java并发编程2.1并发工具类——Fork-Join
环境:
jdk1.8
摘要说明:
上一大章节主要讲述线程的基础概念,线程间的共享及协作;
从本章节开始会介绍并发编程的常用工具类;本章节主要介绍Fork-Join基础概念及用法
步骤:
1.Fork-Join基础概念
什么是分而治之?
分而治之的基本思想就是将大任务分割成小任务,最后将小任务聚合起来得到结果。
Fork-Join就是基于分而治之思想而设计的,即规模为N的问题,N<阈值,直接解决,N>阈值,将N分解为K个小规模子问题,子
问题互相对立,与原问题形式相同,将子问题的解合并得到原问题的解;
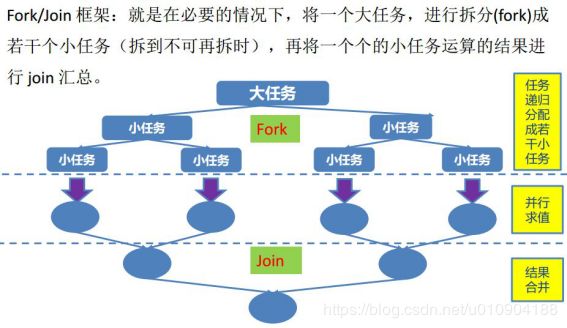
其中多个子任务运行时有遵循工作密取(workStealing)思想,即先完成的子线程可从其他线程中获取任务执行,从而降低主线程的等待;
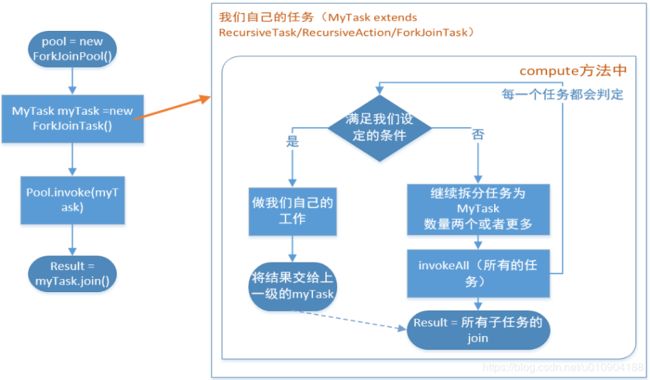
Fork-Join涉及到的类如下;
- ForkJoinTask:要使用ForkJoin框架,必须首先创建一个ForkJoin任务。它提供在任务中执行fork()和join的操作机制,通常我们不直接继承ForkjoinTask类,只需要直接继承其子类:
- RecursiveAction,用于没有返回结果的任务
- RecursiveTask,用于有返回值的任务
- ForkJoinPool:task要通过ForkJoinPool来执行,分割的子任务也会添加到当前工作线程池的双端队列中,进入队列的头部。当一个工作线程中没有任务时,会从其他工作线程的队列尾部获取一个任务;
标准范式如下:
2.Fork-Join同步示例(RecursiveTask)
同步用法一般用于需要同步返回结果值的情况:如n个随机数相加;
首先我们看单线程进行计算:
package pers.cc.curriculum2.forkJion;
import java.util.Random;
import pers.cc.tools.SleepTools;
/**
* 单线程计算指定个数的随机值之和
*
* @author cc
*
*/
public class SumRandomTradition {
/**
* 计算指定个数的随机数之和并打印随机数
*
* @param length
* @return
*/
public static Long sumRandom(int length) {
// new一个随机数发生器
Random r = new Random();
Long result = (long) 0;
for (int i = 0; i < length; i++) {
// 三位数内的随机数相加
int ran = r.nextInt(1000);
System.out.println(ran);
result = result + ran;
// 模拟业务场景耗时
SleepTools.ms(2);
}
return result;
}
public static void main(String[] args) {
// 起始时间
long start = System.currentTimeMillis();
// 计算个数
int count = 100000;
System.out.println(SumRandomTradition.sumRandom(count));
System.out.println("The count is " + count + " spend time:"
+ (System.currentTimeMillis() - start) + "ms");
}
}
运行结果:
......
49942525
The count is 100000 spend time:238661ms使用fork-join进行运算:
package pers.cc.curriculum2.forkJion;
import java.util.Random;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
import pers.cc.tools.SleepTools;
/**
* 使用forkjoin模式进行指定个数的随机数相加并打印随机数
*
* @author cc
*
*/
public class SumRandomForkJoin {
/**
* 使用RecursiveTask同步返回结果
*
* @author cc
*
*/
private static class SumTask extends RecursiveTask < Long > {
// 定义阈值
private final static int THRESHOLD = 1000;
// 定义任务起始坐标
private int fromIndex;
// 定义任务终止坐标
private int endIndex;
public SumTask(int fromIndex, int endIndex) {
this.fromIndex = fromIndex;
this.endIndex = endIndex;
}
/**
* 实现执行方法
*/
@Override
protected Long compute() {
// new一个随机数发生器
Random r = new Random();
if (endIndex - fromIndex <= THRESHOLD) {
Long result = (long) 0;
// 左闭右开
for (int i = 0; i < endIndex - fromIndex; i++) {
// 三位数内的随机数相加
int ran = r.nextInt(1000);
System.out.println(ran);
result = result + ran;
// 模拟业务场景耗时
SleepTools.ms(2);
}
return result;
}
else {
// 将运算分成两个线程进行
int mid = (fromIndex + endIndex) / 2;
SumTask left = new SumTask(fromIndex, mid);
SumTask right = new SumTask(mid + 1, endIndex);
// 注意的是这里并不是只能分成两个线程,invokeAll方法可以是两个线程,也可以是多个线程,也可以是一个线程集合
invokeAll(left, right);
return left.join() + right.join();
}
}
}
public static void main(String[] args) {
// 起始时间
long start = System.currentTimeMillis();
// 计算个数
int count = 100000;
// 定义一个任务集合
SumTask task = new SumTask(0, count - 1);
// 定义一个forkjoin线程池
ForkJoinPool pool = new ForkJoinPool();
pool.invoke(task);
// 打印结果
System.out.println(task.join());
System.out.println("The count is " + count + " spend time:"
+ (System.currentTimeMillis() - start) + "ms");
}
}
运算结果:
......
50003614
The count is 100000 spend time:58717ms结果对比可以看出fork-join模式更快;但注意的是如果将模拟业务的休眠两毫秒去掉的话,可能fork-join更慢,这个主要是由于上下文来回不停切换导致的;
3.Fork-Join异步示例(RecursiveAction)
同步用法一般用于不需要返回结果集的情况:如遍历打印指定文件下指定路径的文件
package pers.cc.curriculum2.forkJion;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
/**
* 遍历打印指定目录下指定类型的文件
*
* @author cc
*
*/
public class FindDirsTypeFiles extends RecursiveAction {
private File path;// 当前任务需要搜寻的目录
private String fileType;// 当前任务需要搜寻的目录
public FindDirsTypeFiles(File path, String fileType) {
this.path = path;
this.fileType = fileType;
}
@Override
protected void compute() {
List < FindDirsTypeFiles > subTasks = new ArrayList < FindDirsTypeFiles >();
File[] files = path.listFiles();
if (files != null) {
for (File file : files) {
// 如果是路径就新建一个子任务
if (file.isDirectory()) {
subTasks.add(new FindDirsTypeFiles(file, fileType));
}
else {
// 遇到文件,检查
if (file.getAbsolutePath().endsWith(fileType)) {
System.out.println("文件:" + file.getAbsolutePath());
}
}
}
if (!subTasks.isEmpty()) {
// 将若有子任务集合并将结果合并
for (FindDirsTypeFiles subTask : invokeAll(subTasks)) {
subTask.join();// 等待子任务执行完成
}
}
}
}
public static void main(String[] args) throws InterruptedException {
// 创建线程池
ForkJoinPool pool = new ForkJoinPool();
FindDirsTypeFiles task = new FindDirsTypeFiles(new File("D:/.m2"),
"jar");
pool.execute(task);// 异步调用
System.out.println("Task is Running......");
Thread.sleep(1);
int otherWork = 0;
for (int i = 0; i < 100; i++) {
otherWork = otherWork + i;
}
System.out.println("Main Thread done sth......,otherWork=" + otherWork);
task.join();// 阻塞的方法,无返回
System.out.println("Task end");
}
}
运行结果:
Task is Running......
Main Thread done sth......,otherWork=5050
文件:D:\.m2\repository\com\fasterxml\jackson\core\jackson-core\2.5.2\jackson-core-2.5.2.jar
文件:D:\.m2\repository\io\netty\netty-codec-http\4.1.24.Final\netty-codec-http-4.1.24.Final.jar
......
Task end从运行结果上看主线程可以异步调用;
4.总结
ForkJoinPool:是ExecutorService的实现类,因此是一种特殊的线程池。主要用于调用ForkJoinTask;初始化时可通过ForkJoinPool(int parallelism) 来指定并行度;
其主要用来运行ForkJoinTask的三个方法如下:
- execute(ForkJoinTask):异步执行,对应的是ForkJoinTask.fork() ;
- invoke(ForkJoinTask):同步执行,对应的是ForkJoinTask.invoke();
- submit(ForkJoinTask) :安排执行并获得未来的结果,对应的是ForkJoinTask.fork() (ForkJoinTasks are Futures)
ForkJoinTask:抽象基类,用于在ForkJoinPool中运行的任务。ForkJoinTask是一种类似于线程的实体,比普通线程的更轻。在ForkJoinPool中,大量任务和子任务可能由少量实际线程承载,但代价是存在一些使用限制。
当一个“主”fork joint ask被显式提交给一个ForkJoinPool时,或者(如果还没有进行fork join计算的话)通过fork()、invoke()或相关方法在fork . commonpool()中开始执行时,它就开始执行。一旦启动,它通常会依次启动其他子任务。如此类的名称所示,许多使用ForkJoinTask的程序仅使用fork()和join()方法,或invokeAll等派生方法。然而,这个类还提供了许多在高级用法中可以使用的其他方法,以及支持新形式的fork/join处理的扩展机制。
常用方法:
- fork():在当前任务所在的池中异步执行此任务
- join():返回计算完成时的结果。
- invokeAll:可指定连个task,也可指定多个,更可以指定一个集合;执行指定集合中的所有任务,当isDone为每个任务保留或遇到(未检查)异常时返回,在这种情况下,将重新抛出异常。如果多个任务遇到异常,则此方法将抛出这些异常中的任何一个。如果任何任务遇到异常,其他任务可能会被取消。但是,在异常返回时不能保证单个任务的执行状态。可以使用getException()和相关方法获取每个任务的状态,以检查它们是否已被取消、正常完成或异常完成,或未处理。
RecursiveAction和RecursiveTask是ForkJoinTask的两个子类,区别就是在于一个返回结果,一个不返回;
5.源码地址
https://github.com/cc6688211/concurrent-study.git