updateQueue中。
下面我们按 mount 和 update 这两个组件生命周期来阐述 useEffect 的执行原理:
mount 阶段:mountEffect
根据函数组件函数体中依次调用的 useEffect 语句,构建成一个链表并挂载在 FiberNode.updateQueue中,链表节点的数据结构为:
const effect: Effect = {
tag, // 用来标识依赖项有没有变动
create, // 用户使用useEffect传入的函数体
destroy, // 上述函数体执行后生成的用来清除副作用的函数
deps, // 依赖项列表
next: (null: any),
};
组件完成渲染后,遍历链表执行。
update 阶段:updateEffect
同样在依次调用 useEffect 语句时,判断此时传入的依赖列表,与链表节点Effect.deps中保存的是否一致(基本数据类型的值是否相同;对象的引用是否相同),如果一致,则在 Effect.tag标记上 NoHookEffect。
执行阶段
在每次组件渲染完成后,就会进入 useEffect 的执行阶段:function commitHookEffectList():
遍历链表
如果遇到Effect.tag被标记上NoHookEffect的节点则跳过。
如果Effect.destroy为函数类型,则需要执行该清除副作用的函数(至于这Effect.destroy是从哪里来的,下面马上说到)
执行Effect.create,并将执行结果保存到Effect.destroy(如果开发者没有配置 return,那得到的自然是 undefined了,也就是说,开发者认为对于当前 useEffect 代码段,不存在需要清除的副作用);注意由于闭包的缘故,Effect.destroy实际上可以访问到本次 Effect.create函数作用域内的变量。
我们重点请注意到: 是先清除上一轮的副作用,然后再执行本轮的 effect 的 。
其它 React Hooks Api
其它的的 React Hooks Api ,其实也差不多是这样的原理:用链表数据结构来做全局状态保持;判断依赖项决定是否要更新状态等等,这里不再累述。
有想了解更多的小伙伴可以加Q群链接里面看一下,应该对你们能够有所帮助。