递归皮层网络RCN识别文本CAPTCHAS的Science论文基础知识和译文 (公号回复“递归皮层网络”可下载PDF典藏版资料)
递归皮层网络RCN识别文本CAPTCHAS的Science论文基础知识和译文 (公号回复“递归皮层网络”可下载PDF典藏版资料)
原创: 秦陇纪 数据简化DataSimp 今天
数据简化DataSimp导读:硅谷初创公司Vicarious AI的Science论文《高数据效率训练的和文本CAPTCHAs (CompletelyAutomated Public Turing Test to Tell Computers and Humans Apart全自动区分计算机和人类的图灵测试)断字的生成视觉模型(A generative vision model thattrains with high data efficiency and breaks text-based CAPTCHAs)》:论文背景基础知识、VicariousAI初创公司简介、论文译文概述及相关程序等。如有错误或疏漏(包括原文错误)等,请联系[email protected]沟通、指正,文末有作者微信、实名制群联系方式,欢迎留言、转发。
概率生成模型PGM递归皮层网络RCN识别文本CAPTCHAS的Science论文 (35530字)
目录
A论文背景基础知识和公司简介 (7515字)
A.1论文相关背景基础知识
A.2 硅谷初创公司VicariousAI简介
B递归皮层网络RCN识别文本CAPTCHAs的Science论文翻译(14372字)
B.1 递归皮质网络Recursivecortical network
B.2 表征Representation
B.3 推理Inference
B.4 学习Learning
B.5 结论Results
B.6 讨论Discussion
B.7 方法总结Methodssummary
B.8 参考文献和笔记REFERENCESAND NOTES
参考文献(1068字)Appx(626字).数据简化DataSimp社区简介
学术期刊《Science(科学)》2017年10月26日刊发硅谷知名人工智能创业公司Vicarious AI(间接替代人工智能)的一项最新研究论文《A generative vision model that trains with high data efficiency andbreaks text-based CAPTCHAs》。作者在论文中提出了一个不同于深度学习的模型——递归皮质网络(Recursive Cortical Network),突破了基于文本的全自动区分计算机和人类的图灵测试CAPTCHA。和主流的深度学习算法相比,Vicarious AI的递归皮质网络在场景文字识别中体现了300倍的训练数据使用效率。该项研究通过提出一种新型生成式组成模型(generative compositional model):递归皮层网络Recursive Cortical Network(RCN),使用小样本学习,在CAPTCHA上获得突破性成果。RCN的成功表明,在推动人工智能发展的道路上,生成式组成模型(GenerativeCompositional Model),特别是上下文相关概率语法图模型(Context CorrelationProbability Grammar Graph model)和自底向上(bottom-up)/自顶向下(top-down)联合推理算法(Reasoning Algorithm),取得了一个重要的阶段性成果。
Vicarious AI(间接替代人工智能)公司的联合创始人George认为CAPTCHA是一个“完全AI问题”。如果完全地解决了这种类型的问题,那就得到了通用人工智能。为了能彻底识别CAPTCHA,模型必须能识别任何文本。不只是验证码,即使有人在纸上随便写什么形式的字体(就像PPT里的艺术字一样),模型也需要识别出来。想要研究CAPTCHA的科学家不止George团队,很多科学家都意识到识别CAPTCHA的重要性。麻省理工大学的认知科学教授Josh Tenenbaum同样在使用生成概率模型解决CAPTCHA问题。而Vicarious AI的解决方法和其他研究最大的区别是——将脑科学的研究成果应用到生成模型中。
注:早在2013年,Vicarious AI公布结果时引发AI界业内热议,有褒有贬。当时该公司没有拿出有效的研究方法,成为很多A.I.科学家口诛笔伐的主要理由,其中包括Yann LeCun。他在2013年对Vicarious AI进行了激烈抨击,并用“这是最糟糕的教科书式AI炒作案例(It is a text example of AI hype of theworst kind)”来谴责Vicarious AI。毕竟弄虚作假、骗取投资、赚眼球的“伪AI”太多了。
A论文背景基础知识和公司简介(7515字)
论文背景基础知识和公司简介
文|秦陇纪,2018-06-23Sat综合汇编
A.1论文相关背景基础知识
硅谷初创公司Vicarious AI发表Science论文“Agenerative vision model that trains with high data efficiency and breakstext-based CAPTCHAs”相关的背景基础知识:人工智能(Artificial Intelligence/AI)、推理系统/算法(Reasoning System/Algorithm)、计算机视觉(Computer Vision)、CAPTCHA(CompletelyAutomated Public Turing Test to Tell Computers and Humans Apart全自动区分计算机和人类的图灵测试)、机器学习(Machine Learning/ML)、神经网络(Neural Network)、卷积神经网络(Convolutional NeuralNetwork/CNN)、小样本学习(Small Sample Learning)、生成模型(Generative Model)、概率图模型(Probabilistic GraphicalModels/PGMs)/概率生成模型(Probabilistic GenerativeModels/PGM)、生成式组成模型(Generative Compositional Model)、递归皮层网络(Recursive Cortical Network/RCN)、脑科学(BrainScience)、大脑皮层(Cerebral Cortex)、横向连接(lateral connections)等基础概念。
A.1.1 AI相关背景基础知识(Basicknowledge of AI relevant background)
人工智能(ArtificialIntelligence/AI)
1956年夏季,以麦卡赛、明斯基、罗切斯特和申农等为首的一批有远见卓识的年轻科学家在一起聚会,共同研究和探讨用机器模拟智能的一系列有关问题,并首次提出了“人工智能”这一术语,它标志着“人工智能”这门新兴学科的正式诞生。尼尔逊教授对人工智能下了这样一个定义:“人工智能是关于知识的学科――怎样表示知识以及怎样获得知识并使用知识的科学。”美国麻省理工学院温斯顿教授认为:“人工智能就是研究如何使计算机去做过去只有人才能做的智能工作。”这些说法反映了人工智能学科的基本思想和基本内容。即人工智能是研究人类智能活动的规律,构造具有一定智能的人工系统,研究如何让计算机去完成以往需要人的智力才能胜任的工作,也就是研究如何应用计算机的软硬件来模拟人类某些智能行为的基本理论、方法和技术。
https://baike.baidu.com/item/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/9180
推理系统/算法(Reasoning System/Algorithm)
推理系统reasoning systems是一种利用推理deduction和归纳induction等逻辑技术logical techniques,从可用知识available knowledge中产生结论conclusions的软件系统。推理系统在人工智能artificial intelligence和基于知识的系统knowledge-based systems的实现中起着重要的作用。所有计算机系统都是推理系统,因为它们都自动化了某种类型的逻辑logic或决策decision。在信息技术领域的典型应用typical use中,通常执行更为复杂的推理的系统,不适合做相当简单的推理类型fairlystraightforward types of reasoning,例如计算销售税sales tax或客户折扣customer discount,但适合对医学诊断medical diagnosis或数学定理mathematical theorem进行逻辑推断logical inferences。
推理系统分为两种模式:交互式interactive和批处理batch processing。交互式系统界面interactivesystems interface允许用户要求澄清问题clarifying questions,或用户以其他方式指导推理过程guide the reasoning process。推理系统reasoningsystems具有广泛的应用领域,包括:调度scheduling、业务规则处理business rule processing、问题解决problem solving、复杂事件处理complex event processing、入侵检测intrusiondetection、预测分析predictive analytics、机器人技术robotics、计算机视觉computer vision和自然语言处理natural language processing。还有其他逻辑用处Useof logic,以及不确定性下的推理Reasoning under uncertainty。常见的推理系统类型Types of reasoningsystem:1约束求解Constraint solvers,2定理证明器Theorem provers,3逻辑程序Logic programs,4规则引擎Rule engines,5演绎分类器Deductiveclassifier,6机器学习系统Machinelearning systems,7案例推理系统Case-basedreasoning systems,8程序推理系统Proceduralreasoning systems。推理系统相应的、用到的算法,就是推理算法。
https://en.wikipedia.org/wiki/Reasoning_system
计算机视觉(ComputerVision)
计算机视觉是使用计算机及相关设备对生物视觉的一种模拟,主要任务是通过对采集的图片或视频进行处理以获得相应场景的三维信息,就像人类和许多其他类生物每天所做的那样。计算机视觉是一门关于如何运用照相机和计算机来获取我们所需的,被拍摄对象的数据与信息的学问。形象地说,就是给计算机安装上眼睛(照相机)和大脑(算法),让计算机能够感知环境。顶级会议有①ICCV:International Conference on ComputerVision,国际计算机视觉大会;②CVPR:InternationalConference on Computer Vision and Pattern Recognition,国际计算机视觉与模式识别大会;③ECCV:European Conference on Computer Vision,欧洲计算机视觉大会。
https://baike.baidu.com/item/%E8%AE%A1%E7%AE%97%E6%9C%BA%E8%A7%86%E8%A7%89
CAPTCHA(CompletelyAutomated Public Turing Test to Tell Computers and Humans Apart全自动区分计算机和人类的图灵测试)
CAPTCHA项目是Completely Automated Public Turing Test to Tell Computers and HumansApart(全自动区分计算机和人类的图灵测试)的简称,卡内基梅隆大学试图将其注册为商标,但2008年请求被驳回。CAPTCHA的目的是区分计算机和人类的一种程序算法,是一种区分用户是计算机和人的计算程序,这种程序必须能生成并评价人类能很容易通过但计算机却通不过的测试。CAPTCHA的安全性与SPAM数量息息相关,一直以来,是此消彼长。游戏规则:Captcha方公布一系列的图片,破译Captcha的一方提供程序能够分析这些图片中的内容,如果破译方提供的应用程序能够以高于10%的识别率识别出图片内容,则判定破译方获胜。获胜方将得到BEA UG礼品一份!
https://baike.baidu.com/item/Captcha/9630117

文本CAPTCHA,也就是验证码,是用来防止机器人恶意登录网站的网络安全软件。人类是很容易识别出CATPCHA中形状怪异的文字,但对机器而言CAPTCHA则是看不懂的鬼画符,所以这也被视为是一种图灵测试。在2013年,VicariousAI就声称已经攻克CAPTCHA,但公司直到2017年10月26日才发表了论文。其中一个主要原因是,当时CAPTCHA还在被广泛使用,VicariousAI担心发表论文会引发不小的网络安全问题。现在,依旧使用CAPTCHA作为验证手段的公司已经不多了,正是发表论文的好时机。
机器学习(MachineLearning/ML)
机器学习(Machine Learning/ML)专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。它是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科;是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
https://baike.baidu.com/item/机器学习/217599
神经网络(NeuralNetwork)
神经网络分为两种,一种叫做有导师学习,一种叫做无导师学习。有导师学习是感知器的学习规则;而无导师学习是认知器的学习规则。典型的有导师学习网络有BP网络,Hopfield网络;而典型的无导师学习网络有ART网络,Kohonen网络。所谓的“导师”,是指的“导师信号”,也就是学习过程中的监督信号,是在神经网络学习中由外部提供的模式样本信号。
及时澍雨Timely,https://blog.csdn.net/ws_20100/article/details/48929383,2015-10-06.
神经网络历史:①1943年,心理学家W.Mcculloch和数理逻辑学家W. Pitts根据生物神经元功能和结构,提出M-P神经元模型。1957年,Rosenblatt提出感知机MLP模型。Rosenblatt, Frank.x. Principlesof Neurodynamics: Perceptrons and the Theory of Brain Mechanisms. SpartanBooks, Washington DC, 1961. ②1981年,Kohonen提出了自组织映射(SOM)网络。T. Kohonen, Self-organizedformationof topologically correct feature maps, Biological Cybernetics. 1982.43: 59-69.③1982年,Hopfield提出Hopfield网络,用于联想记忆和优化。John J. Hopfield, Neural networks andphysical systems withemergent collective computational abilities, Proc. Natl. Acad. Sci.USA, vol.79 no. 8,pp. 2554–2558, April 1982. ④1986年,Rumelhart和McCelland等提出了误差反向传播(BP)算法,用于多层前馈神经网络的优化。迄今为止应用最广的神经网络学习算法。Rumelhart, David E.; Hinton, GeoffreyE.; Williams, Ronald J. (8 October 1986). Learning representations by back-propagatingerrors. Nature 323 (6088): 533–536.
卷积神经网络(ConvolutionalNeural Network/CNN)
卷积神经网络(Convolutional NeuralNetwork,CNN)是一种前馈神经网络,其人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。它包括卷积层(convolutional layer)和池化层(pooling layer)。https://baike.baidu.com/item/卷积神经网络/17541100
在机器学习machine learning中,卷积神经网络(convolutional neural network,CNN或ConvNet)是一类深度的、前馈的人工神经网络feed-forward artificial neural networks,常用于分析视觉图像analyzing visual imagery。CNNs使用的是为某种需要设计的最小预处理minimal preprocessing的多层感知器multilayer perceptrons的变体variation。[1]他们也被称为移位不变shift invariant或空间不变性人工神经网络space invariant artificial neural networks(SIANN),基于它们的共享权重体系结构shared-weights architecture和翻译不变性特征translationinvariance characteristics。[2][3] 卷积网络由生物过程biological processes启发[4],由于连通性模式connectivity pattern在神经元neurons之间类似动物视觉皮层animal visual cortex的组织。单个皮质神经元cortical neurons只在被称为接受领域receptive field的视觉领域visual field的禁区restricted region内对刺激反应。不同神经元的接受域receptivefields部分重叠,从而覆盖整个视觉场。与其他图像分类算法image classification algorithms相比,CNNs使用的预处理pre-processing相对较少。这意味着网络学会了手工设计hand-engineered的传统算法中的过滤器filters。这种独立于先验知识prior knowledge和人类努力human effort的特征设计feature design是一个主要的优势。它们在图像image和视频识别video recognition、推荐系统recommender systems[5]和自然语言处理natural language processing方面都有应用。[6]
https://en.wikipedia.org/wiki/Convolutional_neural_network
小样本学习(SmallSample Learning)
在互联网,我们主要用large-scale方法处理数据,但真实情况下,大部分类别我们没有数据积累,large-scale方法不完全适用。所以我们希望在学习了一定类别的大量数据后,对于新的类别,我们只需要少量的样本就能快速学习。one-shotlearning,也可以称为few-shot learning或low-shot learning领域。One-shot learning的研究主要分为如下几类:第一类方法是直接基于有监督学习的方法,这是指没有其他的数据源,不将其作为一个迁移学习的问题看待,只利用这些小样本,在现有信息上训练模型,然后做分类;第二个是基于迁移学习的方法,是指有其他数据源时,利用这些辅助数据集去做迁移学习。这是我今年一篇综述里提到的模型分类。
复旦大学付彦伟教授介绍中小样本学习领域研究进展http://www.elecfans.com/d/695496.html
生成模型(GenerativeModel)
监督学习又可以分为两类,判别模型Discriminative model和生成模型generative model,前面提到的SVM和逻辑回归都属于判别模型的一种。https://blog.csdn.net/Fishmemory/article/details/51711114
生成模型(generative models)又叫产生式模型,是机器学习(machinelearning)中监督学习技术(supervisedlearning techniques)的一个分支。生成模型估计的是联合概率分布(joint probability distribution),p(class,context)=p(class|context)*p(context)。为了训练一个生成模型要先在某些领域收集大量的数据(例如数以百万计的图像、句子或声音等),然后训练一个模型来生成像它这样的数据。
https://blog.openai.com/generative-models/
概率图模型(ProbabilisticGraphical Models/PGMs)/概率生成模型(Probabilistic GenerativeModels/PGM)
概率图形模型(Probabilistic graphicalmodels/PGMs)是在复杂域complexdomains上编码概率分布encodingprobability distributions的丰富框架: 在大量随机变量random variables之间相互作用的联合(多元multivariate)分布。这些表述是在统计学statistics和计算机科学computer science的交叉点上,依赖于概率论probability theory、图形算法graph algorithms、机器学习machine learning等概念。它们是在各种应用中最先进的方法state-of-the-art methods的基础,如医学诊断medical diagnosis,图像理解image understanding,语音识别speech recognition,自然语言处理natural language processing以及更多领域。它们也是制定许多机器学习问题formulating many machine learning problems的基础工具。本课程描述了两个基本PGM表示:贝叶斯网络Bayesian Networks(依赖于有向图directed graph);和马尔可夫网络Markov networks(使用无向图undirected graph)。本课程讨论这些表述的理论性质theoreticalproperties以及在实践中的应用。
https://www.coursera.org/learn/probabilistic-graphical-models#%20
生成式组成模型(GenerativeCompositional Model)
从快速一瞥或物体object接触,我们的大脑将感官信号sensory signals映射到由丰富细致的形状和表面rich anddetailed shapes and surfaces组成的场景scenes。与对感知的标准模式认知方法standard pattern recognition approaches to perception不同,我们认为这种映射mapping吸取了外部物理世界outside physical world的内部因果和组合模型internal causal and compositionalmodels, 而这种内部模型internalmodels是人类感知的泛化能力generalization capacity of humanperception的基础。在这里,我们提出一个视觉和多重知觉的生成模型generative model ofvisual and multisensory perception, 其中对象潜在变量编码的内在属性latentvariables encode intrinsic properties of objects, 如其形状shapes和表面surfaces, 除了其外在性质extrinsic properties,如姿态pose和遮挡occlusion。这些潜在的变量latent variables可以以新颖的方式组成,并且是对感官特定的因果模型sensory-specificcausal models的输入,输出特定感知信号sense-specific signals。我们提出了一个新的认知网络recognition network,在生成模型generative model中执行有效推理efficient inference,计算速度speed类似于在线感知online perception。我们展示了我们的模型,但不是一个替代的基线模型alternativebaseline model或我们模型的损害lesion of our model, 可以说明人的表现human performance在一个闭塞的面孔匹配任务occluded facematching task和在一个跨模态视觉到触觉的面对面匹配任务cross-modalvisual-to-haptic face matching task。
http://xueshu.baidu.com/s?wd=paperuri%3A%286ea36d18a3e6f7654abf86bd67d6e522%29&filter=sc_long_sign&sc_ks_para=q%3DCausal%20and%20compositional%20generative%20models%20in%20online%20perception
递归皮层网络(RecursiveCortical Network/RCN)
递归皮层网络,Recursive Cortical Network缩写RCN,是根据实验神经科学设计的机器学习模型。
https://www.zhihu.com/topic/20102999/top-answers
A.1.2 脑科学相关背景基础知识(Basicknowledge of Brain Science relevant background)
脑科学(Brain Science)
脑科学,狭义讲就是神经科学,是为了了解神经系统内分子水平、细胞水平、细胞间的变化过程,以及这些过程在中枢功能控制系统内的整合作用而进行的研究。(美国神经科学学会)广义定义是研究脑的结构和功能的科学,还包括认知神经科学等。
1、基础神经科学:侧重基础理论
–神经生物学:研究人和动物的神经系统的结构与功能、及其相互关系的科学,是在分子水平上、细胞水平上、神经网络或回路水平上乃至系统和整体水平上阐明神经系统特别是脑的物质的、能量的、信息的基本活动规律的科学(认识脑)。由六个研究分支:分子神经生物学(化学物质)、细胞神经生物学(细胞、亚细胞)、系统神经生物学、行为神经生物学(学习记忆、情感、睡眠、觉醒等)、发育神经生物学、比较神经生物学。
–计算神经科学:应用数学理论和计算机模拟方法来研究脑功能的学科。(创造脑)
2、临床神经科学:侧重医学临床应用
研究与神经系统有关的疾病,及其诊断、治疗方法、技术等(保护脑)
https://baike.baidu.com/item/%E8%84%91%E7%A7%91%E5%AD%A6/7652549
大脑皮层(CerebralCortex)
大脑皮层(Cerebral Cortex)结构Structure:层Layers,区Areas,Brodmann Areas区域,厚度Thickness,褶皱Folds,血供排水Blood supply and drainage等组成。功能:连接Connections,皮层区域Cortical areas(知觉区域Sensory areas、监控区域Motor areas、联合区域Association areas)。cortical英['kɔ:tɪkl]美['kɔ:tɪkl]adj.皮层的,皮质的,有关脑皮层的; [例句]In experiments,using this model we simulated the spiking and bursting behavior ofknown types of cortical neurons.在实验中,应用该模型模拟了大部分已知皮层神经元的脉冲和簇放电行为。
https://en.wikipedia.org/wiki/Cerebral_cortex
大脑皮层cerebral cortex是哺乳动物大脑mammalian brain中大脑cerebrum的最大区域,在记忆memory、注意力attention、知觉perception、认知cognition、意识awareness、思想thought、语言language和意识consciousness等方面起着关键作用。大脑皮层是最前面的anterior(延髓rostral)脑子区域brain region,并且包括神经组织neural tissue的外部区域叫灰质gray matter(包含神经细胞身体neuronal cell bodies)。它也被纵向裂隙longitudinal fissure分为左右脑半球left and right cerebral hemispheres,但两个半球在中线midline由胼胝体corpus callosum连接。大脑皮层包含大量的神经细胞neuronal和胶质细胞体glialcell bodies,以及它们错综复杂的树突形成dendritic formations和轴突投射axonal projections,它们连接在突触synapses形成基本功能回路basic functional circuits。大脑皮层完全由灰质graymatter组成,与底层的白质white matter形成对比,主要由皮层cortex、它们的髓鞘myelinated sheaths和少突胶质oligodendrocytes的细胞体cell bodies组成的轴突axons。[11]

横向连接(lateralconnections)
在人类的视觉系统中,视觉皮层中的横向连接(lateral connections)能够保证人类理解物体轮廓的连续性;将人类视觉的特征应用到递归皮质网络上时,横向连接允许递归皮质网络在池化的过程中不会失去特异性,从而增加不变性。皮质层cortical layers不是简单地堆积一在其他;有不同的层数layers和神经元类型neuronal types之间的特征连接characteristic connections,横跨所有皮层的厚度thicknessof the cortex。这些皮质集成回路cortical microcircuits分为皮质柱cortical columns和微柱体minicolumns。微柱体 minicolumns被认为是皮质cortex的基本功能单位。[12] 在1957年,弗农·蒙卡斯尔Vernon Mountcastle展示了皮层的功能性质functional properties of the cortex突然改变在侧向相邻点laterally adjacent points之间;然而,它们在垂直于表面的方向上direction perpendicular to the surface是连续的continuous。后来的著作提供了证据显示,在视觉皮层visual cortex,听觉皮层auditory cortex和联想皮层associative cortex存在功能分明的皮质柱functionallydistinct cortical columns (胡贝尔和魏塞尔Hubel and Wiesel,1959)。[13]
大脑皮层连接到各种皮质皮层结构(如丘脑thalamus和基底神经节basal ganglia),通过传出连接向它们发送信息,并通过传入连接接收信息。大多数感官信息sensory information通过丘脑thalamus传送到大脑皮层cerebral cortex。然而,嗅觉信息Olfactory information通过嗅球olfactory bulb传递到嗅觉皮层olfactory cortex (梨皮质piriform cortex)。大多数的连接是从皮质的一个区域到另一个,而不是皮质皮层区域subcortical areas。在初级感官区域primary sensoryareas的皮层水平the cortical level,输入纤维input fibres终止,多达20%的突触synapses由外胚层extracortical的传入提供,但在其他地区和其他层的百分比可能会更低.(1998,Braitenberg andSchüz)。
A.2硅谷初创公司Vicarious AI简介
A.2.1 公司名称Vicarious知识(Knowledge of Corporation Name Vicarious)
vicarious英[vɪˈkeəriəs]美[vaɪˈkeriəs],adj.(想像别人苦乐情况)间接体验的; 替代别人的; 代理的; 受委托的;[例句]She invents fantasy lives for her ownvicarious pleasure她幻想过着各种奇妙的生活,从想入非非中获得乐趣。

A.2.2 公司介绍和研究主题(ResearchIntroduction and Themes of Corporation)
Vicarious AI是一家硅谷的人工智能(A.I.)初创公司,致力于从人脑中获得启发,实现拥有高等智能的机器人。公司办公室里到处可见其标语——Our Frontier,Human-like AI。攻克CAPTCHA是该公司通往Human-like A.I.的一个中继站,公司CTO说“我们的目标是解决所有人类擅长解决的问题,尤其是在面对自然视觉信号时,如果一生只解决一个问题,我肯定选择人脑。”公司CEO接受高盛投资公司采访中说“人脑就是一个通用学习的基础框架,可以在这个世界里学习各种各样的问题。”当时,提出这个想法的公司很少,但硅谷向来不缺慧眼识人的投资家,比如Facebook天使投资人以及Paypal创始人Peter Thiel。Thiel在2010年底给Vicarious AI一笔种子轮融资。到2014年,Vicarious AI完成4000万美元B轮融资,包括Facebook创始人MarkZuckerberg,Y Combinator的CEO SamAltman,以及Tesla创始人Elon Musk都参与其中。截止目前,Vicarious AI融资总额已超过1.3亿美元。和融资额形成强烈反差的是公司至今不过50人的规模以及缓慢的扩张速度。George透露说,直到2013年Vicarious AI团队才只有六个人。[24]
公司方向是让机器获得感知。从几个训练例子a few trainingexamples中归纳generalize出来的能力是人类智慧thehallmarks of human intelligence的标志之一。这种能力ability是机器人robots在不同环境variety of environments下有效工作的必要条件,而无需进行艰苦的重新编程arduous reprogramming。Vicarious是一家发展通用人工智能机器人artificial general intelligence for robots的公司。通过将生成概率模型generative probabilistic models和系统神经科学systemsneuroscience的洞察力结合起来,我们的体系结构architecture可以更快、更容易地适应和泛化,而不是今天常用的AI方法。
研究主题Researchthemes:数据效率Dataefficiency,任务共性Taskgenerality,神经与认知科学Neuro& cognitive sciences,概念理解Conceptual understanding。
https://www.vicarious.com/ [25]
A.2.3 创始人、团队、顾问和投资者(Founder,Teammates,Advisors and Investors)

斯科特·菲尼克斯D. Scott Phoenix
公司CEO斯科特Scott从宾夕法尼亚大学the University of Pennsylvania获得计算机科学和企业家精神学位BAS in Computer Science andEntrepreneurship。在共同创立Vicarious AI公司前,斯科特曾有一次创业经历:Frogmetrics (Y CombinatorS2008)公司CEO,公司被硅谷知名孵化器Y Combinator收购。之后,他加入风投Founders Fund,成为创始人基金合伙人Residence at Founders Fund企业家。还在OnlySecure (由NetShops持有)和MarchingOrder(本富兰克林Ben Franklin合作伙伴)做CXO。斯科特的设计作品已在16本杂志和3所博物馆,包括费城当代艺术研究所Institute for Contemporary Art in Philadelphia作为其特色。

迪利普·乔治Dileep George
公司CTO迪利普·乔治DileepGeorge本科毕业于印度理工学院,随后来到美国斯坦福大学就读电气工程,同时钻研机器学习。到了第二年,Dileep开始对神经科学产生兴趣,他说“我曾在初中读过很多心理学的书,在本科的时候全放弃了。这种兴趣在研二的时候又突然回来了,这让我开始侧重对神经科学的研究。”George斯坦福大学读博士期间,遇到《人工智能的未来》作者JeffHawkins——硅谷掌上电脑公司Palm创始人(Palm在2011年被惠普收购)。Hawkins是神经科学领域的大牛,和George意气相投,两人在2005年共同创建了一家致力于机器智能的软件公司Numenta。George不满足于对神经科学和机器学习探索,所以2010年准备重新创立一家新公司。碰巧那时D.Scott Phoenix也就是Vicarious AI的现任CEO找到了他。Phoenix看中George在神经科学和工程学上的造诣,决定与他一同创建VicariousAI。公司创立初就有明确目标——从人脑获得启发,实现拥有高等智能的A.I.。
顾问Advisors

Prof. Fei-Fei Li李飞飞教授
李飞飞博士是斯坦福AI实验室主任Director of the Stanford AI Lab,也是斯坦福大学副教授Associate Professor at Stanford。加入斯坦福前,她在普林斯顿大学Princeton University和伊利诺伊大学香槟分校University ofIllinois Urbana-Champaign任教。飞飞和她同事们的研究已发表在顶级期刊和会议top-tierjournals and conferences上,如自然Nature、美国科学院学报PNAS、神经科学杂志Journal of Neuroscience、计算机视觉和模式识别CVPR、计算机视觉国际会议ICCV、神经信息处理系统大会NIPS、欧洲计算机视觉国际会议ECCV、计算机视觉国际期刊IJCV、国际电子技术与信息科学工程师协会IEEE等。飞飞是2011 Alfred Sloan Faculty Award阿尔弗雷德斯隆特许奖,2012Yahoo Labs FREP award雅虎实验室教师研究与参与计划奖,2009 NSF CAREERaward美国国家科学基金会“杰出青年教授奖”奖,2006 Microsoft Research NewFaculty Fellowship微软研究院新教师奖学金和一些谷歌研究奖Google Research award。

Prof. Bruno Olshausen布鲁诺·奥尔斯豪森教授
奥尔斯豪森Olshausen教授是加州大学伯克利分校UC Berkeley理论神经学Theoretical Neuroscience的红木中心主任Director of the Redwood Center,也是海伦威尔神经系统研究所theHelen Wills Neuroscience Institute的教授。他供职于视觉研究和计算神经科学Vision Research and the Journal ofComputational Neuroscience杂志编辑委员会,并在2004年担任戈登感官编码和自然环境研究会议the Gordon Research Conference on Sensory Coding and the NaturalEnvironment主席。在2002年,他共同编辑了认知和大脑功能的概率模型Probabilistic Models ofPerception and Brain Function(MIT Press麻省理工学院出版社)。

Prof. Alan Yuille艾伦·尤伊尔教授
尤伊尔Yuille教授是加州大学洛杉矶分校UCLA认知、视觉和学习中心the Center for Cognition,Vision,and Learning主任,也是统计系Department of Statistics教授,并在心理学Psychology、计算机科学Computer Science和精神病学系Psychiatry的礼节性任命courtesy appointments。隶属于加州大学洛杉矶分校斯塔林认知神经科学中心the UCLA Staglin Center for Cognitive Neuroscience,大脑、心智和机器中心the Center for Brains,Minds and Machines,以及美国国家科学基金计算、视觉的硅皮层考察组the NSF Expedition in Computing,VisualCortex On Silicon。
投资者Investors:马克·扎克伯格Mark Zuckerberg,杰夫·贝佐斯Jeff Bezos,马克·贝尼奥夫MarcBenioff,创始人基金FoundersFund,好风投GoodVentures,科斯拉风险投资KhoslaVentures,三星Samsung,瑞士苏黎世ABB集团ABB。
B递归皮层网络RCN识别文本CAPTCHAs的Science论文翻译 (14372字)
递归皮层网络RCN识别文本CAPTCHAs的Science论文翻译
文|D.George*,W. Lehrach等,译|秦陇纪,2018-06-22Fri-07-28Sun综合汇编
概率生成模型PGM递归皮层网络RCN识别文本CAPTCHAS的Science论文的译文概述、相关程序等,原文网址如下http://science.sciencemag.org/content/early/2017/10/25/science.aag2612。
论文题目:A generative vision model that trains with high data efficiency andbreaks text-based CAPTCHAs 高数据效率训练的和文本CAPTCHAs (CompletelyAutomated Public Turing Test to Tell Computers and Humans Apart全自动区分计算机和人类的图灵测试)断字的生成视觉模型
作者和从属关系authorsand affiliations:D. George*,W. Lehrach,K. Kansky,M. Lázaro-Gredilla*,C. Laan,B. Marthi,X. Lou,Z. Meng,Y. Liu,H. Wang,A. Lavin,D. S. Phoenix
↵*Corresponding author. Email:[email protected] (D.G.); [email protected] (M.L.-G.)
通讯地址:Vicarious AI, 2 Union Square, Union City,CA 94587, USA.
出版日期和编号:Science 08 Dec 2017: Vol. 358, Issue 6368,eaag2612; DOI: 10.1126/science.aag2612.
摘要Abstract:从很少例子few examples中学习并泛化到戏剧性不同的情况dramatically differentsituations是人类视觉智能human visualintelligence的能力,也与领先的机器学习模式leading machine learning models相匹配。通过从系统神经学systems neuroscience中汲取灵感,我们引入了一种视觉概率生成模型probabilistic generative model for vision,采用基于消息传递的推理message-passing based inference以统一方式处理识别recognition,分割segmentation和推理reasoning。该模型展示了良好的泛化generalization和遮挡推理occlusion-reasoning能力,在具有挑战性的场景文本识别基准scene textrecognition benchmark上优于深层神经网络deep neural networks,同时提高了300倍300-fold的数据效率。此外,该模型采用无特定CAPTCHA验证码启发式算法without CAPTCHA-specific heuristics的生成型分割字符segmentingcharacters,从根本上打破了现代文本CAPTCHAs(text-based CAPTCHAs)的防御。我们的模型强调了数据效率data efficiency和组合性compositionality的一些方面,在迈向通用人工智能general artificialintelligence的道路上可能很重要。
Learningfrom few examples and generalizing to dramatically different situations arecapabilities of human visual intelligence that are yet to be matched by leadingmachine learning models. By drawing inspiration from systems neuroscience,we introduce a probabilistic generativemodel for vision in which message-passing based inference handles recognition,segmentation and reasoning in a unifiedway. The model demonstrates excellent generalization and occlusion-reasoningcapabilities,and outperforms deep neural networks on achallenging scene text recognition benchmark while being 300-fold more dataefficient. In addition,the model fundamentally breaks the defenseof modern text-based CAPTCHAs by generatively segmenting characters withoutCAPTCHA-specific heuristics. Our model emphasizes aspects like data efficiencyand compositionality that may be important in the path toward generalartificial intelligence.
出版日期:Science 26 Oct 2017:eaag2612;文献编号:DOI: 10.1126/science.aag2612;科促会AAAS登录:科技促进会登录AAAS login为科促会员AAAS members提供访问科学Science期刊的机会,并向购买了个人订阅individual subscriptions的用户访问科学Science期刊家族中的其他期刊。美国科学促进会(American Association for the Advancementof Science简称AAAS科促会)成立于1848年,是世界上最大的科学和工程学协会联合体,也是最大非盈利性国际科技组织,下设21个专业分会,涉及学科包括数学、物理、化学、天文、地理、生物等自然科学和社会科学。现有265个分支机构和1000万成员。其年会是科学界重要聚会,近年来,每次年会都能吸引数千名科学家和上千名科学记者参加。美国科学促进会是《科学》杂志的主办者、出版者。《科学》杂志是世界发行量最大的具有同行评议的综合科学刊物,读者逾百万。https://baike.baidu.com/item/%E7%BE%8E%E5%9B%BD%E7%A7%91%E5%AD%A6%E4%BF%83%E8%BF%9B%E4%BC%9A/7389689
类似文章SimilarArticles in: PubMed (一个提供生物医学方面的论文搜寻以及摘要,并且免费搜寻的数据库。它的数据库来源为MEDLINE。其核心主题为医学,但亦包括其他与医学相关的领域,像是护理学或者其他健康学科。)、Google Scholar (谷歌学者)。
引用文章CitingArticles in: Web of Science科学网(2)、Scopus (一个新的导航工具,它涵盖了世界上最广泛的科技和医学文献的文摘、参考文献及索引。)(3)

从一些例子中学习learn和泛化generalize能力是人类智慧human intelligence的标志(1)。CAPTCHAs,网站用来阻止自动交互的图像,是人类容易但计算机难以解决的问题的个例。CAPTCHAs很难用于算法,因为它们将杂乱和众包字母组合在一起,为字符分类器创建鸡蛋问题chicken-and-egg problem——分类器适用于已经分割出来的字符,但是对单个字符进行分段需要理解字符,每个都可以按组合数方式呈现(2-5)。最近解析一种特定CAPTCHA风格的深度学习方法需要数以百万计的标记示例labeled examples(6),而早期方法主要依靠手工特定类型启发法hand-crafted style-specific heuristics来分割出字符character(3,7);而人类可以在没有明确训练的情况下解决新的类型new styles(图1A)。图1显示了各种各样的字形可以呈现并且仍然被人们理解的方式。

图1.人类在字母形式上感知的灵活性。(A)人类擅长解析不熟悉的字体。(B)相同的字母可以有很多的表现形式,人类可以从上图中识别出“A”。(C)常识和上下文信息会影响人类对字体的感知:(i)“m”还是“u”或“n”; (ii)同样的线条中,不同位置上的遮挡会影响对其理解为“N”还是“S”; (iii)对形状的感知会帮助识别图中的“b,i,s,o,n”和“b,i,k,e”。
建立远远超出其训练分布范围的模型是道格拉斯·霍夫斯塔特DouglasHofstadter所设想的灵活性flexibility的重要一步,他说“对于任何能够处理具有人类灵活性字形letterforms的程序,它必须拥有全人工智能full-scale artificial intelligence”(8)。许多研究人员推测,这可以通过利用神经科学neuroscience和认知科学cognitive science研究产生的大量数据来结合视觉皮层visual cortex的诱导偏差inductive biases(9-12)来实现。在哺乳动物大脑mammalian brain中,视觉皮层中的反馈连接feedback connections在图形-地面-分割figure-ground-segmentation中发挥作用,并在基于对象的自上而下object-based top-down的注意力中,即使当部分透明物体占据相同空间位置spatial locations时,也会隔离物体的轮廓(13-16)。视觉皮层中的横向连接Lateral connections与强制轮廓连续性enforcing contour continuity有关(17,18)。轮廓Contours和表面surfaces使用相互作用的独立机制(19-21)来表示,使得能够识别和想象具有不寻常外观的物体——例如冰制椅子。皮质激活时间和地域timing and topography of cortical activations提供了关于轮廓表面表征和推理算法contoursurfacerepresentations and inference algorithms的线索(22,23)。这些基于皮质功能的见解尚未纳入领先的机器学习模型。
我们引入一种称为递归皮层网络Recursive Cortical Network(RCN)的分层模型hierarchical model,该模型将这些神经科学见解neuroscience insights纳入结构化概率生成模型structured probabilisticgenerative model框架(5,24-27)。
除了开发RCN及其学习和推理算法learning and inference algorithms之外,我们还将模型应用于各种视觉认知visual cognition任务,这些任务需要从一个或几个训练样例中进行泛化generalizing:解析CAPTCHAs,一次性one-shot和几次few-shot识别以及手写生成数字digits,遮挡推理occlusion reasoning和场景文本识别scene text recognition。然后,我们将其性能与最先进的模型state of the art models进行了比较。
B.1递归皮质网络Recursive cortical network
RCN以重要的方式建立在现有组合模型compositional models(24,28-32)上[(33)第6节]。尽管基于语法的模型grammar based models(24)具有基于语言学linguistics中众所周知的优点,但它们要么将解释限制为单个的树single trees,要么在使用归属关系attributed relations时计算上不可行(32)。关于AND-OR模板AND-OR templates和树状成分模型tree-structured compositional models(34)的开创性工作seminal work具有简化推理simplified inference的优点,但由于没有横向约束lateral constraints而缺乏选择性selectivity(35)。来自另一个重要类(25,29)的模型使用横向约束,但不是通过池化结构pooling structure逐渐建立不变性invariance(36),而是使用参数变换parametrictransformations在每个级别进行完全缩放complete scale,旋转rotation和平移不变性translation invariance。需要自定义推理算法Custom inference algorithms,但这些算法不能有效地传播横向约束的影响超出局部交互local interactions。(37)中的轮廓contours和曲面surfaces的表征representation不对它们的相互作用建模,而是选择将它们建模为独立的机制independent mechanisms。RCN和组合机器Composition Machines(CM)(32)分享将组合模型思想compositional modelideas放置在图形模型公式graphical model formulation中的动机。然而,CM的“组合分布composed distributions”的代表性选择——使用单层随机变量来折叠collapse特征检测feature-detection,池化pooling和横向协调lateral coordination——导致扩展的状态空间expanded statespace,从而将模型约束为贪心推理greedyinference和解析处理parsingprocess。一般而言,由于表征选择representational choices的变化varied和冲突conflicting,组合模型的推理inference依赖于不同模型实例的定制方法custom-crafted methods,包括求解随机偏微分方程stochastic partial differential equations(30),基于采样的算法samplingbased algorithms(24)和修剪动态规划pruned dynamic programming(29)。
RCN将来自组合模型compositional models的各种思想——分层组合hierarchical composition,渐进构建不变性gradual building of invariances,横向连接选择性lateralconnections for selectivity,轮廓表面因子分解contoursurface factorization和基于联合解释的解析joint-explanation based parsing——整合并构建到结构化概率图形模型structured probabilistic graphicalmodel中,使信念传播Belief Propagation(38)可以用作主要的近似推理引擎approximateinference engine [(33)第6节]。实验神经科学数据Experimental neuroscience data为代表性选择representationalchoices提供了重要指导[(33)第7节],然后通过实验研究证实这是有益的。我们现在讨论RCN的表征representation及其推理inference和学习learning算法。数学细节Mathematical details在(33)第2至5节中讨论。
B.2表征Representation
在RCN中,对象被建模为轮廓contours和曲面surfaces的组合(图2A)。轮廓出现在曲面的边界处,包括对象轮廓outline和构成对象的曲面之间的边界border。表面Surfaces使用条件随机场Conditional Random Field(CRF)建模,其捕获表面特性变化variations of surface properties的平滑度smoothness。轮廓Contours使用特征的组合层次compositional hierarchy offeatures结构建模(28,39)。轮廓contours(形状shape)和表面surfaces(外观appearance)的因式表示Factoredrepresentation使模型能够识别具有显着不同外观的物体形状,而无需对每种可能的形状shape和外观组合appearance combination进行详尽的训练。我们现在详细描述形状shape和外观表征appearance representations。
![]()
图2. RCN结构。(A)物体边缘和表面分离建模。层级结构生成对象轮廓,条件随机场(Conditional Random Field,CRF)生成表观模型。(B)与节点AND node(实心)表示视觉概念的组成成分,或节点OR node(虚心)表示同一语义的不同变化。(C)使用3层RCN对矩形轮廓建模。第二层的ANDnode用来表示矩形的角,每个角表示为第一层中线条的交汇。(D)使用4层RCN表示字母“A”。
图2B显示了RCN轮廓层次contour hierarchy一个级别内的两个子网subnetworks(黑色black和蓝色blue)。图中填充和空的圆形节点circular nodes是分别对应于特征features和池pools的二进制随机变量binary random variables。每个特征节点feature node对其子池child pools的AND关系进行编码encodes,每个池变量pool variable对其子特征child features的OR进行编码,类似于AND-OR图graphs(34)。横向约束Lateral constraints(表示为矩形“因子节点factor nodes”)协调它们连接的池之间的选择。两个子网络可以对应两个对象或对象部分object parts,共享较低级别的功能lower level-features。
图2C显示了表示正方形square轮廓的三级网络three-level network。最低lowest,中间intermediate和顶部top的各级特征分别代表线段linesegments,角corners和整个正方形entiresquare。每个池变量pool variable汇集pools在“居中centered”特征的不同变形deformations,小翻译small translations,比例变化scale changes等上,从而引入相应的不变性invariances。在没有池pools(图2C中的灰色方块)之间的横向连接的情况下,从表示角的特征节点feature node生成可以产生未对准的线段misaligned line segments,如图3A所示。池之间的横向连接Lateralconnections between the pools通过确保一个池中的特征的选择影响其连接的池中的特征的选择来提供选择性(35),从而创建轮廓变化更平滑的样本samples。横向约束的灵活性通过扰动因子perturb-factor来控制,扰动因子是每级指定的超参数hyperparameter。通过多层特征池化multiple layers of feature pooling,横向连接lateral connections和组合compositions,顶层的特征节点feature node来表示可以通过某种程度的平移translation,缩放scale和变形不变性deformation invariance识别的对象。
![]()
图3.来自RCN的样本。(A)有无横向连接的角部特征的样本。(B)来自字符“A”的样本,用于不同的可变形性设置deformability settings,由池化和横向扰动因子lateralperturb-factors确定,在类似于图2D的3级层次中,其中最低级别特征是边缘。第2列显示了一个平衡设置,其中可变形性deformability分布在各个级别之间,以产生局部变形和全局平移。其他列显示了一些极端配置extreme configurations。(C)立方体的表面CRF相互作用surface-CRFinteraction的轮廓。绿色因子:前景到背景边缘,蓝色:对象内边缘。(D)本图C中立方体形状的不同表面外观样本。[见(33)第3节中CRF参数]
多对象Multiple objects通过共享它们的部分以相同的形状层次shape hierarchy表示(图2B)。当多个父节点multiple parents汇聚converge于单个子特征(图2B中的特征节点feature node“e”)时,当任何父节点处于活动状态(图形模型graphical model中的OR门OR-gate)时,这将是活动的,并且允许子特征成为子节点的一部分。如果证据evidence允许,父母双方都不同于AND-OR图形语法中的独占共享exclusivesharing(24)。即使两个较高级别的特征features共享一些相同的较低级别特征features和池pools,较高级别特征的横向网络lateral networks也会通过为其参与的每个特定更高级别特征制作较低级别功能的副本而保持独立separate,如图2B所示。与成对连接pairwise connections相比,横向网络的父特定副本Parent-specific copies用于实现更高阶的交互,类似于在高阶网络higher-order networks中使用的状态复制机制state copyingmechanism (40)。这也被发现对于消息传递message-passing很重要,以获得准确的结果accurate results,并且让人联想reminiscent到双重分解dual decomposition中使用的技术(41)。RCN网络中的层次结构Hierarchy扮演两个字符。首先,它能够逐渐通过多个层次表示变形deformations,从而在层间传播变化量variation(图3B)。其次,层次结构通过在不同对象之间共享特征features来提供效率(42)。这两者都可以通过共享计算shared computations实现有效的学习learning和推理inference。
表面Surfaces使用成对CRF建模(图3C)。局部表面贴片属性Local surface patch properties (如颜色color,纹理texture或表面法线surface normal)由分类变量categorical variables表示,其变化的平滑性smoothness of variation由横向因子lateral factors(图2中的灰色方块gray squares)强制执行。轮廓层次contourhierarchy生成的轮廓Contours以特定的方式与表面CRF相互作用:轮廓表示signal在对象内和对象与其背景之间发生的表面连续性continuity ofsurfaces的断裂breaks,这是一种受神经生物学neurobiology启发的表征选择representational choice(19)。图3,B和D显示了从RCN生成的样本。
B.3推理Inference
为了解析场景scene,RCN在平铺场景的多个位置维护多个对象实例object instances的分层图hierarchicalgraphs。可以通过该复杂图complexgraph上的最大后验maximumaposteriori(MAP)推断来获得场景的解析,其解释了包括对象身份objectidentities及其分割segmentations[(33)第4节]的最佳联节配置jointconfiguration。虽然RCN网络非常循环loopy,但我们发现消息传递messagepassing(38),其时间表schedule受到视觉皮层visual cortex激活时间timingofactivations的启发(9, 20),导致快速准确的推断inference。输入图像首先通过PreProc,PreProc使用一组Gabor类滤波器bank of Gabor-like filters将像素值pixelvalues转换为边缘似然edgelikelihoods。然后使用在网络中传递的前向和后向消息来识别对应于对象假设object hypotheses的部分分配Partial assignments,并且通过解决对象假设图graph of objecthypotheses上的场景解析问题scene-parsingproblem来找到完整的近似MAP解决方案approximate MAP solution(图4)。前向传递forward pass给出了顶层节点的对数概率logprobability的上限upper-bound。向后传递backwardpass以类似于自上而下的关注过程top-downattentionprocess(43,44)的方式逐个访问高得分的前向传递假设high-scoring forward-pass hypotheses,运行条件推断conditionalinference,假设所有其他节点nodes都关闭以找到近似MAP对象的配置(图4A)。向后传递backward pass可以拒绝许多在前向传递中错误识别的对象假设object hypotheses。
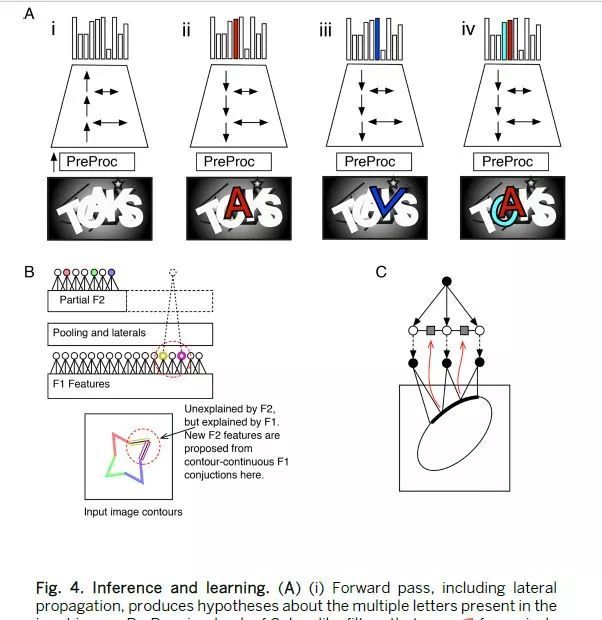
图4.RCN推理和学习算法。(A) (i)通过前向传递,包括侧连接传递,生成字符假设。这里PreProc是一类Gabor算子,生成像素上的边界概率。(ii)反向传递和侧连接传递从之前的假设中选取了“A”。(iii)“A”和“K”之间产生了一个错误的假设“K”,可以通过上下文解析消除错误假设。(iv)多个假设联合解释了图中的字母,包括对分离、遮挡的推理。(B)第二层上的特征学习。着色圆圈代表激活的特征,虚线圆圈代表最终选取的特征。(C)从边缘的相邻结构中学习侧连接。
全局MAP配置是从前向和后向传递passes生成的所有对象假设objecthypotheses的子集subset。场景scene中的对象数量被推断为inferred此最大后验MAP解决方案的一部分。除了搜索一个指数很大的子集数anexponentiallylargenumberofsubsets之外,找到全局MAP还需要推理reasoning不同假设之间的高阶交互high-order interactions。我们开发了一种近似动态规划dynamicprogramming(DP)的方法,可以在线性时间内解决这个问题。DP算法利用每个对象假设占据连续区域contiguous region的事实,该连续区域可以在输入图像上表示为2d掩模mask。通过考虑在其2d掩模重叠时产生空间连续掩模spatiallycontiguousmasks的对象假设(即,解析parses)的组合,我们通过根据包含在其他掩模中的掩模对它们进行排序来创建解析的拓扑排序topologicalordering。这导致得分的递归计算recursivecomputation,其在搜索最佳解析时仅需要评估线性数量的候选解析linearnumberofcandidateparses。有关详细信息,请参阅(33)第4.7节。
B.4学习Learning
直到网络的倒数第二级penultimatelevel的特征Features和横向连接lateralconnections在无人监督的情况下使用通用3D对象数据集generic3Dobjectdataset进行训练,该通用3D对象数据集是任务不可知的agnostic并且仅被渲染为rendered轮廓图像contourimages。由此产生的学习特征learnedfeatures从较低级别的简单线段simplelinesegments到较高级别的曲线curves和角corners不等。
考虑一个部分学习模型partially learned model,其中在levelk级学习新特征,其中已经学习并最终确定了达到levelk-1级的特征,并且已经在levelk 级学习了一些特征(图4B)。当呈现训练图像trainingimage时,第一步是使用级别k处的现有特征来查找该图像的轮廓的MAP解释。这与前面描述的为场景找到MAP解决方案的推理问题相同。使用k-1级的特征解析仍然无法解释的轮廓,并从它们的轮廓连续连接contour-continuousconjunctions中提出新特征。对所有训练图像重复该过程累积对级别k处的不同特征的使用的计数,并且通过优化平衡压缩balancescompression和重建误差reconstruction error的目标函数objective function来选择该级别的最终特征(31)。同一过程逐级level-by-level重复[见(33)第5.1节]。
横向图结构lateralgraphstructure,是从输入图像的轮廓连通性contourconnectivity中学习,指定specifies池对pool pairs之间的连通性connectivity。在第一个池化级别pooling level,具有在输入轮廓inputcontours中相邻的特征的池彼此连接adjacent。在层次结构hierarchy中递归地recursively重复该过程process,其中较高层的横向连接lateral connections是从较低层图中的邻接adjacency推断的inferred。
最顶层的特征Featuresat the topmost level代表整个对象wholeobjects。这些是通过找到直到网络倒数第二级penultimate level的新对象的MAP配置MAPconfiguration而获得的:根据输入对象的轮廓连续性contourcontinuity在倒数第二级连接池对pool pairs,然后在倒数第二级存储storing激活的连接conjunction of activations作为顶层特征featureinthetop-mostlevel。最顶层的功能。有关详细信息,请参阅(33)第5节。
一旦训练了一组较低级别的特征和横向连接,就可以通过调整一些超参数hyper-parameters来将它们用于不同的域domains [(33)第8.3节]。根据图像和对象大小选择PreProc中的滤波器filter比例scales,并设置横向连接的灵活性flexibility以匹配数据中的失真distortions。另外,最低级别特征具有“平滑参数smoothingparameter”,其设置是由于噪声noise导致边缘像素edgepixel开启ON的概率估计estimateontheprobability。可以根据域domain中的噪声级别noiselevels设置此参数。
B.5结论Results
如果CAPTCHA以高于1%的速率被自动解决,则认为CAPTCHA被破坏(3)。RCN可以用很少的训练数据trainingdata打破各种文本CAPTCHAs,并且不使用CAPTCHA特定启发式方法(图5)。它能够以66.6%的准确率(字符级准确度为94.3%),BotDetect为64.4%,雅虎Yahoo为57.4%和PayPal为57.1%来解决reCAPTCHAs,远远高于CAPTCHA被认为无效的1%率(3)。不同CAPTCHA任务中架构的唯一区别是用于训练的干净字体集sets of clean fonts和一些超参数hyper-parameters的不同选择,这些参数取决于CAPTCHA图像的大小以及杂波clutter和变形deformations的数量。这些参数可以直接手动设置,也可以通过带注释的CAPTCHA集上的交叉验证cross validation自动调整。来自CAPTCHA的嘈杂Noisy,混乱cluttered和变形deformed的例子没有用于训练,但RCN在泛化generalizing这些变化variations方面是有效的。
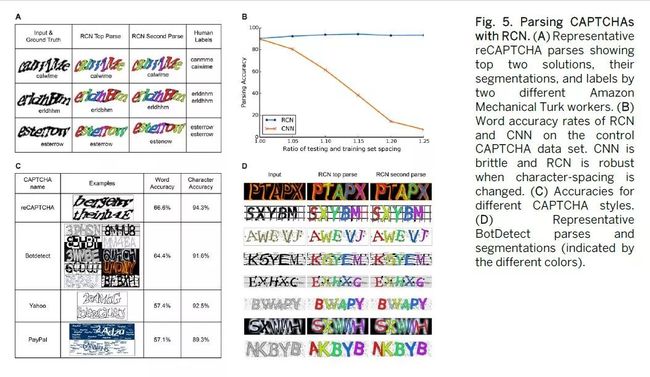
图5.用RCN解析CAPTCHA。(A)代表reCAPTCHA解析两个不同亚马逊机械土耳其工人Amazon Mechanical Turk workers展示的前两个解决方案,他们的隔断segmentations和标签labels。(B) RCN和CNN在控制CAPTCHA数据集上的字词准确率。CNN很脆弱,当字符间距改变时,RCN很强大。(C)不同CAPTCHA样式的准确度。代表性的BotDetect解析和分割(由不同的颜色表示)。
对于准确率为66.6%的reCAPTCHA解析parsing,RCN里每个字符character只需要五个干净的训练样例clean training examples。该模型使用三个参数来影响单个字符如何组合在一起以读出一串字符,这些参数都与CAPTCHA的长度无关,并且对字符间距spacingof thecharacters很稳健 [图5B和(33)的8.4节]。除了获得CAPTCHA转录transcription外,该模型还提供对单个字符的高度准确的分割,如图5A所示。相比之下,reCAPTCHA的人类准确率为87.4%。由于许多输入图像具有多种有效解释validinterpretations(图5A),因此来自两个人的解析仅时间内达成在81%的一致agreeonly81%ofthetime。
与RCN相比,最先进的CNN(6)需要大约50,000倍的实际CAPTCHA字符串训练集,并且对输入的扰动perturbations不太稳健。由于CNN需要大量标记示例labeledexamples,因此该对照研究control study使用我们创建的CAPTCHA生成器来模拟reCAPTCHAs的外观[参见(33)的第8.4.3节]。该方法使用了一组特定位置position-specific的CNN,每个CNN都经过训练以区分特定位置的字母。训练该CNN以实现89.9%的单词准确率word-accuracy rate,需要超过230万个独特训练图像uniquetraining images,用已翻译词句translated crops进行数据增加dataaugmentation,从79,000个不同的CAPTCHA单词创建。由此产生的网络在训练期间不存在字符串长度string lengths失败,更重要的是,网络的识别准确性recognition accuracy迅速恶化,甚至对人类几乎感觉不到的字符间距产生微小扰动minorperturbations——间距增加15%精度降低到38.4%,间距增加25%精度降低到7%。这表明深度学习方法deep-learningmethod学会利用特定CAPTCHA的细节而不是学习随后用于解析场景parsingthescene的字符模型。对于RCN,增加字符的间距可以提高识别精度recognitionaccuracy(图5B)。
BotDetect中各种各样的字符外观character appearances(图5C)说明了为什么轮廓和曲面的分解factorization很重要:没有这种分解的模型可以锁定latch字体的特定外观细节,从而限制了它们的泛化generalization。RCN结果基于对来自BotDetect的10种不同风格的CAPTCHA测试,所有这些都基于每个字符character做24个训练示例训练的单个网络进行解析,并且在所有样式中使用相同的解析参数parsingparameters。尽管BotDetect CAPTCHA可以仅使用轮廓信息contourinformation进行解析,但使用外观信息appearance information可以将准确率从61.8%提高到64.4%,在所有数据集中使用相同的外观模型appearancemodel。有关详细信息,请参阅(33)的8.4.6节。
在标准的MNIST手写数字数据集handwrittendigitdataset[(33)第8.7节]中,RCN在一次性one-shot和几次fewshot分类任务classificationtasks上的表现优于其他模型。我们比较了RCN在MNIST上的分类性能classificationperformance,因为我们将每个类别category的训练样例数从1改为100。CNN与两种最先进的模型进行了比较,即LeNet-5(45)和VGG-fc6 CNN(46),其级别使用数百万张图像进行ImageNet(47)分类预训练pre-trained。选择VGG-CNN的全连接层fully-connected-layer fc6进行比较,因为与其他预训练水平pre-trainedlevels的VGG-CNN相比,它为此任务提供了最佳结果,并与使用相同数据dataset和边缘预处理edgepre-processing为RCN[(33)第33节]的其他预先训练的CNN进行了比较设置。此外,我们还比较了最近报告的关于此任务的最新表现的成分补丁模型Compositional PatchModel(48)。RCN的表现优于CNN和CPM(图6A)。RCN的单点识别性能oneshotrecognitionperformance为76.6%,CPM为68.9%,VGG-fc6为54.2%。RCN对于在测试期间引入的不同形式的杂波clutter也很稳健,而不必在训练期间将网络暴露给那些变换transformations。相比之下,这种样本外的测试实例out-of-sample testexamples对CNN的泛化性能generalizationperformance具有很大的不利影响detrimental effect(图6B)。为了分离横向连接,正向传递和反向传递对RCN准确性的贡献,我们进行了选择性地关闭这些机制mechanisms的病变研究lesion studies。结果总结在图6C中,表明所有这些机制对RCN的性能有显着贡献。具有两级特征检测feature detection和池化pooling的RCN网络足以在字符解析任务characterparsing tasks上获得最佳的准确性性能。增加层次结构中层次数的效果是减少推理时间inference time,如(33)第8.11节所述。
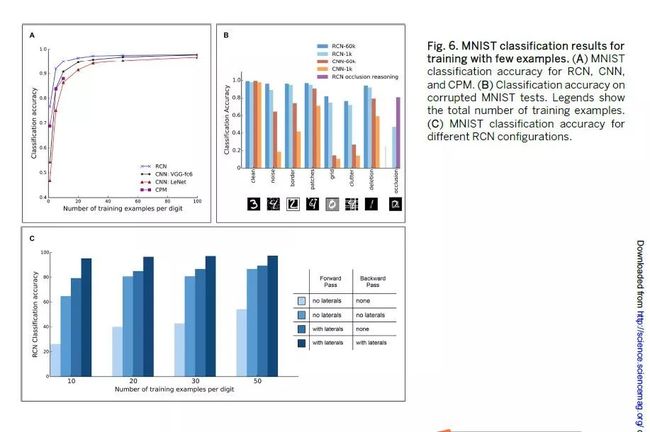
图6.用个别样本训练的MNIST分类结果。(A) RCN,CNN和CPM的MNIST分类准确度。(B)损坏的MNIST测试的分类准确性。插图显示训练样本总数。(C)不同RCN配置的MNIST分类精度。
作为生成模型generative model,RCN在重建损坏的MNIST图像时优于变分自动编码器VariationalAutoEncoders(VAE)(49)和DRAW(50)(图7,A和B)。DRAW对于干净测试集clean test set优于RCN的优势并不令人惊讶,因为DRAW正在学习一种过于灵活的模型,该模型几乎在重建reconstruction中复制输入图像,这会在更混乱的数据集cluttereddatasets上损害其性能[(33)第8.9节]。在Omniglotdata在线语言文字百科数据(1)上,一次性训练one-shot training后从RCN生成的示例显示出显着变化,同时仍然可以识别为原始类别original category[图7D和(33)的8.6节]。
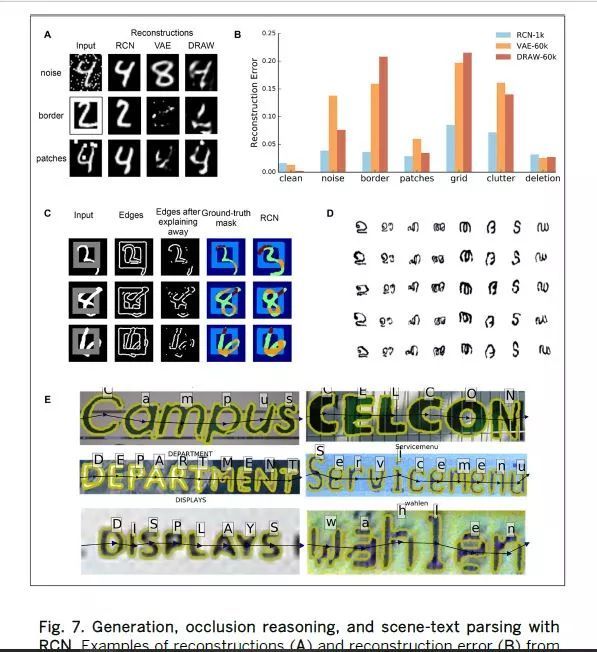
图7.用RCN进行生成,遮挡推理和场景文本解析。在损坏的MNIST上来自RCN,VAE和DRAW的重建(A)和重建误差(B)的样本。插图显示了训练样本数量。(C)遮挡推理。第三列说明了RCN解释第一个检测到的对象边缘后,保留的边缘。地面实况掩模Ground-truth masks反映了正方形和数字之间的遮挡关系。正方形前面的数字部分用棕色表示,正方形后面部分用橙色表示。最后一列显示了预测的遮挡掩模。(D)Omniglot一次性生成。在每列中,第1行显示训练样本,其余行显示生成样本。(E)RCN成功解析ICDAR图像样本。黄色轮廓显示分段。
为了测试遮挡推理occlusion reasoning(51–53),我们通过在每个验证validation/测试test图像中添加一个矩形来创建MNIST数据集的变体,使得数字digit的某些部分被矩形遮挡,并且矩形的某些部分被数字遮挡[图7C和(33)的8.8节]。这些图像中的遮挡关系Occlusionrelationships不能推断deduced为一个对象在另一个对象前的简单分层。对该数据集的分类具有挑战性,因为数字的许多部分被矩形遮挡,并且因为矩形行为杂乱。如果检测到并分割出矩形,则可以使用RCN生成模型解释其对特定数字的证据的影响,从而提高分类classification和分割segmentation的准确性。RCN在这个具有挑战性的数据集上进行了分类准确性和遮挡推理的测试。无解释的分类准确率为47.0%。解释矩形可将分类精度提高到80.7%。另外,RCN用于通过推理reasoning矩形和数字之间的遮挡关系来解析场景。该模型成功地预测了测试图像的精确遮挡关系precise occlusionrelations,如图7C所示,获得了在遮挡区域occludedregions上测量的0.353的平均交会intersection overunion(IOU)。
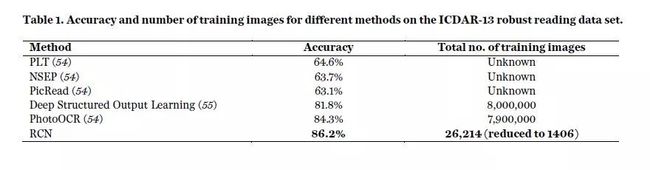
最后,RCN在ICDAR-13稳健读数数据集Robust Readingdata set(54)上进行了测试,这是现实世界图像中文本识别的基准benchmark(图7E)。对于此测试,我们增强了解析算法parsingalgorithm,以包括有关n-gram和单词统计wordstatistics的先验知识priorknowledge,以及与场景中字母布局layoutofletters相关的几何先验geometric priors,包括间距spacing,相对大小relative sizes和外观一致性appearance consistency [参见(33)第8.5节]。我们将我们的结果与ICDAR竞赛的最高参与者以及最近的深度学习方法(55)进行了比较(表1)。尽管PhotoOCR使用了790万个训练图像,但RCN模型的表现优于顶级竞争者PhotoOCR 1.9%,而RCN使用了来自25,584个字体图像fontimages的基于模型的聚类model-basedclustering选择的1,406个训练图像。除了提供竞争方法无法提供的字符characters的详细分段detailed segmentation(图7E)外,RCN在此任务上实现了更高的准确性,同时数据效率dataefficient提高了300倍。
表1. ICDAR-13鲁棒读数数据集上不同方法的训练图像的准确度和数量。r different methods on the ICDAR-13 robust reading data set.
B.6讨论Discussion
分段阻抗Segmentation resistance是基于文本CAPTCHA的主要防御,它是实现自动生成的一般原则general principle(2,3))。尽管在用特定样式的分段启发式法style-specific segmentationheuristics前已经破坏了特定CAPTCHA(3,7),但这些攻击可以通过对CAPTCHA的微小改动minoralterations而轻易地被挫败。RCN以一种基本方式打破了分段防御segmentation defense,并且只有非常少的训练数据,这表明网站应该采用更强大的机制来阻止阻抗机器人程序blocking bots。
成分模型Compositional models过去已成功用于通用对象识别generic object recognition和场景解析scene parsing,我们的初步实验preliminary experiments[(33)第8.12节]表明RCN也可适用于这些领域(图8)。RCN公式为在图形模型中开发更广泛的高级推理inference和学习learning算法打开了组合模型,可能导致在现实世界场景解析real-world sceneparsing中基于其先前成功的改进(56,57)。尽管作为生成模型的优势,RCN需要若干改进才能在ImageNet规模(47)数据集上实现卓越性能。灵活地合并多个实例,在前向和后向推理inference期间在层次结构的所有级别使用表面外观,学习通过3D变形池化更复杂池化结构sophisticated pooling structures,以及场景上下文scene context和背景background的生成建模需要调查investigated并与RCN整合的问题[(33)第8.13节]。

图8.解析有对象场景的RCN应用。示出了当RCN应用于具有随机背景上的杂乱场景中的多个真实世界对象的场景解析任务时获得的检测和实例分割。我们的实验表明RCN可在文本解析外进行推广[参见(33)第8.12节和讨论]。
与CNN和VAE等全图像模型whole-image models相比,RCN的高数据效率源于RCN在其结构中对强假设strong assumptions做编码encodes的事实。最近的神经网络模型使用空间关注窗口spatial attentionwindow(58)结合了组合性的想法,但是它们的当前实例需要在整洁的设置uncluttered setting中良好地分离对象,因为每个关注窗口使用整个图像VAE建模。将RCN的对象和基于部分的组合性part-based compositionality结合到神经网络模型中将是一个有趣的研究方向。与神经网络不同,当前版本的RCN学习算法需要干净的训练数据,这是我们打算使用基于梯度的学习gradient based learning以及基于消息传递方法messagepassing based approaches解决的一个弊端drawback(59)。
将RCN与贝叶斯程序学习Bayesian ProgramLearning(BPL)(1)相结合是未来调研的另一种途径。BPL具有精确建模顺序因果机制sequentialcausal mechanisms的优点,例如Omniglot数据集中的笔划生成stroke generation,但其推断inference取决于轮廓contours与背景background分离——RCN可以轻松提供。更一般地,可以组合BPL和类RCN图形模型RCN-likegraphical models以获得模拟涉及感知perception和认知cognition的并行parallel和顺序过程sequential processes(60)所需的表达能力expressive power和有效推断efficient inference。
当然,DouglasHofstadter的挑战——理解具有相同效率和灵活性的字形letterforms——仍然是人工智能的宏伟目标。当人们识别字形时,人们会以上下文敏感contextsensitive和动态dynamic的方式使用更多常识知识commonsense knowledge(图1C,iii)。我们的工作表明,结合系统神经科学的归纳偏差inductivebiases可以产生强大、可泛化的generalizable机器学习模型,展示出高数据效率。我们希望这项工作能够激发改进的皮层电路模型corticalcircuits(61,62)以及将神经网络和结构化概率模型structuredprobabilisticmodels的功能与通用人工智能系统generalartificialintelligencesystems相结合的研究。
B.7方法总结Methods summary
对于reCAPTCHA实验,我们从google.com的reCAPTCHA页面下载了5500个reCAPTCHA图像,其中500个用作参数调整parametertuning的验证集validationset,并在剩余5000个上报告准确度数字accuracynumbers。图像按2倍因子放大了比例。通过与本地系统上可用字体的视觉比较,识别出格鲁吉亚Georgia reCAPTCHA中使用的类似字体similar-lookingfont。RCN接受了这种字体的小写和大写字符的几次旋转rotations训练。使用验证集优化超参数。用美国工人,使用亚马逊机械土耳其人AmazonMechanicalTurk(AMT)估算reCAPTCHA数据集的人工准确性。
使用Image-Magick创建用于训练神经网络进行对照实验control experiments仿真reCAPTCHA数据集,以产生与原始reCAPTCHA定性相似的qualitativelysimilar失真distortions。仿真数据生成器用作无限源unlimited source,以生成用于训练神经网络的随机批次。神经网络优化Neural networkoptimization运行了80期epochs,其中数据在每期开始时被置换permuted;通过每期每个基本方向cardinaldirection上最多5像素的随机翻译来增强数据。类似方法用于BotDetect,PayPal和YahooCAPTCHAs。对于BotDetect,我们下载了每个CAPTCHA样式50-100个图像的数据集,用于确定解析参数parsing parameters和训练设置training setup,另外100个图像作为未调整网络的测试数据集。作为系统的训练图像,我们通过直观地比较BotDetect CAPTCHAs的几个示例,从系统中可用的那些中选择了一系列字体和比例。BotDetect测试图像按1.45倍的因子重新调整。使用验证集优化解析参数,并通过分别适配adapting每种样式的参数来测试解析参数的可转移性transferability,然后在其他样式上测试这些参数。
为了训练RCN解析ICDAR,我们从谷歌字体中获得了492种字体,产生了25584个字符的训练图像。由此我们使用自动贪婪字体选择方法automatedgreedyfontselectionapproach选择了一组训练图像。我们为所有字体渲染了二进制图像,然后使用相同字母的结果图像来训练RCN。然后,该RCN用于识别其训练的精确图像,为相同字母的所有字体对提供兼容性分数compatibilityscore(在0.0和1.0之间)。最后,使用阈值threshold(=0.8)作为停止标准stoppingcriterion,我们贪婪地选择最具代表性的字体,直到所有字体的90%被表示,这导致776个独特的训练图像。使用630个单词图像训练解析器,并使用来自维基百科Wikipedia的单词训练字符characterngrams。
对MNIST数据集的RCN分类实验classificationexperiments是通过将该图像按4倍因子上采样up-sampling来完成的。对于每个训练设置,使用旋转的MNIST数字的独立验证集independentvalidation set来调整模型的两个池化超参数pooling hyperparameters。作为基线baselines的一部分,探索了几种预训CNN的方法。为了理解网络在嘈杂的MNIST数据上的性能,我们创建了六种噪声变体,每种变体具有三个严重级别levels of severity。对于遮挡推理occlusionreasoning,RCN网络训练有11个类别:10个MNIST数字类别digitcategories带20个类别示例,和矩形环类别rectangularringcategory带一个例子。在MNIST数据集上的重建实验Reconstructionexperiments使用仅在干净的MNIST图像上训练的网络,然后测试6种不同噪声变体noise variants的均方重建误差meansquaredreconstructionerror,每种噪声变化具有3个严重级别。补充材料supplementalmaterials中提供了完整方法Fullmethods。
B.8参考文献和笔记REFERENCES AND NOTES
1. B. M. Lake, R. Salakhutdinov, J. B. Tenenbaum,Human-level conceptlearningthrough probabilistic program induction. Science 350, 1332–1338(2015).doi:10.1126/science.aab3050Medline
2. K.Chellapilla,P.Simard,“Usingmachinelearningtobreakvisualhumaninteractionproofs (HIPs),” in Advances in Neural Information ProcessingSystems 17)(2004)pp.265–272.
3. E. Bursztein, M. Martin, J.C. Mitchell, “Text-based CAPTCHA strengthsandweaknesses,” in Proceedings of the18th ACM Conference on ComputerandCommunicationsSecurity(ACM,2011),pp.125–138.
4. G.Mori,J.Malik,“Recognizingobjectsinadversarialclutter:BreakingavisualCAPTCHA,”in2003IEEEConferenceonComputerVisionandPatternRecognition(IEEEComputerSociety,2003),pp.I-134–I-141.
5. V.Mansinghka,T.D.Kulkarni,Y.N.Perov,J.Tenenbaum,“Approximatebayesianimage interpretation using generative probabilisticgraphics programs,”inAdvances in Neural Information ProcessingSystems 26 (2013), pages1520–1528.
6. I.Goodfellow,Y.Bulatov,J.Ibarz,S.Arnoud,V.Shet,“Multi-digitnumberrecognitionfromstreetviewimageryusingdeepconvolutionalneuralnetworks,” paperpresentedattheInternationalConferenceonLearningRepresentations(ICLR)2014,Banff,Canada,14to16April2014.
(全部108个引文请下载PDF完整版)
下期预告:《递归皮层网络RCN识别文本CAPTCHAS要点梳理、论文代码及测试》(有时间细读此文,并愿意继续研究论文对应代码,请在https://github.com/vicariousinc/science_rcn自行下载,下期文章重点实现论文代码及测试。)
递归皮层网络RCN不但可以识别文本CAPTCHAs,还可以在其他有边界或规律特征的图像做识别,这是否意味着迈向了通用人工智能?是否可展望以深度学习为代表的初级人工智能技术,就此转型,向着可解释、通用的人工智能发展?欢迎大家在主编秦陇纪的“科学Sciences”AI群做讨论。
-END-
参考文献(1068字)
1. 创建者:lirongxu128, 人工智能.[EB/OL] 百度百科, https://baike.baidu.com/item/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/9180,2018-06-11.
2 Wikipedia, Reasoningsystem.[EB/OL] Wikipedia, https://en.wikipedia.org/wiki/Reasoning_system,2018-06-21(UTC).
(字数限制,其余请下载PDF完整版)
42.Vicarious AI. Generative Models.[EB/OL] vicarious AI,https://www.vicarious.com/2017/10/26/common-sense-cortex-and-captcha/, 2017-10-26.
43.https://drive.google.com/drive/folders/0B-NDEl5vehB8dEJadmhPellyYWc
x. 秦陇纪. 数据科学与大数据技术专业概论;人工智能研究现状及教育应用; 纯文本数据神经网络训练; 大数据简化之技术体系. [EB/OL]数据简化DataSimp(微信公众号), http://www.datasimp.org, 2017-06-06.
概率生成模型PGM递归皮层网络RCN识别文本CAPTCHAS的Science论文 (35530字)
秦陇纪
简介:递归皮层网络RCN识别文本CAPTCHAS的Science论文基础知识和译文。(公号回复“递归皮层网络”或“RCN”,文末“阅读原文”下载22图70k字28页PDF典藏版资料) 蓝色链接“数据简化DataSimp”关注后下方菜单项有文章分类页。作者:秦陇纪、D. George等。来源:VicariousAI公司、Science论文、维基百科、百度知乎、数据简化社区秦陇纪微信群聊公众号,引文出处请看参考文献。主编译者:秦陇纪,数据简化社区、科学Sciences、知识简化新媒体创立者,数据简化OS设计师、C/Java/Python/Prolog程序员,IT教师。版权声明:科普文章仅供学习研究,公开资料©版权归原作者,请勿用于商业非法目的。秦陇纪2018数据简化DataSimp综合汇译编,投稿合作,或出处有误、侵权、错误或疏漏(包括原文错误)等,请联系[email protected]沟通、指正、授权、删除等。每天十几万字中英文阅读、几万字文章汇译编、时间精力人力有限,欢迎转发、赞赏、加入支持社区。欢迎转发:“数据简化DataSimp、科学Sciences、知识简化”新媒体聚集专业领域一线研究员;研究技术时也传播知识、专业视角解释和普及科学现象和原理,展现自然社会生活之科学面。秦陇纪发起未覆盖各领域,期待您参与~~ 强烈谴责超市银行、学校医院、政府公司肆意收集、滥用、倒卖公民姓名、身份证号手机号、单位家庭住址、生物信息等隐私数据!
Appx(626字).数据简化DataSimp社区简介
信息社会之数据、信息、知识、理论持续累积,远超个人认知学习的时间、精力和能力。应对大数据时代的数据爆炸、信息爆炸、知识爆炸,解决之道重在数据简化(Data Simplification):简化减少知识、媒体、社交数据,使信息、数据、知识越来越简单,符合人与设备的负荷。数据简化2018年会议(DS2018)聚焦数据简化技术(Data Simplification techniques):对各类数据从采集、处理、存储、阅读、分析、逻辑、形式等方ose 做简化,应用于信息及数据系统、知识工程、各类数据库、物理空间表征、生物医学数据,数学统计、自然语言处理、机器学习技术、人工智能等领域。欢迎投稿数据科学技术、简化实例相关论文提交电子版(最好有PDF格式)。填写申请表加入数据简化DataSimp社区成员,应至少一篇数据智能、编程开发IT文章:①高质量原创或翻译美欧数据科技论文;②社区网站义工或完善S圈型黑白静态和三彩色动态社区LOGO图标。论文投稿、加入数据简化社区,详情访问www.datasimp.org社区网站,网站维护请投会员邮箱[email protected]。请关注公众号“数据简化DataSimp”留言,或加微信QinlongGEcai(备注:姓名/单位-职务/学校-专业/手机号),免费加入投稿群或”科学Sciences学术文献”读者微信群等。长按下图“识别图中二维码”关注三个公众号(搜名称也行,关注后底部菜单有文章分类页链接):
数据技术公众号“数据简化DataSimp”:

科普公众号“科学Sciences”:

社会教育知识公众号“知识简化”:

(转载请写出处:©秦陇纪2010-2018汇译编,欢迎技术、传媒伙伴投稿、加入数据简化社区!“数据简化DataSimp、科学Sciences、知识简化”投稿反馈邮箱[email protected]。)
普及科学知识,分享到朋友圈

转发/留言/打赏后“阅读原文”下载PDF
阅读原文

微信扫一扫
关注该公众号