在项目迭代的过程中,不可避免需要”上线“。上线对应着部署,或者重新部署;部署对应着修改;修改则意味着风险。
目前有很多用于部署的技术,有的简单,有的复杂;有的得停机,有的不需要停机即可完成部署。本文的目的就是将目前常用的布署方案做一个总结。
一、蓝绿布署
Blue/Green Deployment(蓝绿部署)
1、定义
蓝绿部署是不停老版本,部署新版本然后进行测试,确认OK,将流量切到新版本,然后老版本同时也升级到新版本。
1、特点
蓝绿部署无需停机,并且风险较小。
2、布署过程
第一步、部署版本1的应用(一开始的状态)
所有外部请求的流量都打到这个版本上。

第二步、部署版本2的应用
版本2的代码与版本1不同(新功能、Bug修复等)。
第三步、将流量从版本1切换到版本2。

第四步、如版本2测试正常,就删除版本1正在使用的资源(例如实例),从此正式用版本2。
3、小结
从过程不难发现,在部署的过程中,我们的应用始终在线。并且,新版本上线的过程中,并没有修改老版本的任何内容,在部署期间,老版本的状态不受影响。这样风险很小,并且,只要老版本的资源不被删除,理论上,我们可以在任何时间回滚到老版本。
4、蓝绿发布的注意事项
当你切换到蓝色环境时,需要妥当处理未完成的业务和新的业务。如果你的数据库后端无法处理,会是一个比较麻烦的问题;
可能会出现需要同时处理“微服务架构应用”和“传统架构应用”的情况,如果在蓝绿部署中协调不好这两者,还是有可能会导致服务停止。
需要提前考虑数据库与应用部署同步迁移 /回滚的问题。
蓝绿部署需要有基础设施支持。
在非隔离基础架构( VM 、 Docker 等)上执行蓝绿部署,蓝色环境和绿色环境有被摧毁的风险。
二、Rolling update(滚动发布)
1、滚动发布定义
滚动发布:一般是取出一个或者多个服务器停止服务,执行更新,并重新将其投入使用。周而复始,直到集群中所有的实例都更新成新版本。
2、特点
这种部署方式相对于蓝绿部署,更加节约资源——它不需要运行两个集群、两倍的实例数。我们可以部分部署,例如每次只取出集群的20%进行升级。
这种方式也有很多缺点,例如:
(1) 没有一个确定OK的环境。使用蓝绿部署,我们能够清晰地知道老版本是OK的,而使用滚动发布,我们无法确定。
(2) 修改了现有的环境。
(3) 如果需要回滚,很困难。举个例子,在某一次发布中,我们需要更新100个实例,每次更新10个实例,每次部署需要5分钟。当滚动发布到第80个实例时,发现了问题,需要回滚,这个回滚却是一个痛苦,并且漫长的过程。
(4) 有的时候,我们还可能对系统进行动态伸缩,如果部署期间,系统自动扩容/缩容了,我们还需判断到底哪个节点使用的是哪个代码。尽管有一些自动化的运维工具,但是依然令人心惊胆战。
(5) 因为是逐步更新,那么我们在上线代码的时候,就会短暂出现新老版本不一致的情况,如果对上线要求较高的场景,那么就需要考虑如何做好兼容的问题。
三、灰度发布/金丝雀部署
1、定义
灰度发布是指在黑与白之间,能够平滑过渡的一种发布方式。AB test就是一种灰度发布方式,让一部分用户继续用A,一部分用户开始用B,如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B上面来。灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度,而我们平常所说的金丝雀部署也就是灰度发布的一种方式。
注释:矿井中的金丝雀
17世纪,英国矿井工人发现,金丝雀对瓦斯这种气体十分敏感。空气中哪怕有极其微量的瓦斯,金丝雀也会停止歌唱;而当瓦斯含量超过一定限度时,虽然鲁钝的人类毫无察觉,金丝雀却早已毒发身亡。当时在采矿设备相对简陋的条件下,工人们每次下井都会带上一只金丝雀作为“瓦斯检测指标”,以便在危险状况下紧急撤离。
灰度发布结构图如下:
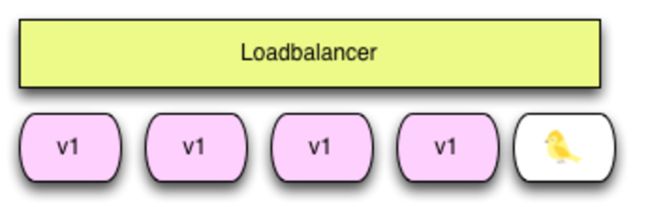
2、灰度发布/金丝雀发布由以下几个步骤组成:
准备好部署各个阶段的工件,包括:构建工件,测试脚本,配置文件和部署清单文件。
从负载均衡列表中移除掉“金丝雀”服务器。
升级“金丝雀”应用(排掉原有流量并进行部署)。
对应用进行自动化测试。
将“金丝雀”服务器重新添加到负载均衡列表中(连通性和健康检查)。
如果“金丝雀”在线使用测试成功,升级剩余的其他服务器。(否则就回滚)
除此之外灰度发布还可以设置路由权重,动态调整不同的权重来进行新老版本的验证。
参考文章
https://www.v2ex.com/t/344341
https://www.jianshu.com/p/022685baba7d
四、A/B测试
首先需要明确的是,A/B测试和蓝绿部署以及金丝雀,完全是两回事。
蓝绿部署和金丝雀是发布策略,目标是确保新上线的系统稳定,关注的是新系统的BUG、隐患。
A/B测试是效果测试,同一时间有多个版本的服务对外服务,这些服务都是经过足够测试,达到了上线标准的服务,有差异但是没有新旧之分(它们上线时可能采用了蓝绿部署的方式)。
A/B测试关注的是不同版本的服务的实际效果,譬如说转化率、订单情况等。
A/B测试时,线上同时运行多个版本的服务,这些服务通常会有一些体验上的差异,譬如说页面样式、颜色、操作流程不同。相关人员通过分析各个版本服务的实际效果,选出效果最好的版本。
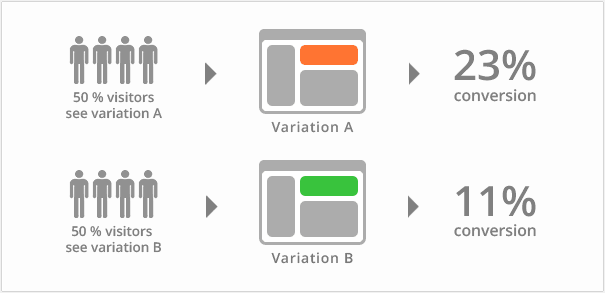
在A/B测试中,需要能够控制流量的分配,譬如说,为A版本分配10%的流量,为B版本分配10%的流量,为C版本分配80%的流量。
参考文章
https://blog.csdn.net/lijiaocn/article/details/84276591
五、为什么选择使用K8s?
在使用k8s之前,陌陌在应用发布和运行环境方面遇到的具体问题,如下:
应用发布时间很长,主要是因为发布过程中需要做隔离、恢复等动作,还需要登录查看实际状态、日志。
当遇到晚高峰情况这样的突发状况,需要紧急扩容。这时业务方会申请机器,可新机需要进行环境初始化、相关配置,这样导致效率非常低。
应用运行环境的软件版本不一致,配置复杂,维护成本比较高。
硬件资源利用率不足,总体成本比较高。
针对以上遇到的问题,我们决定对架构进行改造,同时制定了一系列架构改进目标,如下:
提高服务可用性,可管理性。可用性是当某一台机器出现宕机,会自动切换到其他机器。可管理性是在应用需要扩容时,自动化去部署运行环境、相关配置。开发不需要再去考虑服务器的问题。
提高资源隔离性,实现服务混合部署。
应用级别的监控,当机器需要扩容时,自动排查是哪个应用所致。
服务平滑迁移。
综合这些问题和目标,陌陌选择使用 Kubernetes来管理 Docker 集群,当 Kubernetes 满足不了需求时,可在部署平台开发相应的功能来满足开发查看日志、监控和报警等需求,尽量避免登录主机和容器。
陌陌容器管理平台的架构演进
陌陌从2015年下半年开始对Docker进行调研和实践,2016年初开始调研k8s,尝试架构方面的改进工作,基于自研发布系统及K8s、OVS和Docker构建容器管理平台。实现了基于Docker集群的部署系统,便于开发者便捷地部署自己的应用程序。最终达到部署环境干净一致,可重复部署、迅速扩容和回滚。
如下图,是容器管理平台的架构图:
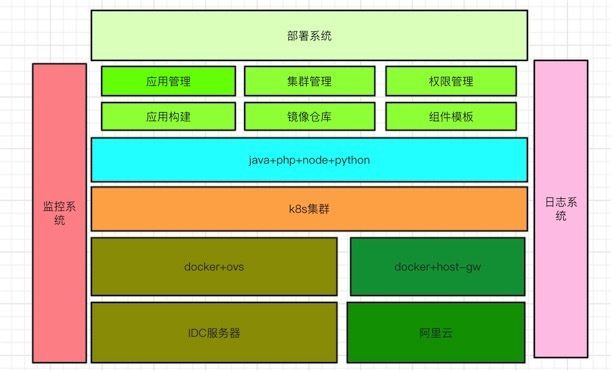
容器管理平台主要功能有集群管理和状态展示、灰度发布和代码回退、组件模板、应用管理、镜像仓库和权限管理等。它采用前后端分离的架构,前端使用 JS 渲染,后端使用 Python 提供 API。这样开发者可以快速的进行发布和回退操作。
容器管理平台在应用发布流程,集群调度策略,k8s节点网络架构,阿里云支持,基础监控指标等方面进行了优化改进。
六、应用发布流程
陌陌之前老版本发布系统是串行的,需要单台进行替换。如下图,是新架构下应用的发布流程:
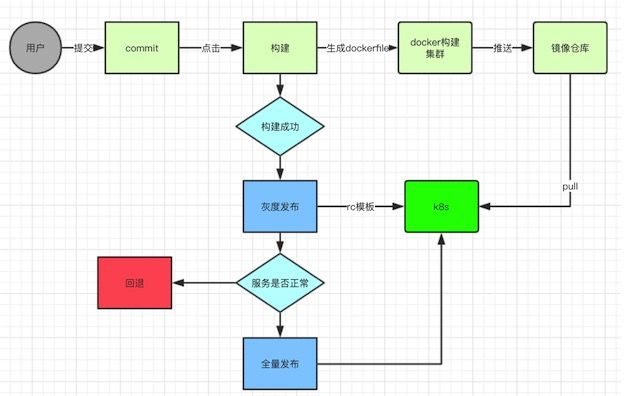
新的发布系统是用户提交代码后,在发布系统选择要部署的commit,点击构建以后,系统会自动编译,打包成镜像,推送镜像仓库。如果构建成功,用户点击发布新版本的实例,灰度没有问题,全量,下线老版本的实例。回退时代码不需要构建,直接发布老版本实例。在某段时间内,新老版本是同时存在的。
七、集群调度策略
陌陌的集群调度策略是为应用配置默认的location(集群标签),如果是线上应用,应用需要申请location,部署到正式的集群(机房要求,资源充足)。这里应用都不能独占集群,均采用的是混合部署的方式。
同一个集群下,分成不同组并组定义标签,应用支持独占机器,同一个组之间的应用实例可以随意飘移。
八、IDC网络节点
在IDC网络节点构建部分,陌陌使用的是全局IP地址,容器与容器之间、容器与主机之间都是互通的。这样一来,通信可以不使用任何封装等技术,相对来说比较高效且对现有网络变动影响小(仅需封装trunk,无其他协议,mtu等变化)。
如下图,是IDC网络节点架构图:
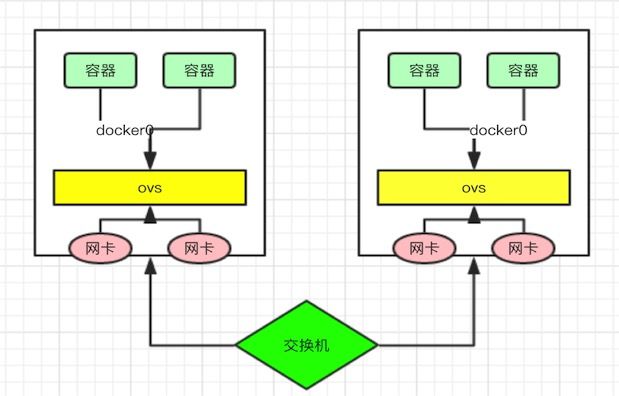
在这样的架构下,网络部署和扩展相对简单,因为每台机器的IP地址段是预先静态配置的。
这里值得注意的是,服务器双链路上联,trunk上联物理交换机需要合理避免二层环路。
这样的方式存在的不足是,当容器较多时,mac地址数量增多,给物理交换机Mac地址表带来压力,广播域扩大就是需要严谨的规划vlan 角色相关信息。
九、阿里云支持
当前,陌陌K8s master集群下节点包含IDC、阿里云及两者混合三种方式,如下图:
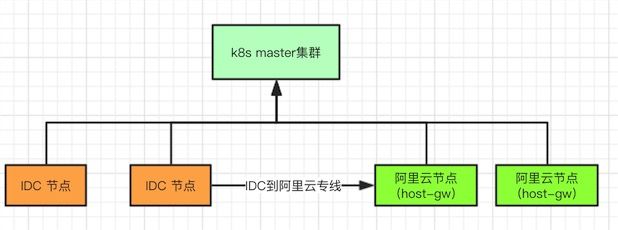
阿里云采用的网络模式是Host-gw,陌陌搭建了一条IDC与阿里云的VPC专线和VPC的虚拟路由进行静态配置。无论是IDC节点,还是阿里云节点上的应用都要适应IP动态变化。
十、基础监控指标
陌陌的监控方案大多是基于Kublet cadvisor metrics接口去做的数据汇总。最初陌陌采用的方式是利用Python脚本,去调用接口,在取到一些CPU内存、网络、流量的数据,存入ES,分析之后进行展示。之后的报警系统,是利用Java应用去调取Kublet cadvisor metrics接口,进行数据的收集。
基础监控指标主要有内存(total,rss,cache)、流量(incoming,outgoing)、网络packets(drop,error, total)等。
应用迁移
应用迁移方面,陌陌做了很多适配工作,使得应用不需要太多的改动就可以无缝迁移。具体适配细节如下:
应用适应动态ip变化。
自定义构建过程(build.sh)。
应用使用不同的服务发现框架(nginx,rpc)(start.sh)。
应用销毁过程中做一些额外处理(stop.sh)。
在应用迁移过程中,也遇到了一些问题,如Swap、cpu软中断优化、资源利用率、Ip白名单、适用于内网等问题。
当前,陌陌的容器业务规模服务器约400台、线上容器6000、应用700+。应用的类型是java+php+node+python+tomcat。
参考文章
https://www.jianshu.com/p/311009781b77