分布式环境下,对于线上出现问题往往比单体应用要复杂的多,原因是前端的一个请求可能对应后端多个系统的多个请求,错综复杂。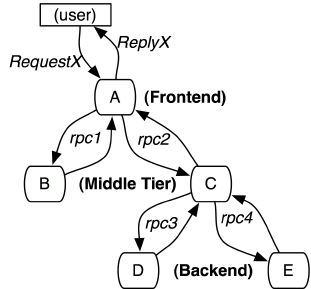
对于快速问题定位,我们一般希望是这样的:
- 从下到下关键节点的日志,入参,出差,异常等。
- 关键节点的响应时间
- 关键节点依赖关系
而这些需求原来在单体应用中可以比较容易实现,但到了分布式环境,可能会出现:
- 每个系统的技术栈不同
- 有的系统有日志有的连日志都没有
- 日志实现手段不相同
以上系统都是自治的,要想看整体的调用链非常困难。
分布式系统日志统一的手段有很多,比如常见的ELK,但这些日志都是文本,不太容易做分析。
更希望看到类似如下浏览器对于网络请求的分析:将分散的请求串联在一起

zipkin
这是推特的一个产品,通过API收集各系统的调用链信息然后做数据分析,展示调用链数据。
核心功能:
- 搜索调用链信息
此处不多说,无非就是从存储中按一定条件搜索请求信息。
zipkin默认是内存存储,也可以是其它的比如:mysq,elasticsearch
- 查看某条请求的详细调用链
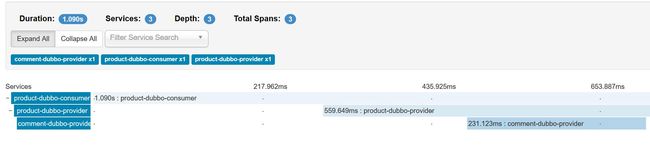
比如查询产品明细,除了产品的基本信息还需要展示对产品的所有评论。下图可以清晰的展示调用关系,product-dubbo-consumer调用product-dubbo-provider,product-dubbo-provider内部再调用comment-dubbo-provider。每步之间的时间也一目了然。
上面显示的时间默认是指调用端发起远程开始到从服务端接收到数据,其中包含网络连接以及数据传输的时间。
- 查看服务之间的依赖关系
互联网项目目前微服务比较流行,微服务之间可能会存在循环引用形成一个网状关系。当项目规模越来越大后,微服务之间的依赖关系估计谁也理不清,现在可以从请求链中清楚查看依赖。

几个关键概念
-
traceId
就是一个全局的跟踪ID,是跟踪的入口点,根据需求来决定在哪生成traceId。比如一个http请求,首先入口是web应用,一般看完整的调用链这里自然是traceId生成的起点,结束点在web请求返回点。 -
spanId
这是下一层的请求跟踪ID,这个也根据自己的需求,比如认为一次rpc,一次sql执行等都可以是一个span。一个traceId包含一个以上的spanId。 -
parentId
上一次请求跟踪ID,用来将前后的请求串联起来。 -
cs
客户端发起请求的时间,比如dubbo调用端开始执行远程调用之前。 -
cr
客户端收到处理完请求的时间。 -
ss
服务端处理完逻辑的时间。 -
sr
服务端收到调用端请求的时间。
客户端调用时间=cr-cs
服务端处理时间=sr-ss
优化考虑
默认系统是通过http请求将数据发送到zipkin,如果系统的调用量比较大,需要考虑如下这些问题:
-
网络传输
如果一次请求内部包含多次远程请求,那么对应span生成的数据会相对较大,可以考虑压缩之后再传输。 -
阻塞
调用链的功能只是辅助功能,不能影响现有业务系统(比如性能相比之前有下降,zipkin的稳定性影响现有业务等),所以在推送日志时最好采用异步+容错方式进行。 -
数据丢失
如果日志在后台积压,未处理完时服务器出现重启就会导致未来的急处理的日志数据会丢失,尽管这种调用数据可以容忍,但如果想做到极致的话,也是有办法的,比如用消息队列做缓冲。
dubbo zipkin
由于工作中一直用dubbo这个rpc框架实现微服务,以前我们基本都是在kibana平台上查询各自服务的日志然后分析,比较麻烦,特别是在分析性能瓶颈时。在dubbo中引入zipkin是非常方便的,因为无非就是写filter,在请求处理前后发送日志数据,让zipkin生成调用链数据。
调用链跟踪自动配置
由于我的项目环境是spring boot,所以附带做一个调用链追踪的自动配置。
- 自动配置的注解
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface EnableTraceAutoConfigurationProperties {
}
- 自动配置的实现,主要是将特定配置节点的值读取到上下文对象中
@Configuration
@ConditionalOnBean(annotation = EnableTraceAutoConfigurationProperties.class)
@AutoConfigureAfter(SpringBootConfiguration.class)
@EnableConfigurationProperties(TraceConfig.class)
public class EnableTraceAutoConfiguration {
@Autowired
private TraceConfig traceConfig;
@PostConstruct
public void init() throws Exception {
TraceContext.init(this.traceConfig);
}
}
- 配置类
@ConfigurationProperties(prefix = "dubbo.trace")
public class TraceConfig {
private boolean enabled=true;
private int connectTimeout;
private int readTimeout;
private int flushInterval=0;
private boolean compressionEnabled=true;
private String zipkinUrl;
@Value("${server.port}")
private int serverPort;
@Value("${spring.application.name}")
private String applicationName;
}
-
spring 配置
按如下图配置才能实现自动加载功能。
-
启动自动配置
最后在启动类中增加@EnableTraceAutoConfigurationProperties即可显示启动。
追踪上下文数据
因为一个请求内部会多次调用下级远程服务,所以会共享traceId以及spanId等,设计一个TraceContext用来方便访问这些共享数据。
这些上下文数据由于是请求级别,所以用ThreadLocal存储
public class TraceContext extends AbstractContext {
private static ThreadLocal<Long> TRACE_ID = new InheritableThreadLocal<>();
private static ThreadLocal<Long> SPAN_ID = new InheritableThreadLocal<>();
private static ThreadLocal<List<Span>> SPAN_LIST = new InheritableThreadLocal<>();
public static final String TRACE_ID_KEY = "traceId";
public static final String SPAN_ID_KEY = "spanId";
public static final String ANNO_CS = "cs";
public static final String ANNO_CR = "cr";
public static final String ANNO_SR = "sr";
public static final String ANNO_SS = "ss";
private static TraceConfig traceConfig;
public static void clear(){
TRACE_ID.remove();
SPAN_ID.remove();
SPAN_LIST.remove();
}
public static void init(TraceConfig traceConfig) {
setTraceConfig(traceConfig);
}
public static void start(){
clear();
SPAN_LIST.set(new ArrayList<Span>());
}
}
zipkin日志收集器
这里直接使用http发送数据,详细代码就不贴了,核心功能就是将数据通过http传送到zipkin,中间可以配合压缩等优化手段。
日志收集器代理
由于考虑到会扩展到多种日志收集器,所以用代理做封装。考虑到优化,可以结合线程池来异步执行日志发送,避免阻塞正常业务逻辑。
public class TraceAgent {
private final AbstractSpanCollector collector;
private final int THREAD_POOL_COUNT=5;
private final ExecutorService executor =
Executors.newFixedThreadPool(this.THREAD_POOL_COUNT, new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread worker = new Thread(r);
worker.setName("TRACE-AGENT-WORKER");
worker.setDaemon(true);
return worker;
}
});
public TraceAgent(String server) {
SpanCollectorMetricsHandler metrics = new SimpleMetricsHandler();
collector = HttpCollector.create(server, TraceContext.getTraceConfig(), metrics);
}
public void send(final List<Span> spans){
if (spans != null && !spans.isEmpty()){
executor.submit(new Runnable() {
@Override
public void run() {
for (Span span : spans){
collector.collect(span);
}
collector.flush();
}
});
}
}
}
dubbo filter
上面做了那么的功能,都是为filter实现准备的。使用filter机制基本上可以认为对现有系统是无侵入性的,当然如果公司项目都直接引用dubbo原生包多少有些麻烦,最好的做法是公司对dubbo做一层包装,然后项目引用包装之后的包,这样就可以避免上面提到的问题,如此一来,调用端只涉及到修改配置文件。
- 调用端filter
调用端是调用链的入口,但需要判断是第一次调用还是内部多次调用。如果是第一次调用那么生成全新的traceId以及spanId。如果是内部多次调用,那么需要从TraceContext中获取traceId以及spanId。
private Span startTrace(Invoker invoker, Invocation invocation) {
Span consumerSpan = new Span();
Long traceId=null;
long id = IdUtils.get();
consumerSpan.setId(id);
if(null==TraceContext.getTraceId()){
TraceContext.start();
traceId=id;
}
else {
traceId=TraceContext.getTraceId();
}
consumerSpan.setTrace_id(traceId);
consumerSpan.setParent_id(TraceContext.getSpanId());
consumerSpan.setName(TraceContext.getTraceConfig().getApplicationName());
long timestamp = System.currentTimeMillis()*1000;
consumerSpan.setTimestamp(timestamp);
consumerSpan.addToAnnotations(
Annotation.create(timestamp, TraceContext.ANNO_CS,
Endpoint.create(
TraceContext.getTraceConfig().getApplicationName(),
NetworkUtils.ip2Num(NetworkUtils.getSiteIp()),
TraceContext.getTraceConfig().getServerPort() )));
Map<String, String> attaches = invocation.getAttachments();
attaches.put(TraceContext.TRACE_ID_KEY, String.valueOf(consumerSpan.getTrace_id()));
attaches.put(TraceContext.SPAN_ID_KEY, String.valueOf(consumerSpan.getId()));
return consumerSpan;
}
private void endTrace(Span span, Stopwatch watch) {
span.addToAnnotations(
Annotation.create(System.currentTimeMillis()*1000, TraceContext.ANNO_CR,
Endpoint.create(
span.getName(),
NetworkUtils.ip2Num(NetworkUtils.getSiteIp()),
TraceContext.getTraceConfig().getServerPort())));
span.setDuration(watch.stop().elapsed(TimeUnit.MICROSECONDS));
TraceAgent traceAgent=new TraceAgent(TraceContext.getTraceConfig().getZipkinUrl());
traceAgent.send(TraceContext.getSpans());
}
调用端需要通过Invocation的参数列表将生成的traceId以及spanId传递到下游系统中。
Map<String, String> attaches = invocation.getAttachments();
attaches.put(TraceContext.TRACE_ID_KEY, String.valueOf(consumerSpan.getTrace_id()));
attaches.put(TraceContext.SPAN_ID_KEY, String.valueOf(consumerSpan.getId()));
- 服务端filter
与调用端的逻辑类似,核心区别在于发送给zipkin的数据是服务端的。
private Span startTrace(Map<String, String> attaches) {
Long traceId = Long.valueOf(attaches.get(TraceContext.TRACE_ID_KEY));
Long parentSpanId = Long.valueOf(attaches.get(TraceContext.SPAN_ID_KEY));
TraceContext.start();
TraceContext.setTraceId(traceId);
TraceContext.setSpanId(parentSpanId);
Span providerSpan = new Span();
long id = IdUtils.get();
providerSpan.setId(id);
providerSpan.setParent_id(parentSpanId);
providerSpan.setTrace_id(traceId);
providerSpan.setName(TraceContext.getTraceConfig().getApplicationName());
long timestamp = System.currentTimeMillis()*1000;
providerSpan.setTimestamp(timestamp);
providerSpan.addToAnnotations(
Annotation.create(timestamp, TraceContext.ANNO_SR,
Endpoint.create(
TraceContext.getTraceConfig().getApplicationName(),
NetworkUtils.ip2Num(NetworkUtils.getSiteIp()),
TraceContext.getTraceConfig().getServerPort() )));
TraceContext.addSpan(providerSpan);
return providerSpan;
}
private void endTrace(Span span, Stopwatch watch) {
span.addToAnnotations(
Annotation.create(System.currentTimeMillis()*1000, TraceContext.ANNO_SS,
Endpoint.create(
span.getName(),
NetworkUtils.ip2Num(NetworkUtils.getSiteIp()),
TraceContext.getTraceConfig().getServerPort())));
span.setDuration(watch.stop().elapsed(TimeUnit.MICROSECONDS));
TraceAgent traceAgent=new TraceAgent(TraceContext.getTraceConfig().getZipkinUrl());
traceAgent.send(TraceContext.getSpans());
}
RPC之间的调用之所以能够串起来,主要是通过dubbo的Invocation所携带的参数来传递
filter应用
- 调用端
<dubbo:consumer filter="traceConsumerFilter">dubbo:consumer>
- 服务端
<dubbo:provider filter="traceProviderFilter" />
埋点
要想生成调用链的数据,就需要确认关键节点,不限于远程调用,也有可能是本地的服务方法的调用,这就需要根据不同的需求来做埋点。
- web 请求,通过filter机制,粗粒度。
- rpc 请求,通过filter机制(一般rpc框架都有实现filter做扩展,如果没有就只能自己实现),粗粒度。
- 内部服务,通过AOP机制,一般结合注解,类似于Spring Cache的使用,细粒度。
- 数据库持久层,比如select,update这类,像mybatis都提供了拦截接口,与filter类似,细粒度。
代码下载
https://github.com/jiangmin168168/jim-framework
引用
- 本文主要参考:https://t.hao0.me/devops/2016/10/15/distributed-invoke-trace.html
上面博主的思路还是很不错的,不仅完成了基本功能也提到了需要注意的一些地方,我在此基本上按自己的方式做了一些调整。