数据结构——ConcurrentHashMap
上一篇我们提到HashMap是线程不安,而hashTable虽然是线程安全,但是性能很差。java提供了ConcurrentHashMap来替代hashTable。
我们先来看一下JDK1.7的currentMap的结构:
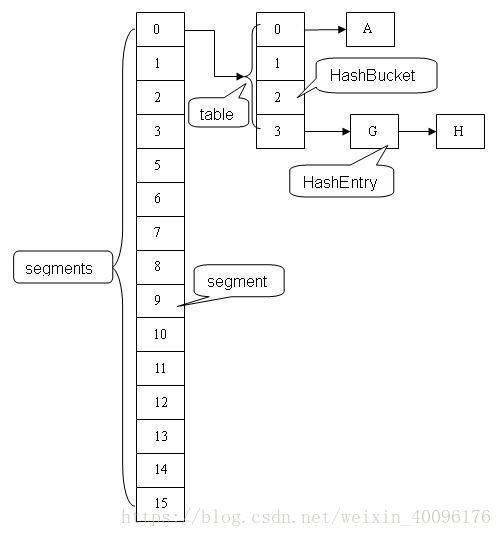
在ConcurrentHashMap中有个重要的概念就是Segment。我们知道HashMap的结构是数组+链表形式,从图中我们可以看出其实每个segment就类似于一个HashMap。Segment包含一个HashEntry数组,数组中的每一个HashEntry既是一个键值对,也是一个链表的头节点。在ConcurrentHashMap中有2的N次方个Segment,共同保存在一个名为segments的数组当中。可以说,ConcurrentHashMap是一个二级哈希表。在一个总的哈希表下面,有若干个子哈希表。
为什么说ConcurrentHashMap的性能要比HashTable好,HashTables是用全局同步锁,而CconurrentHashMap采用的是锁分段,每一个Segment就好比一个自治区,读写操作高度自治,Segment之间互不干扰。
先来看看几个并发的场景:
Case1:不同Segment的并发写入
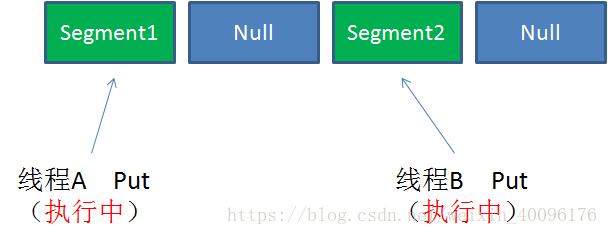
不同Segment的写入是可以并发执行的。
Case2:同一Segment的一写一读

同一Segment的写和读是可以并发执行的。
Case3:同一Segment的并发写入

Segment的写入是需要上锁的,因此对同一Segment的并发写入会被阻塞。
由此可见,ConcurrentHashMap当中每个Segment各自持有一把锁。在保证线程安全的同时降低了锁的粒度,让并发操作效率更高。
上面我们说过,每个Segment就好比一个HashMap,其实里面的操作原理都差不多,只是Segment里面加了锁。
Get方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.再次通过hash值,定位到Segment当中数组的具体位置。
public V get(Object key) {
Segment s; // manually integrate access methods to reduce overhead
HashEntry[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry e = (HashEntry) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
} Put方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.获取可重入锁
4.再次通过hash值,定位到Segment当中数组的具体位置。
5.插入或覆盖HashEntry对象。
6.释放锁。
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry first = entryAt(tab, index);
for (HashEntry e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
} 可以看出get方法并没有加锁,那怎么保证读取的正确性呢,这是应为value变量用了volatile来修饰,后面再详细讲解volatile。
static final class HashEntry {
final int hash;
final K key;
volatile V value;
volatile HashEntry next;
HashEntry(int hash, K key, V value, HashEntry next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
..... size方法
既然每一个Segment都各自加锁,那么我们在统计size()的时候怎么保证解决一直性的问题,比如我们在计算size时,有其他线程在添加或删除元素。
/**
* Returns the number of key-value mappings in this map. If the
* map contains more than Integer.MAX_VALUE elements, returns
* Integer.MAX_VALUE.
*
* @return the number of key-value mappings in this map
*/
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
} ConcurrentHashMap的Size方法是一个嵌套循环,大体逻辑如下:
1.遍历所有的Segment。
2.把Segment的元素数量累加起来。
3.把Segment的修改次数累加起来。
4.判断所有Segment的总修改次数是否大于上一次的总修改次数。如果大于,说明统计过程中有修改,重新统计,尝试次数+1;如果不是。说明没有修改,统计结束。
5.如果尝试次数超过阈值,则对每一个Segment加锁,再重新统计。
6.再次判断所有Segment的总修改次数是否大于上一次的总修改次数。由于已经加锁,次数一定和上次相等。
7.释放锁,统计结束。
可以看出JDK1.7的size计算方式有点像乐观锁和悲观锁的方式,为了尽量不锁住所有Segment,首先乐观地假设Size过程中不会有修改。当尝试一定次数,才无奈转为悲观锁,锁住所有Segment保证强一致性。
JDK1.7和JDK1.8中ConcurrentHashMap的区别
1、在JDK1.8中ConcurrentHashMap的实现方式有了很大的改变,在JDK1.7中采用的是Segment + HashEntry,而Sement继承了ReentrantLock,所以自带锁功能,而在JDK1.8中则取消了Segment,作者认为Segment太过臃肿,采用Node + CAS + Synchronized(ps:Synchronized一直以来被各种吐槽性能差,但java一直没有放弃Synchronized,也一直在改进,既然作者在这里采用了Synchronized,可见Synchronized的性能应该是有所提升的,当然只是猜想哈哈哈。。。)
2、在上篇HashMap中我们知道,在JDK1.8中当HashMap的链表个数超过8时,会转换为红黑树,在ConcurrentHashMap中也不例外。这也是新能的一个小小提升。
3、在JDK1.8版本中,对于size的计算,在扩容和addCount()时已经在处理了。JDK1.7是在调用时才去计算。
为了帮助统计size,ConcurrentHashMap提供了baseCount和counterCells两个辅助变量和CounterCell辅助类,1.8中使用一个volatile类型的变量baseCount记录元素的个数,当插入新数据或则删除数据时,会通过addCount()方法更新baseCount。
//ConcurrentHashMap中元素个数,但返回的不一定是当前Map的真实元素个数。基于CAS无锁更新
private transient volatile long baseCount;
private transient volatile CounterCell[] counterCells; // 部分元素变化的个数保存在此数组中
/**
* {@inheritDoc}
*/
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}参考:https://www.jianshu.com/p/e694f1e868ec
https://www.cnblogs.com/butterfly100/p/8019491.html
《程序员小灰公众号》