java线程池应用场景 数据分析和网络爬虫
java线程池应用场景 数据分析和网络爬虫
一:java多线程应用
我们在实际的开发中经常会用到多线程,比如我们对磁盘文件的读写,为了提高对cpu的利用率,
我们会在很多地方用到多线程,:
1、比如我们可能会启动多个线程来读写磁盘。我们通过开启多个线程来不断轮询对应的设备寄存器是否准备好数据,没
有准备好这个线程就去处理别的东西,然后再有线程来询问。由于要进行的磁盘文件可以被任何I/O操作线程所访问,所以
这时候来轮询的数据和要拿数据的线程不一定是原来的线程。当设备驱动程序准备好数据之后,这时候可能是随机的一个
线程来处理数据。
2、或者我们开发完网站之后响应用户的请求,会开多个线程来响应用户的请求。其实tomcat也是这么做的。当有用户访
问的时候。tomcat就会为每个用户开启很多线程来响应用户的请求,如果用户发送请求的大小是1k,那么至少需要1M的
线程和处理内存的开销来服务每个用户。
二:java线程池的引入:
如果说线程池是为了提高cpu的利用率,那么线程池就是多线程的升级版,能够在多线程的基础上更好的利用宝贵的cpu
资源。尤其是要处理的数据量很大的时候。因为不断创建线程,线程消亡也需要一定的性能开销。为了更高效的处理数
据,我们采用线程池来进行管理线程,程序启动之后,开很多线程来获取数据,处理数据。但是处理完数据之后,线程
并不会消亡。而是被分配新的任务,获取或者处理数据。直到所有数据处理完毕。然后线程池释放所有线程,断开与线
程池连接。很厉害的大佬可能可以手写一套类似于线程池的线程管理工具。但是术业有专攻。这种东西人家帮我们开发
好了,功能和细节也比较完善,我们可以拿来直接用。jdk中给我们提供了线程池。我们也可以用一些第三方的jar包来配
置线程连接池。比如引入阿里的jar包来连接。其实是对jdk自带的封装。我们来看看jdk线程池的源码,了解一些基本的
配置参数。
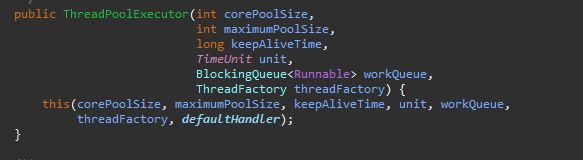
corePoolSize:核心线程池。线程池的基本大小,没有任务在运行的时候线程池的数量。但是allowCoreThreadTimeOut
设置为true时,并且超过了keepAliveTime的时间限制,这时候线程池是没有线程的。需要注意的是,线程创建之后并不
会立即执行,只有有任务到达的时候线程才会运行。
maximumPoolSize:允许线程池创建线程的最大数量。当任务队列塞满了corePoolSize允许的线程,会生成新的线程来
接受任务。线程池创建线程的数量受这个参数的限制。但是在线程池启动的时候,可以通过setmaximumPoolSize的大小
来调整开启的最大的线程数。不过不建议修改这个参数。因为线程数过多的话线程频繁切换会带来一定的开销。
keepAliveTime :这个参数指定了当任务队列中不再有任务的时候会结束线程。
unit:keepAliveTime的单位,
BlockingQueue:任务缓存队列,当线程执行完一个任务之后,回在这个缓存队列中分配任务给空闲的线程。
ThreadFactory:用来创建线程。
三:利用Executors 工厂创建线程池:
为了防止使用者错误搭配ThreadPoolExecutor构造函数的各个参数以及更加方便简洁的创建ThreadPoolExecutor对象,
JavaSE中又定义了Executors类,Eexcutors类底层调用的是ThreadPoolExecutor的构造方法,Eexcutors类提供了创建
常用配置线程池的方法。
1、 newSingleThreadExecutor:这种情况是在单线程情况下创建线程池,相当于只有一个线程同步执行所有的任务。
对应的任务策略是无界队列的方式。

2、newFixedThreadPool:固定大小的缓冲池,对应的任务排队策略是无界队列的方式。

3、newCachedThreadPool:可缓存的以根据任务量来动态调整缓冲池的数量,可以无限制扩大线程池中线程的数量。
对应的任务策略是直接提交的方式。

4、newScheduledThreadPool:线程池线程数量固定的线程池,以延时或者定时的方式执行任务。对应的任务策略是
优先级队列。


注意事项:java开发手册中一般不采用Executors来创建线程池。而是采用ThreadPoolExecutor方式创建线程池。
这样可以更加明确线程池的运行规则,规避资源耗尽的风险。
1:newSingleThreadExecutor和newFixedThreadPool采用的任务策略是无界队列的方式,可接收ude任务数量是Integer.MAX_VALUE,可能会造成内存溢出的问题。
2:newCachedThreadPool和newScheduledThreadPool可创建线程的数量是Integer.MAX_VALUE可能会创建大量线程,导致内存溢出
四:线程池的任务排队策略:
1、有界队列:
实现方式:ArrayBlockingQueue。这种情况存在任务缓冲队列,当有任务添加到线程池的时候,并且线程池中线程的数
量小于corePoolSize允许的数量,会试着新建线程来处理任务(即使已经创建的线程处于空闲状态也会创建新线程),达
到corePoolSize数量的时候,会把任务放在缓冲队列中。当线程池中的数量达到corePoolSize的时候,就会把任务放在
缓存队列中。当线程的数量达到corePoolSize的最大线程数并且缓冲队列满的时候,然后线程池会在maximumPoolSize
的允许范围内新建线程处理添加的任务。如果都满了之后就会产生任务拒绝。
2、无界队列:
实现方式:LinkedBlockingQueue。这种情况下,当有任务到达的时候,就会在线程池中者创建线程来执行任务,当达
到corePoolSize所允许的最大数量的时候,就会把多余的任务放在缓存队列中。这时候实际上maximumPoolSize参数
就无效了。这种情况适合于各个任务都互不影响的情况。
3、直接提交:
实现方式:SynchronousQueue。在这种任务提交方式下,能保证任务能够顺序执行,这种方式没有任务缓冲区,当有
空闲线程的时候,会有线程在队列头部等待任务到来。然后牵手,离开。当没有空闲线程的时候,会在任务达到的时候
生成一个线程来处理这个任务,所以这种队列不限制线程的数量。
4、优先级队列:
实现方式:DelayedWorkQueue。这种队列底层实现的是阻塞队列的方式,只不过有优先级的区别。当线程没达到最大
数量的时候,会新建一个线程来执行达到的任务,当线程不能再创建的时候,就会把多余的任务放在优先级队列中。延时
时间越短的线程越会放在队列靠前的位置。
五:线程池的任务拒绝发生的情况:
如果接受任务队列底层用阻塞队列的情况下,当corePoolSize,maximumPoolSize和缓冲区都满了的情况下,就会产生
任务拒绝。在不能创建新线程并且缓冲区满了之后。缓冲池调用execute(Runnable)或submit(Runnable)方法分配任务
就会发生任务拒绝。
六:线程池的任务拒绝策略:
- CallerRunsPolicy:线程调用运行该任务的 execute 本身。此策略提供简单的反馈控制机制,能够减缓新任务的提交速度。
- public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { if (!e.isShutdown()) { r.run(); }}
这个策略显然不想放弃执行任务。但是由于池中已经没有任何资源了,那么就直接使用调用该execute的线程本身来执行。(开始我总不想丢弃任务的执行,但是对某些应用场景来讲,很有可能造成当前线程也被阻塞。如果所有线程都是不能执行的,很可能导致程序没法继续跑了。需要视业务情景而定吧。) - AbortPolicy:处理程序遭到拒绝将抛出运行时 RejectedExecutionException
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {throw new RejectedExecutionException();}
这种策略直接抛出异常,丢弃任务。(jdk默认策略,队列满并线程满时直接拒绝添加新任务,并抛出异常,所以说有时候放弃也是一种勇气,为了保证后续任务的正常进行,丢弃一些也是可以接收的,记得做好记录) - DiscardPolicy:不能执行的任务将被删除
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {}
这种策略和AbortPolicy几乎一样,也是丢弃任务,只不过他不抛出异常。 - DiscardOldestPolicy:如果执行程序尚未关闭,则位于工作队列头部的任务将被删除,然后重试执行程序(如果再次失败,则重复此过程)
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { if (!e.isShutdown()) {e.getQueue().poll();e.execute(r); }}
该策略就稍微复杂一些,在pool没有关闭的前提下首先丢掉缓存在队列中的最早的任务,然后重新尝试运行该任务。这个策略需要适当小心。
七:线程池的应用场景:
1、数据分析:
一般的大型网站都会对用户的数据进行分析,以一般的大型网站举个例子,比如淘宝。我们在使用淘宝的时候,会对用
户的行为进行记录,比如你买了什么商品,你把什么商品放在了购物车,甚至你最近浏览过什么商品。都会记录下来。
但是淘宝的用户量是巨大了。淘宝账号的数量保守的估计是一亿。淘宝怎么分析如此庞大的数据呢?
首先要考虑的是怎么存储这些庞大的数据量,因为人家比较有钱,可以采用数据库集群来进行存储。然后要挑一个合适
的时间。因为要做数据分析肯定会大量调用数据库的信息。一般选择请求数量比较少的情况。可以选择晚上十二点以后。
肯定不能在用户访问量比较大的时候进行,因为可能会导致用户的请求丢失。而且一般不是消费高峰期(双11)的时候是
不会开启消息队列的。因为要频繁的分析数据库的数据,频繁进行磁盘I/O。线程复用就必不可少。我们可以自己选择实
现线程的复用,但是要考虑的东西比较多,包括线程创建消亡,线程调度等等。所以一般会调用人家开发好的接口。比
如jdk自带。或者阿里的线程池接口。
2、网络爬虫:
比如一个艺人的公司或者某个高校出了负面新闻,需要我们去网上的网站上联系人家删除对应的负面影响。但是人工去筛
选这些信息显然不合理,大大小小的比较流行的大网站有300多个。所以需要用到爬虫来爬出那些有负面影响的信息,联
系网站删除。还有应用比较火的地方就是人工智能方面。从网上爬完数据之后放在数据库,比如一些指定的名词以及解释
然后给机器人来学习。这时候更需要线程池来保证效率。
参考博客:
线程池拒绝策略:https://blog.csdn.net/wang_rrui/article/details/78541786
阻塞队列之三:SynchronousQueue同步队列 阻塞算法的3种实现:https://www.cnblogs.com/duanxz/p/3252267.html
Executors创建的4种线程池的使用:https://www.cnblogs.com/ljp-sun/p/6580147.html