网络爬虫是否合法?
网络爬虫合法吗?
网络爬虫领域目前还属于早期的拓荒阶段,虽然互联网世界已经通过自身的协议建立起一定的道德规范(Robots协议),但法律部分还在建立和完善中。从目前的情况来看,如果抓取的数据属于个人使用或科研范畴,基本不存在问题;而如果数据属于商业盈利范畴,就要就事而论,有可能属于违法行为,也有可能不违法。
1.2.1 Robots协议
Robots协议(爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。该协议是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应该遵守这项协议。
下面以淘宝网的robots.txt为例进行介绍。
这里仅截取部分代码,查看完整代码可以访问https://www.taobao.com/robots.txt。
User-agent: Baiduspider #百度爬虫引擎
Allow: /article #允许访问/article.htm、/article/12345.com
Allow: /oshtml
Allow: /ershou
Disallow: /product/ #禁止访问/product/12345.com
Disallow: / #禁止访问除Allow规定页面外的其他所有页面
User-Agent: Googlebot #谷歌爬虫引擎
Allow: /article
Allow: /oshtml
Allow: /product #允许访问/product.htm、/product/12345.com
Allow: /spu
Allow: /dianpu
Allow: /wenzhang
Allow: /oversea
Disallow: /
在上面的robots文件中,淘宝网对用户代理为百度爬虫引擎进行了规定。
以Allow项的值开头的URL是允许robot访问的。例如,Allow:/article允许百度爬虫引擎访问/article.htm、/article/12345.com等。
以Disallow项为开头的链接是不允许百度爬虫引擎访问的。例如,Disallow:/product/不允许百度爬虫引擎访问/product/12345.com等。
最后一行,Disallow:/禁止百度爬虫访问除了Allow规定页面外的其他所有页面。
因此,当你在百度搜索“淘宝”的时候,搜索结果下方的小字会出现:“由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取),系统无法提供该页面的内容描述”,如图1-1所示。百度作为一个搜索引擎,良好地遵守了淘宝网的robot.txt协议,所以你是不能从百度上搜索到淘宝内部的产品信息的。

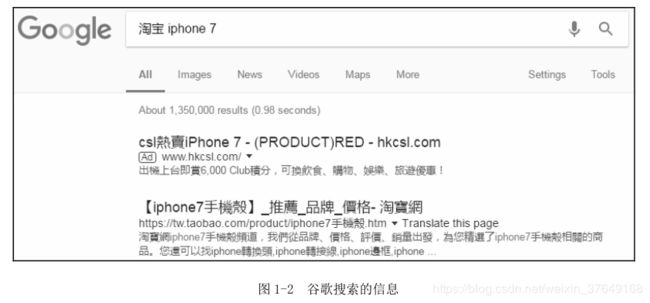
淘宝的Robots协议对谷歌爬虫的待遇则不一样,和百度爬虫不同的是,它允许谷歌爬虫爬取产品的页面Allow:/product。因此,当你在谷歌搜索“淘宝iphone7”的时候,可以搜索到淘宝中的产品,如图1-2所示。
当你爬取网站数据时,无论是否仅供个人使用,都应该遵守Robots协议。
1.2.2 网络爬虫的约束
除了上述Robots协议之外,我们使用网络爬虫的时候还要对自己进行约束:过于快速或者频密的网络爬虫都会对服务器产生巨大的压力,网站可能封锁你的IP,甚至采取进一步的法律行动。因此,你需要约束自己的网络爬虫行为,将请求的速度限定在一个合理的范围之内。
提示 本书中的爬虫仅用于学习、研究用途,请不要用于非法用途。任何由此引发的法律纠纷,请自行负责。
实际上,由于网络爬虫获取的数据带来了巨大的价值,网络爬虫逐渐演变成一场网站方与爬虫方的战争,你的矛长一寸,我的盾便厚一寸。在携程技术微分享上,携程酒店研发部研发经理崔广宇分享过一个“三月爬虫”的故事,也就是每年的三月份会迎来一个爬虫高峰期。因为有大量的大学生五月份交论文,在写论文的时候会选择爬取数据,也就是三月份爬取数据,四月份分析数据,五月份交论文。
因此,各大互联网巨头也已经开始调集资源来限制爬虫,保护用户的流量和减少有价值数据的流失。
2007年,爱帮网利用垂直搜索技术获取了大众点评网上的商户简介和消费者点评,并且直接大量使用。大众点评网多次要求爱帮网停止使用这些内容,而爱帮网以自己是使用垂直搜索获得的数据为由,拒绝停止抓取大众点评网上的内容,并且质疑大众点评网对这些内容所享有的著作权。为此,双方开打了两场官司。2011年1月,北京海淀法院做出判决:爱帮网侵犯大众点评网著作权成立,应当停止侵权并赔偿大众点评网经济损失和诉讼必要支出。
2013年10月,百度诉360违反Robots协议。百度方面认为,360违反了Robots协议,擅自抓取、复制百度网站内容并生成快照向用户提供。2014年8月7日,北京市第一中级人民法院做出一审判决,法院认为被告奇虎360的行为违反了《反不正当竞争法》相关规定,应赔偿原告百度公司70万元。
虽然说大众点评上的点评数据、百度知道的问答由用户创建而非企业,但是搭建平台需要投入运营、技术和人力成本,所以平台拥有对数据的所有权、使用权和分发权。
以上两起败诉告诉我们,在爬取网站的时候需要限制自己的爬虫,遵守Robots协议和约束网络爬虫程序的速度;在使用数据的时候必须遵守网站的知识产权。如果违反了这些规定,很可能会吃官司,并且败诉的概率相当高。
目录
前言
第1章 网络爬虫入门1
1.1 为什么要学网络爬虫2
1.1.1 网络爬虫能带来什么好处2
1.1.2 能从网络上爬取什么数据3
1.1.3 应不应该学爬虫3
1.2 网络爬虫是否合法3
1.2.1 Robots协议4
1.2.2 网络爬虫的约束5
1.3 网络爬虫的基本议题6
1.3.1 Python爬虫的流程7
1.3.2 三个流程的技术实现7
第2章 编写第一个网络爬虫9
2.1 搭建Python平台10
2.1.1 Python的安装10
2.1.2 使用pip安装第三方库12
2.1.3 使用编辑器Jupyter 编程13
2.1.4 使用编辑器Pycharm编程15
2.2 Python 使用入门18
2.2.1 基本命令18
2.2.2 数据类型19
2.2.3 条件语句和循环语句21
2.2.4 函数23
2.2.5 面向对象编程24
2.2.6 错误处理28
2.3 编写第一个简单的爬虫29
2.3.1 第一步:获取页面29
2.3.2 第二步:提取需要的数据30
2.3.3 第三步:存储数据32
2.4 Python实践:基础巩固33
2.4.1 Python基础试题34
2.4.2 参考答案35
2.4.3 自我实践题38
第3章 静态网页抓取39
3.1 安装Requests40
3.2 获取响应内容40
3.3 定制Requests41
3.3.1 传递URL参数41
3.3.2 定制请求头42
3.3.3 发送POST请求43
3.3.4 超时44
3.4 Requests爬虫实践:TOP250电影数据44
3.4.1 网站分析45
3.4.2 项目实践45
3.4.3 自我实践题47
第4章 动态网页抓取48
4.1 动态抓取的实例49
4.2 解析真实地址抓取50
4.3 通过Selenium模拟浏览器抓取55
4.3.1 Selenium的安装与基本介绍55
4.3.2 Selenium的实践案例57
4.3.3 Selenium获取文章的所有评论58
4.3.4 Selenium的高级操作61
4.4 Selenium爬虫实践:深圳短租数据64
4.4.1 网站分析64
4.4.2 项目实践66
4.4.3 自我实践题69
第5章 解析网页70
5.1 使用正则表达式解析网页71
5.1.1 re.match方法71
5.1.2 re.search方法74
5.1.3 re.findall方法74
5.2 使用BeautifulSoup解析网页76
5.2.1 BeautifulSoup的安装76
5.2.2 使用BeautifulSoup获取博客标题77
5.2.3 BeautifulSoup的其他功能78
5.3 使用lxml解析网页82
5.3.1 lxml的安装82
5.3.2 使用lxml获取博客标题82
5.3.3 XPath的选取方法84
5.4 总结85
5.5 BeautifulSoup爬虫实践:房屋价格数据86
5.5.1 网站分析86
5.5.2 项目实践87
5.5.3 自我实践题89
第6章 数据存储90
6.1 基本存储:存储至TXT或CSV91
6.1.1 把数据存储至TXT91
6.1.2 把数据存储至CSV93
6.2 存储至MySQL数据库94
6.2.1 下载安装MySQL95
6.2.2 MySQL的基本操作99
6.2.3 Python操作MySQL数据库104
6.3 存储至MongoDB数据库106
6.3.1 下载安装MongoDB107
6.3.2 MongoDB的基本概念110
6.3.3 Python操作MongoDB数据库112
6.3.4 RoboMongo的安装与使用113
6.4 总结115
6.5 MongoDB爬虫实践:虎扑论坛116
6.5.1 网站分析116
6.5.2 项目实践117
6.5.3 自我实践题123
第7章 Scrapy框架124
7.1 Scrapy是什么125
7.1.1 Scrapy架构125
7.1.2 Scrapy数据流(Data Flow)126
7.1.3 选择Scrapy还是Requests+bs4127
7.2 安装Scrapy128
7.3 通过Scrapy抓取博客128
7.3.1 创建一个Scrapy项目128
7.3.2 获取博客网页并保存129
7.3.3 提取博客标题和链接数据131
7.3.4 存储博客标题和链接数据133
7.3.5 获取文章内容134
7.3.6 Scrapy的设置文件136
7.4 Scrapy爬虫实践:财经新闻数据137
7.4.1 网站分析137
7.4.2 项目实践138
7.4.3 自我实践题141
第8章 提升爬虫的速度142
8.1 并发和并行,同步和异步143
8.1.1 并发和并行143
8.1.2 同步和异步143
8.2 多线程爬虫144
8.2.1 简单的单线程爬虫145
8.2.2 学习Python多线程145
8.2.3 简单的多线程爬虫148
8.2.4 使用Queue的多线程爬虫150
8.3 多进程爬虫153
8.3.1 使用multiprocessing的多进程爬虫153
8.3.2 使用Pool + Queue的多进程爬虫155
8.4 多协程爬虫158
8.5 总结160
第9章 反爬虫问题163
9.1 为什么会被反爬虫164
9.2 反爬虫的方式有哪些164
9.2.1 不返回网页165
9.2.2 返回非目标网页165
9.2.3 获取数据变难166
9.3 如何“反反爬虫”167
9.3.1 修改请求头167
9.3.2 修改爬虫的间隔时间168
9.3.3 使用代理171
9.3.4 更换IP地址172
9.3.5 登录获取数据172
9.4 总结172
第10章 解决中文乱码173
10.1 什么是字符编码174
10.2 Python的字符编码176
10.3 解决中文编码问题179
10.3.1 问题1:获取网站的中文显示乱码179
10.3.2 问题2:非法字符抛出异常180
10.3.3 问题3:网页使用gzip压缩181
10.3.4 问题4:读写文件的中文乱码182
10.4 总结184
第11章 登录与验证码处理185
11.1 处理登录表单186
11.1.1 处理登录表单186
11.1.2 处理cookies,让网页记住你的登录190
11.1.3 完整的登录代码193
11.2 验证码的处理194
11.2.1 如何使用验证码验证195
11.2.2 人工方法处理验证码197
11.2.3 OCR处理验证码200
11.3 总结203
第12章 服务器采集204

此书已加入到VIP会员卡,只要购买VIP会员卡即可免费阅读上百本电子书

阅读电子书的方法如下:
打开CSDN APP(软件商城搜索“CSDN”即可找到哦)—>登录CSDN账号—>学习—>电子书