一直在寻找一个东西,一个可以把AI算法工程师的能力真正发挥出来的东西,作为算法工程师,一直以来感觉自己就是个废物,尤其是在Thoughtworks这种并不以算法和AI见长的技术公司,偶尔折腾个模型,顶多只是炫技的表演,当同事问我怎么把这个东西用在项目上,也只能尴尬的笑笑,实在抱歉,因为没有针对性的数据做训练,这个模型的精度可能无法满足实际上线的标准。算法可以被开发出来,但是却无法在实际生产中产生价值,遗憾之余不胜唏嘘,巧妇难为无米之炊,也许到最后优秀如我般的算法工程师只能离职另谋他就。
我们需要一个AI平台
所以,类似于Thoughtworks这种具有核心业务的企业们需要一个AI平台。
AI平台就是帮助企业基于现有资源充分、高效利用AI技术达到企业发展愿景的生产工具,重点在生产工具。凑近些会看到这个生产工具有多个输入:人才、数据、软硬件资源,而输出是针对业务场景的一个个或一组组的模型包,这些模型包对于企业现有的业务流程进行了或大或小的重构和变更,有的甚至颠覆了既有领域,更有甚者开拓了新的领域。
这个生产工具类似于计算机/操作系统 - AI资源(算法,AI硬件,数据)/AI平台,这只是从技术发展上进行的一次简单的类比,简言之,想充分利用AI资源(人才、软硬件资源、数据)来搞事情,搞好事情,企业级AI平台是绝佳的选择。
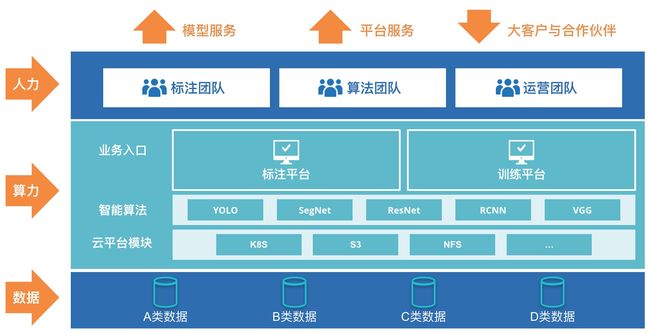
所以,到底什么样的AI平台才是具有核心业务价值的企业真正需要的呢?作为优秀的算法工程师,我们有必要告诉老板除了涨薪以外怎么才能构建一个真正的AI平台来让你一展所长。
AI平台的组成
所以,AI平台的构建首先是要满足算法工程师的日常工作需要。通常一个算法工程师的日常工作主要是模型构建、模型优化,这两者之间没有本质区别,可以细化为以下流程:
- 算法工程师根据自己设定的检索条件获取数据,并组装训练、测试和验证数据集;
- 算法工程师根据模型的需要对数据进行预处理;
- 算法工程师对于模型设定合适的超参数;
- 算法工程师申请GPU/CPU资源进行模型训练,查看模型的收敛效果;
- 算法工程师根据模型收敛情况和模型精度等指标判断模型优化是否成功;
- 算法工程师根据模型优化结果决定模型是否发布上线,如果达到上线指标,模型发布生产环境,正式上线,否则回到步骤1。
结合算法工程师的日常工作,不难发现AI平台至少具备以下四个部分:
数据准备
对于算法工程师而言,数据准备是非常重要,却希望尽可能少花费精力的工作。这里很容易让人困惑,“希望尽可能少的花费精力”和“非常重要”怎么看都是矛盾的,其实不然,数据准备其实是给模型训练准备输入数据,这些数据的质量直接关系到训练产出模型的实际精度、实际效果,模型优化中很重要的手段之一就是调整模型训练的数据集,由此可见,数据准备对于模型而言真的非常重要,那为什么算法工程师通常希望尽可能少的花费精力呢?其实是现有的数据准备过程异常复杂导致的。
想想看,现阶段算法工程师在进行模型训练前是怎么进行数据准备的:
- 首先,启动一个类似于Workbench一样的数据库管理工具;
- 链接正确的数据库,手动翻查目标自动在那个表里;
- 找到之后,基于Sql做一些简单的筛查;
- ... ...
额,忘记了,这是结构化数据,如果是图片或者长文本数据,数据量巨大的情况下呢 …… ,很不幸,算法工程师已卒。优化或者创建一个模型,竟然需要付出“生命”的代价来准备数据,万里长征仅仅是准备粮草就已经花费了两年时间,内战都结束了。
所以,提供高效的数据准备功能是AI平台必须具备的能力。至于实施方式,可以参看下图:
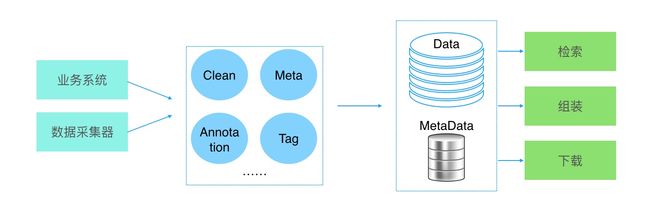
图中,蓝色圆圈标识一种数据处理程序,内涵可简单可复杂,其中:
- Clean:数据清洗,这是数据挖掘里的一个概念,一般包括预处理、处理缺失数据、处理格式或内容错误的数据、处理逻辑错误的数据、去除不必要的数据和关联性验证;
- Meta:基础元数据抽取,例如数据类型、创建日期、创建人等;
- Tag:数据打标签,对数据进行粗力度等描述,例如场景(晴天、上海、树荫)、文本语言等;
- Annotation:数据标注,这和AI领域强关联,NLP领域是对文本做实体标注、计算机视觉领域则是对图片进行实体标注,当然基于不同的应用场景,标注本身又包含多种形式,例如图像标注中的目标框选、语义分割、3D/2.5D标注等。
可能还存在其他的数据处理环节,但是就数据准备而言,这四个环节是必不可少的,至于理由,可以从数据准备最后提供的功能来了解,参看上图中的绿色方块:检索、组装和下载。
检索
数据检索的拆解参看下图:
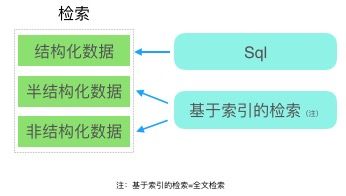
除了结构化数据,半/非结构化数据都是基于全文检索来实现的,如此这般,最核心的问题就转变为如何为半/非结构化数据构建合适的索引,从而方便的提供给用户进行数据检索和检索结果的排序。
而构建索引也恰恰是数据准备中最为困难和复杂的一个环节。之前讲到的数据处理环节Meta、Annotation、Tag都属于构建索引的范畴,不过,针对的数据类型、用途有区分,流程上也存在先后顺序,参看下图:

注:Annotation产生的索引信息,也可以称之为标注结果,这个环节起初是人手工标注,随着模型精度的提升,后续必然会演变为模型自动标注,这在后续的AI平台的演进和未来这一节会深入描述。
当各种维度的索引信息被构建之后,检索到目标数据将变得不再困难,目前,已经存在多种较为成熟的搜索技术框架可以帮助实现数据检索和排序的功能,不再赘述。
组装
数据组装,就是在检索功能之后,可以基于多次检索结果来构建目标数据集,这个场景实在常见,想想看,我期望构建一个可以分辨猫和狗的分类器,于是通过检索功能,分三次检索,分别得到了有猫、有狗以及同时有猫和狗的图片,当然,也许你会说,设置一个稍微复杂一些的检索条件,可以一次检索来获取相同的结果,没错,但是并不是每个人都熟悉这么复杂的检索语法,换言之,如果只想获取第一次检索的前10张图片、第二次检索的前30张图片以及第三次检索的所有图片,换算成一次检索的检索条件,其复杂度呈指数级上升。联想到之前数据准备的糟糕体验,没有数据组装功能的数据准备实在不能说有大的改善。
对于检索结果的组装并不仅仅是数据的简单组合,它内涵很丰富:
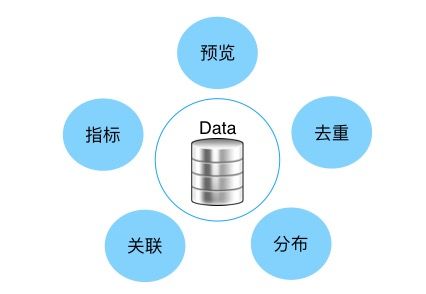
预览:在检索出结果以后,可以进行对象/记录粒度的数据预览,例如查看图片以及标注以后的图片、一封邮件的文本以及实体标注后的邮件内容等;更先进一些,在数据组装成数据集之后,也可以对数据集中的数据进行同样粒度的预览。
去重:多次检索的数据难免会有重复的数据出现,组装数据集的过程中需要进行去重处理。
关联:对于同一个目标数据的标注结果,需要进行合并或者关联,只有这样才能保证数据的完整性和准确性,同时减少冗余。
指标:用于衡量数据集质量,例如统计一个图片标注数据集中所有的标注对象数量,可以以直方图的形式展示;也可以基于一些算法或标准查看数据集中数据的分布情况。
分布:用于衡量数据集质量的高级功能,例如基于词向量查看一个文本数据集中文本或句子的聚类情况;对于时序类数据集基于指标展示时序分布图等。
数据组装的这些功能,看似和大数据平台的BI有些类似,但是有本质区别,大数据的BI是给业务人员看的,目标是辅助决策,数据组装里的指标和分布是给算法工程师看的,目标是模型优化,看似差不多,实则大不同。
下载
数据组装成数据集之后,就可以进行数据预处理,然后提供给模型进行训练了,那数据下载是必要的环节吗?很容易想到冰山理论,看到的只是漏出海面的冰山一角,背后其实存在着及其复杂的工作,数据下载就是隐藏在背后的一个尤为重要的功能。
数据检索、数据组装对于数据的操作基本都可以在内存中完成,但是组装后的数据提供给模型进行训练却不能再循此例,为什么?因为性能。
所以,组装后的数据集一定要下载到一个特定的存储介质,可以极大化的减少模型训练过程中数据加载的时间,这或许不是模型训练必须的,但是对于规模化、工业化的AI平台而言,这是必须的。
至于技术上使用什么样的存储介质,取决于模型训练中对于计算资源的调度方式,就目前大热的Kubeflow而言,使用专门针对Docker进行过I/O优化的技术方案是首选。
模型训练
模型训练可以理解为一个AI模型的集成开发环境——IDE。这个IDE提供一个资源包下载平台,算法工程师可以基于自己擅长的AI框架和语言来开发自己的算法,或者干脆从代码库里拉取一份现成的算法代码略做修改,算法、数据都有了,接下来只要倒数3、2、1,点击“start”或者“submit”,一个模型训练的任务就开始运行啦。对于用户视角,到此就结束了,然而对于AI平台而言,模型训练的工作才刚刚开始。
微软在2018年公布了自己的AI平台OpenPAI,并心思巧妙的将之集成到Visual Studio2017,你看,还真给做成了一个IDE。
那么AI平台到底是如何进行模型训练的?参看下图:

上图可知,模型训练核心是由两个pipeline构成:模型pipeline和数据pipeline:
数据pipeline
有别于数据准备阶段的数据处理环节,这里的预处理和模型、领域强关联,参看下图:
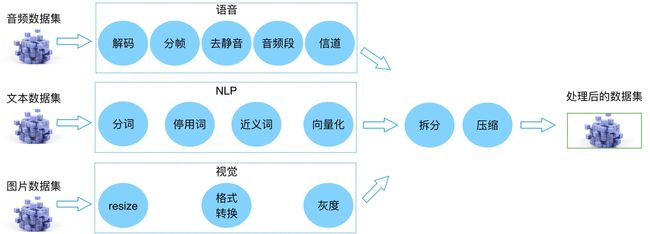
注:针对不同领域或数据的预处理可能罗列的不够全面,欢迎补充。
不同领域或数据的预处理有各自的特点,但是目标是相同的(其实,也有统一的名称:特征提取),就是将数据转换为模型算法可以接受的输入格式,对于深度神经网络算法而言,多数情况都会转换为张量格式。
有别于数据准备阶段的数据处理的第二个不同点是数据集预处理往往会涉及到复杂的算法,且数据量巨大,对于企业级的AI平台,借助于类似GPU这样的算力资源来进行处理是必然的,而技术上更先进的策略还会引入分布式计算,这是另一个话题。
模型pipeline
runtime阶段
模型pipeline准确的描述应该是模型训练pipeline,首先是runtime环节,这是IDE的精髓所在,查看下图:
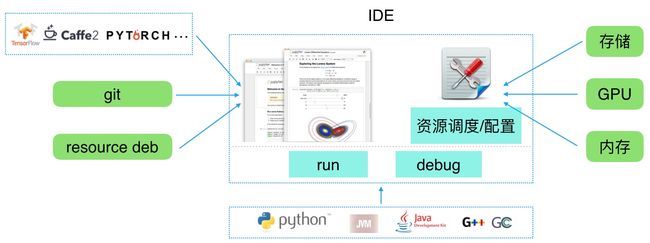
从这个角度去看微软把OpenPAI集成到VisualStudio实在是水到渠成的决定,不过对于企业自己的AI平台,Jupyter系列的技术方案也许更靠谱一些。runtime环节其实只是代码开发阶段,模型训练实际运行是在training阶段正式开始。
training阶段
training阶段的工作就类似于冰山理论中海平面以下的内容,参看下图:
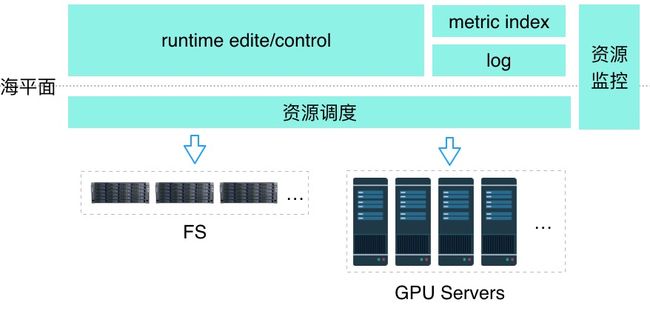
资源调度目前已经有了比较成熟的开源解决方案K8s(Kubernetes),尤其是针对存储和GPU资源的调度,K8s都提供了较为成熟的解决方案。
注:K8s并不保证兼容所有厂商和型号的GPU,也不保证兼容所有的FS,对于不同FS的I/O性能目前也没有官方的评测,具体的技术细节需要企业在实施过程中自行调研,这里不做展开。
模型验证
模型验证包含两个阶段:上线前的validation和上线后的A/B测试:
上线前的validation
这个环节通常包含在模型训练的阶段,在模型开发的过程中基于test/validation数据集调用所使用的AI框架提供的validation接口来编排,在模型训练的过程中,也会迭代计算validation的结果来展示模型的训练情况。
方法大体有两种:
- 留一验证:这个比较简单,就是从任务提供的数据中随机采样一定比例作为训练集,剩下的留作验证集。通常这个比例为4:1,也就是80%作为训练,20%作为模型验证。也有很多是会是3:1等等。这有一个问题,那就是随机采样验证集存在不确定性。验证集合不是测试集,这是不同的两个概念。
- 交叉验证:其实就是多次留一验证的过程。不过每次使用的验证集之间是互斥的,并且保证每一条可用数据都被模型验证过。例如所谓的5折交叉验证,就是将所有可用数据随机分为5分,每次迭代用其中一组数据作为验证集,其他四组作为训练集。相比留一验证,交叉验证更加可靠、稳定,因为所有数据都被训练和验证过。
所以,验证的形式和数据pipeline中的拆分环节有很大关系,设计的时候要考虑到这种灵活性。
上线后的A/B测试
A/B测试必然和实际的生产环境和业务场景相关联,原因很好理解,因为评价A和B两种方案的指标和业务场景强相关,例如一家金融机构有一个对贷款人做信用评级的模型,输入贷款人的相关信息,该模型可以计算出当前贷款人是否有能力偿还贷款或者违约的风险概率。那么A/B测试的评价指标就是违约率,违约率低的方案自然是好的方案。
那么对于企业的AI平台而言,结合自身业务构建业务端的A/B测试是必然的,参看下图:
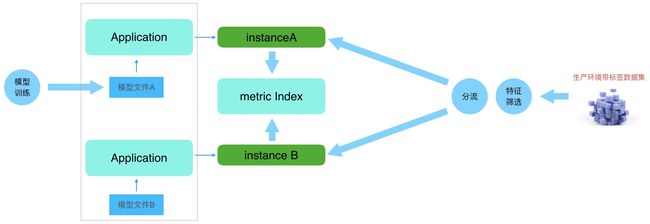
注:“生产环境带标签数据集”,这意味着这个数据集绝对是生产环境新产生的数据集,有别于模型训练中使用的测试集、验证集和训练集合,其次结合A/B测试的技术手段可知,metric Index是基于统计规律计算而来的评价指标,所以需要具备足够大的样本空间(参考大数定律),也就是“生产环境带标签数据集”需要数据量足够。
至于“生产环境带标签数据集”,恰恰和之前的“数据准备”对接上了,想想看,如果以数据的产生时间作为检索条件,这样的数据集在目前这样的AI平台上是不难获取的。
模型发布
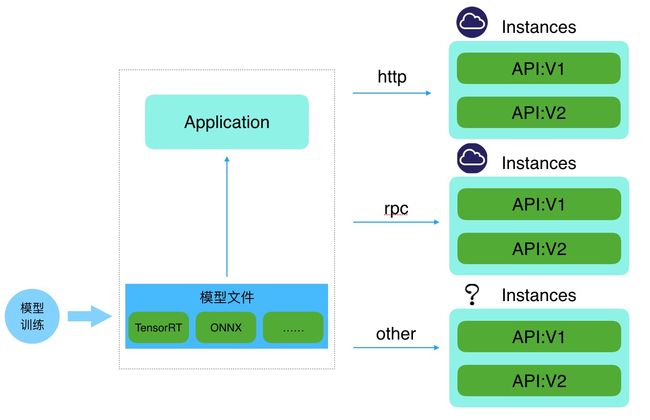
模型训练pipeline,目的是为了产出模型文件——可以抽象的理解为一个确定了参数的公式,当然,不同AI框架下产出的模型文件格式各异,这种标准不统一的问题已然在AI领域引起了充分重视,包括Google、微软等大厂都已经开源了自己的模型文件统一格式,虽然目前还没有那种格式可以全部支持所有热门的AI框架,不过也只是时间问题。企业在构建自己的AI平台时,需要根据自己的算法工程师常用的AI框架来决定选用哪一种格式,不求全覆盖,但求有价值。
注:对于通用模型文件格式,Google有TenserRT、微软有ONNX,由于目前对于此类技术的研究会同时涉及到AI框架和GPU芯片等硬件层,所以每种格式都会有特定的限制条件,构建AI平台时一定调研清楚再做选择。
除了通用的模型文件格式,另一个需要关注的点是模型发布的形式,当然,通用的搞法是通过启动一个应用服务来发布,应用服务接收外部request触发加载模型文件生成response返回,然而,这里的服务采用的协议根据不同的业务场景有区别。
对于企业AI平台而言, 基于http协议来发布加载模型的应用服务是必然的,因为有一个场景在企业AI平台上是始终会出现的——基于模型的Pre-annotation,这是AI平台演进的必然趋势,在AI平台的演进和未来这一节会深入讲解。
AI平台的通用架构
在通观AI平台的组成之后,AI平台的通用架构呼之欲出:
 通用架构.jpg
通用架构.jpg
AI平台的演进和未来
AI平台目前也仅仅处于行业高速发展的起始段,或许现在大张旗鼓的探讨AI平台的未来为时过早,但是结合目前企业级AI平台已然成型的实践经验对于AI平台的演进和未来也能窥探一二。
在文章伊始,AI平台被定义为一种生产工具,一种基于现有资源充分、高效利用AI技术达到企业发展愿景的生产工具。可想而知,在未来的发展进程上,生产工具的发展必然和企业自身的发展越发紧密,这种关系的进化可以通过下图有个大概的了解:
第一阶段:AI平台
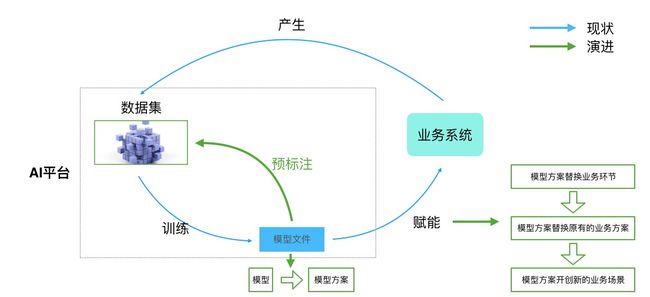
注:预标注就是Pre-annotation。
上图是AI平台第一阶段的演化,这种演化是基于功能的,简言之,对于AI平台以及业务系统中的各个环节,例如Annotation、生产流水线中的质检等,之前是基于人工或者粗放式逻辑来完成,后续会基于AI平台产出的AI模型来处理,更进一步,有一些业务线将完全基于AI模型方案实现自动化,例如Annotation,随着模型精度的提升,不久的将来,这些模型将完全取代人工标注是可以预知的。
第二阶段:中台发动机
当AI平台和业务越发紧密,基于AI平台能力的演进,更多的新业务、新场景、新能力被构建出来,此时,从业务发展的角度而言,软件服务的个性化、高度定制化必然会因AI技术的发展而成为新的趋势,这一点很好理解,业务系统的每个终端用户都是不一样的,随着个性化数据的累积,这种个性化必然会基于AI平台产出的模型体现在业务系统提供给终端用户的软件服务上。
从更高的视角来审视这种趋势,AI平台发展到一定程度必然变成构建企业中台的核心发动机,随着业务的高度精细化、个性化、智能化,企业对于AI平台也必然会提出新的需求和挑战,这些挑战无论是技术上的还是业务上的,都将是推动AI产业化进程的重要动力,让我们拭目以待!
总结
全文洋洋洒洒几千字,基于AI平台的实践经验梳理了AI平台的定位、核心组成、通用架构以及AI平台的演进和未来:
AI平台的定位:AI平台被定义为一种生产工具,一种基于现有资源充分、高效利用AI技术达到企业发展愿景的生产工具。
AI平台的核心组成:包括四个大模块——数据准备、模型训练、模型验证和模型发布。
AI平台的通用架构:层级架构,包括四个层级:借口层、APIs、Core Services、Platform Services。
AI平台的演进和未来:体现在两个层面,第一个层面是AI平台自己的演化:模型文件到模型解决方案;第二个层面是模型对于业务系统的改进,分三个阶段:替换业务环节演化到替换整体方案,最后到衍生出新的业务场景。最终联想到业务系统未来会向中台的方向演进,给出了企业中台中AI平台的价值和定位。
总体而言,就目前AI产业化发展的起步阶段,任何一个企业都有必要构建自己的AI平台,他是一个生产工具,是AI产业浪潮下的各企业渡江破浪的必备军舰,是企业基于现有资源充分、高效利用AI技术实现价值升级的必备工具。