由于最近自己写点小东西,需要有工作流程管理方面的应用,所有的环境为Ruby on rails,所有在选择流程引擎的时候选择了ruote,但是对于ruote是完全陌生的,所以在这里记下点滴,如果理解的不正确,还请大家批评指正。
Ruote:用Ruby写的一个工作流引擎。
开始了解Ruote先要了解几个很重要的概念:
- storage 是ruote的核心,保存这所有的持续流程。Storage实现线程安全,多个工作可以同时使用。
- worker 围绕在Storage周围的流程本省。
- engine(dashboard) 包含一些图标和按钮,是所有进程实例的控制面板,能够对进程实例就行运行,暂停,取消操作。
下面是一个Ruote的配置:
1 require 'ruote' 2 require 'ruote/storage/fs_storage' 3 4 engine = Ruote::Engine.new(Ruote::Worker.new(Ruote::FsStorage.new('work')))
这是一个最简单的配置,将engin,worker和storate包装在一起。
Engine的配置选项实际上是在初始化的时候传递给存储的,比如:
1 require 'ruote' 2 require 'ruote/storage/fs_storage' 3 4 engine = Ruote::Engine.new( 5 Ruote::Worker.new( 6 Ruote::FsStorage.new( 7 'work', 8 'remote_definition_allowed' => true, 'ruby_eval_allowed' => true)))
也可以向下面这样定义:
1 engine = Ruote::Engine.new( 2 Ruote::Worker.new( 3 Ruote::FsStorage.new('work'))) 4 5 engine.configure('remote_definition_allowed', true) 6 engine.configure('ruby_eval_allowed', true)
Engin的配置项:
participant_threads_enabled(自从ruote2.3.0版本开始,默认情况是true)
默认情况下, 从work中调度一个流程给参与者的时候都用一个新的Ruby线程。这样在默认情况下不会阻塞worker。
remote_definition_allowed(默认情况下是false)
Remote definitions 是通过Http协议过程定义。因为过程定义是代码,默认情况下用如下方法是不允许的:
1 Ruote.process_definition :name => 'main process' do 2 sequence do 3 subprocess 'http://example.com/definitions/head_process.rb' 4 subprocess 'http://example.com/definitions/tail_process.rb' 5 end 6 end 7 8 # or 9 10 engine.variables['head'] = 'http://example.com/definitions/head_process.rb' 11 engine.variables['tail'] = 'http://example.com/definitions/tail_process.rb' 12 13 Ruote.process_definition :name => 'main process' do 14 sequence do 15 head 16 tail 17 end 18 end 19 20 # or simply 21 22 engine.launch('http://example.com/definitions/main.xml')
如果要使用如上的定义,那么应该将‘remote_definition_allowed的选项设置为"true"。
ruby_eval_allowed:(默认是false)
wait_logger_max:(默认是147)
这个设置只是在开发测试环境中一个worker的情况,在其他环境下不用管这个配置。WaitLogger是ruote的一个组件,追踪147个最近的本地工作流程的处理信息。 preserve_configuration:(默认是false)
当这个配置设置为true的时候,engine,worker,storage将不向存储后面持续工作流程写配置。适用于多个工作流程一起运行的情境下。
restless_worker:(默认是false)
更像是一个工作流程的配置,当设置为true的时候,工作流程在提取信息和定时调度执行期间就不会sleep。
worker_state_enabled:(默认是false)
当设置为true的时候,将Ruote::Dashboard中的worker_state解锁,可能的状态包括running,paused,stopped.工作流读取状态执行相应的running,paused,stop操作。
engine on_error / on_terminate:
engine在发生错误和终止的时候触发的事件或者参与者,如下定义:
1 # you can pass a participant name 2 engine.on_error = 'administrator' 3 4 # or a subprocess name 5 engine.on_error = 'error_procedure' 6 7 # or directly a subprocess definition 8 engine.on_error = Ruote.define do 9 concurrence do 10 administrator :msg => 'something went wrong' 11 supervisor :msg => 'something went wrong' 12 end 13 end
worker:
目前为止,没有为worker的配置。
storage:
工作流、业务处理被人调用,持续好长时间,数据的持久性是必须的,storage用来保存数据。因为所有的工作流程共享storage,所以不仅要提供可靠的持久数据,而且可以避免工作流之间的冲突。
下面这个表中是实现的storage类型:
multiple workers:storage是否支持多个工作流程。
remote worker:现实工作流程是不是和storage在一个主机上
speed :显示storage的速度排行。
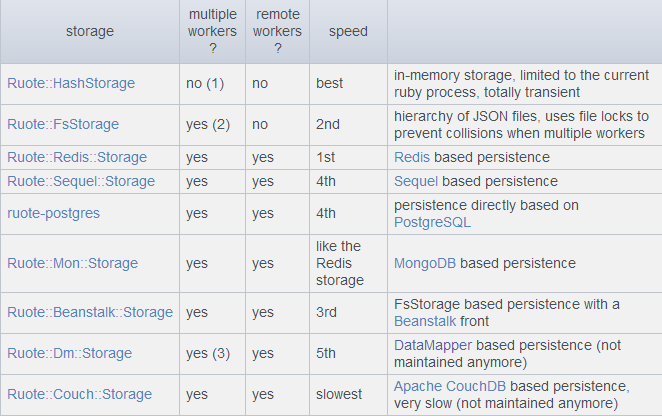
Ruote::HashStorage:
一个字内存中临时的storage,不能够在多个工作流程中共享,大多数用于测试或者临时的工作流程。
Ruote::FsStorage:
以json的格式将ruote的信息保存成文件,可以在多个工作流程中共享数据。
Ruote::Redis::Storage:
基于redis的storage,很快,在多个工作流程的情况下使用。
Ruote::Sequel::Storage:
通用的持久storage,使用Mysql或者PostgreSQL,在多个工作流程的情况下使用。
Ruote::Dm::Storage:
一个 DataMapper storage 实现。
Ruote::Couch::Storage:
一个基于 CouchDB 的Storage实现。
Ruote::Mon::Storage:
MongoDB storage 实现。
Ruote::Beanstalk::BsStorage:
提供一种技术,使FsStorage可以被远程的工作流程可以使用。
十分想找对ruote熟悉的朋友共同学习。