Keras搭建神经网络进行二分类预测是否存款,带运行效果及评测图
数据来源:http://archive.ics.uci.edu/ml/datasets/Bank+Marketing
开发工具:Jupyter notebook
语言版本:python 3.6
1.数据读入及特征工程
import numpy as np
import pandas as pd
from sklearn import preprocessing
%matplotlib inline
from matplotlib import pyplot as plt
data = pd.read_csv("D:\\bank-full.csv",sep = ';')
test = pd.read_csv("D:\\bank.csv",sep = ';')
def get_y_train():
y_train = np.array(data['y'])
y_train = np.where(y_train == 'yes', 0, 1) #将预测值转换成01
return y_train
def get_y_test():
y_test = np.array(test['y'])
y_test = np.where(y_test == 'yes', 0, 1) #将预测值转换成01
return y_test
def get_X_train():
oh_data = pd.get_dummies(data) #对非数值数据进行ont-hot编码
columns_size = oh_data.columns.size
X_train = oh_data.iloc[:,0:columns_size-2] #取特征
X_train = preprocessing.scale(X_train) #归一化
return X_train
def get_X_test():
oh_test = pd.get_dummies(test) #对非数值数据进行ont-hot编码
columns_size = oh_test.columns.size
X_test = oh_test.iloc[:,0:columns_size-2] #取特征
X_test= preprocessing.scale(X_test) #归一化
return X_test
X_test = get_X_test()
X_train = get_X_train()
y_test = get_y_test()
y_train = get_y_train()2.模型建立
from keras.layers import Dense,LSTM,Dropout
from keras.models import Sequential
from keras import optimizers
from sklearn import metrics
model = Sequential()
model.add(Dense(51, input_dim = 51, activation = 'relu'))
model.add(Dropout(0.2))
model.add(Dense(128, activation = 'relu'))
model.add(Dropout(0.2))
model.add(Dense(64, activation = 'relu'))
model.add(Dense(1, activation = 'sigmoid'))
model.compile(optimizer = optimizers.adam(lr = 0.006),
loss = 'binary_crossentropy',
metrics = ['accuracy'])
history = model.fit(X_train, y_train, nb_epoch = 20, batch_size = 512, validation_data = (X_test, y_test))3.模型运行情况作图
y_pred = model.predict_classes(X_test, batch_size = 20, verbose = 1)
target_names = ['1', '0']
print(metrics.classification_report(y_test, y_pred,
target_names = target_names))
history_dict = history.history
loss, accuracy = model.evaluate(X_test, y_test)
print('test loss: ', loss)
print('test accuracy: ', accuracy)
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
acc = history_dict['acc']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, loss_values, 'bo', label = 'Training loss')
plt.plot(epochs, val_loss_values, 'b', label = 'Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()#
acc_values = history_dict['acc']
val_acc_values = history_dict['val_acc']
plt.plot(epochs, acc_values, 'bo', label = 'Training acc')
plt.plot(epochs, val_acc_values, 'b', label = 'Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Acc')
plt.legend()
plt.show()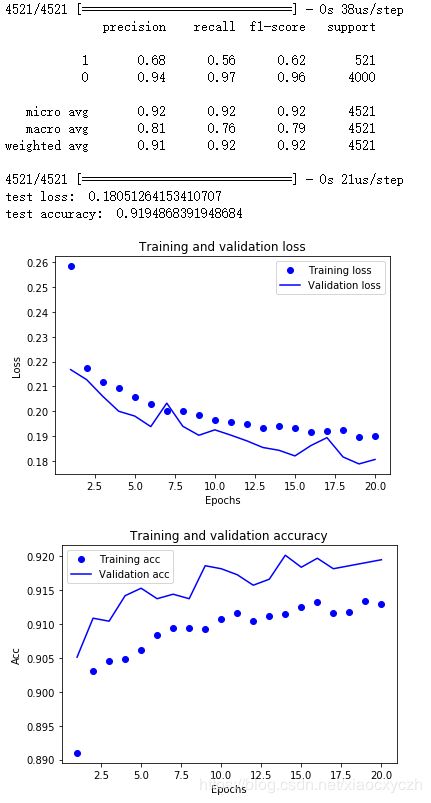
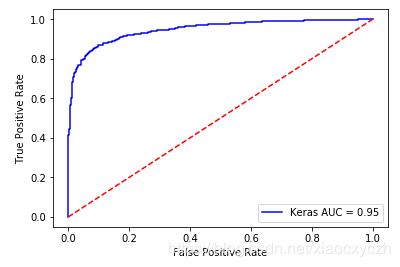
4.模型AUC评测
from sklearn.metrics import roc_curve, auc
y_pred_keras = model.predict(X_test).ravel()
fpr, tpr, threshold = roc_curve(y_test, y_pred_keras)
roc_auc = auc(fpr,tpr)
plt.plot(fpr, tpr, 'b', label='Keras AUC = %0.2f' % roc_auc)
plt.legend(loc='lower right')
plt.plot([0, 1], [0, 1], 'r--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()