FastText介绍
0. 简介
fastText是Facebook2016年提出的文本分类工具,是一种高效的浅层网络。
主流模型忽略单词的形态学,在大的单词库以及稀少单词时,出现局限性。 Fasttext 基于 skipgram或者CBOW 模型,考虑每个单词的字符,具有计算迅速,允许计算在训练数据没有出现过的单词表示。
1. 基本知识
1.1 Word2Vec
CBOW模型是,利用上下文预测目标词汇。

Skip-gram是利用当前时刻的词,预测它上下文的内容。
∑ t = 1 T ∑ c ∈ C t log p ( w c ∣ w t ) \sum_{t=1}^{T} \sum_{c \in \mathcal{C}_{t}} \log p\left(w_{c} | w_{t}\right) t=1∑Tc∈Ct∑logp(wc∣wt)
1.2 softmax回归
有m个样本 { ( x ( 1 ) , y ( 1 ) ) , . . . } \left\{ {(x^{(1)},y^{(1)}),...}\right\} {(x(1),y(1)),...}, y ( i ) ∈ { 0 , 1 } y^{(i)}\in \left\{ {0,1} \right\} y(i)∈{0,1}.假设,
h θ ( x ) = [ P ( y = 1 ∣ x ; θ ) P ( y = 2 ∣ x ; θ ) ⋮ P ( y = K ∣ x ; θ ) ] = 1 ∑ j = 1 K e θ ( j ) T x [ e θ ( 1 ) T x e θ ( 2 ) x ⋮ e θ ( K ) T x ] h_{\theta}(x)=\left[\begin{array}{c}{P(y=1 | x ; \theta)} \\ {P(y=2 | x ; \theta)} \\ {\vdots} \\ {P(y=K | x ; \theta)}\end{array}\right]= \frac{1}{\sum_{j=1}^{K} e^{\theta(j)^{T} x}}\left[\begin{array}{c}{e^{\theta^{(1)^{T}} x}} \\ {e^{\theta^{(2)} x}} \\ {\vdots} \\ {e^{\theta(K)^{T} x}}\end{array}\right] hθ(x)=⎣⎢⎢⎢⎡P(y=1∣x;θ)P(y=2∣x;θ)⋮P(y=K∣x;θ)⎦⎥⎥⎥⎤=∑j=1Keθ(j)Tx1⎣⎢⎢⎢⎢⎡eθ(1)Txeθ(2)x⋮eθ(K)Tx⎦⎥⎥⎥⎥⎤
Word2Vec 模型对最后一层输出值经过Softmax运算,来获得预测单词的概率。
比如,Skip-gram模型
p ( w c ∣ w t ) = e s ( w t , w c ) ∑ j = 1 W e s ( w t , j ) p\left(w_{c} | w_{t}\right)=\frac{e^{s\left(w_{t}, w_{c}\right)}}{\sum_{j=1}^{W} e^{s\left(w_{t}, j\right)}} p(wc∣wt)=∑j=1Wes(wt,j)es(wt,wc)
其中,s(,) 得分函数(scoring function)把 ( w t , w c ) (w_t,w_c) (wt,wc)评估为一个实数值。
1.2 分层Softmax
词汇 y y y量很大时,softmax归一化很耗时,分层Softmax用树的层级结构来代替扁平化的标准Softmax。
霍夫曼树
霍夫曼树建立的过程是基于词频,它把词频高的单词尽量靠近根节点。具体实现是,先把词频最低的两个词用一个树表示,两个词频相加为这棵树新的词频(把这颗树当作一个单词);再重新选取词频最低的两个词,继续构建树,直到所有单词表示完成。

在word2vec中,我们采用了二元逻辑回归的方法,即规定沿着左子树走,那么就是负类(霍夫曼树编码1),沿着右子树走,那么就是正类(霍夫曼树编码0)。判别正类和负类的方法是使用sigmoid函数,即:
P ( + ) = σ ( x w T θ ) = 1 1 + e − x w T θ P(+)=\sigma\left(x_{w}^{T} \theta\right)=\frac{1}{1+e^{-x_{w}^{T} \theta}} P(+)=σ(xwTθ)=1+e−xwTθ1
计算 P ( y = j ) P(y = j) P(y=j)时,只需计算一条路径上所有节点的概率值。

P ( y 2 ) = P ( n ( y 2 , 1 ) , left ) ⋅ P ( n ( y 2 , 2 ) , left ) ⋅ P ( n ( y 2 , 3 ) , right ) = σ ( θ n ( y 2 , 1 ) T X ) ⋅ σ ( θ n ( y 2 , 2 ) T X ) ⋅ σ ( − θ n ( y 2 , 3 ) T X ) \begin{aligned} \mathrm{P}\left(y_{2}\right) &=\mathrm{P}\left(n\left(y_{2}, 1\right), \text { left }\right) \cdot \mathrm{P}\left(n\left(y_{2}, 2\right), \text { left }\right) \cdot \mathrm{P}\left(n\left(y_{2}, 3\right), \text { right }\right) \\ &=\sigma\left(\theta_{n\left(y_{2}, 1\right)}^{T} X\right) \cdot \sigma\left(\theta_{n\left(y_{2}, 2\right)}^{T} X\right) \cdot \sigma\left(-\theta_{n\left(y_{2}, 3\right)}^{T} X\right) \end{aligned} P(y2)=P(n(y2,1), left )⋅P(n(y2,2), left )⋅P(n(y2,3), right )=σ(θn(y2,1)TX)⋅σ(θn(y2,2)TX)⋅σ(−θn(y2,3)TX)
其中,树的不同节点 θ n ( , ) \theta_{n(,)} θn(,)也不同。
关于分层Softmax,可以看刘建平的博客.
1.3 负采样
Negative Sampling.
在Skip-gram模型中,预测上下文单词(context words)可以看做一系列的二分类任务。目标是独立预测当前(center word, context word)对是否包含上下文单词。负样本是随机从单词库根据出现的频率加权采样得到的单词集。
log ( 1 + e − s ( w t , w c ) ) + ∑ n ∈ N t , c log ( 1 + e s ( w t , n ) ) \log \left(1+e^{-s\left(w_{t}, w_{c}\right)}\right)+\sum_{n \in \mathcal{N}_{t, c}} \log \left(1+e^{s\left(w_{t}, n\right)}\right) log(1+e−s(wt,wc))+n∈Nt,c∑log(1+es(wt,n))
也可写成:
∑ t = 1 T [ ∑ c ∈ C t ℓ ( s ( w t , w c ) ) + ∑ n ∈ N t , c ℓ ( − s ( w t , n ) ) ] \sum_{t=1}^{T}\left[\sum_{c \in \mathcal{C}_{t}} \ell\left(s\left(w_{t}, w_{c}\right)\right)+\sum_{n \in \mathcal{N}_{t, c}} \ell\left(-s\left(w_{t}, n\right)\right)\right] t=1∑T⎣⎡c∈Ct∑ℓ(s(wt,wc))+n∈Nt,c∑ℓ(−s(wt,n))⎦⎤
关于得分函数s,可以定义为:
s ( w t , w c ) = u w t ⊤ v w c s\left(w_{t}, w_{c}\right)=\mathbf{u}_{w_{t}}^{\top} \mathbf{v}_{w_{c}} s(wt,wc)=uwt⊤vwc
其中, u , v u,v u,v分别是单词 w t , w c w_t, w_c wt,wc的向量表示。
关于负采样的概率:
随机选择反例样本,其概率通常设定为语料库各词频的3/4次幂。这样,增加了低频样本采样的概率。
2. FastText模型
FastText模型生成词的Embedding。
2.1 子单词模型
subword model,考虑单词的内部结构.
字符的n-grams,比如,对单词 where, n=3, 那么,
表示有:
得分函数为:
s ( w , c ) = ∑ g ∈ G w z g ⊤ v c s(w, c)=\sum_{g \in \mathcal{G}_{w}} \mathbf{z}_{g}^{\top} \mathbf{v}_{c} s(w,c)=g∈Gw∑zg⊤vc
这里, z g z_g zg代表 单词w 在 g-grams 下的向量表示。
2.2 模型结构
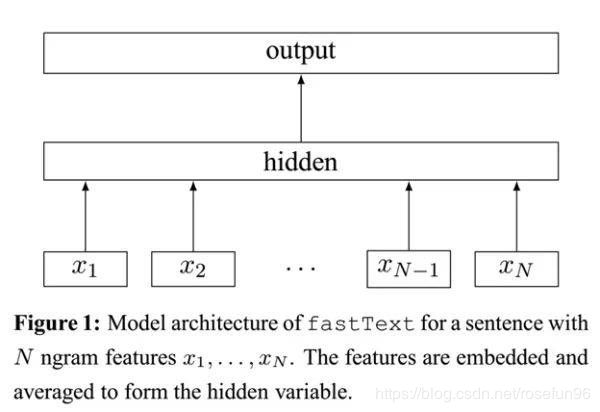
FastText架构和Word2Vec的CBOW模型相似,FastText模型只有3层:输入层,隐含层,输出层(Hierarchical Softmax),输入都是多个经向量表示的单词,输出都是一个特定的target,隐含层都是多个词向量的叠加平均。
不同的是,CBOW的输入是目标单词的上下文,fastText的输入是多个单词及其n-gram特征,这些特征用来表示单个文档;CBOW的输入单词被onehot编码过,fastText的输入特征是被embedding过;CBOW的输出是目标词汇,fastText的输出是文档对应的类标。
fastText的核心思想就是:将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类。这中间涉及到两个技巧:字符级n-gram特征的引入以及分层Softmax分类。
模型前半部分,叠加构成文档的所有词及n-gram的词向量,取平均,生成用来表征文档的词向量。
模型的后半部分,用Softmax分类器来输出每个词向量的类别。
3 总结
FastText效果好的原因:使用词Embedding和字符级n-gram,使得,轻量级的网络取得较好的结果。
reference:
- 机器之心文章;
- 原论文 Bag of Tricks for Efficient Text Classification;
- 原论文2 Enriching Word Vectors with Subword Information;
- Github fasttext code;
- 刘建平的博客;