2020抖音最新版去水印方法
最新版去水印的方法
对于经常刷抖音的人来说在保存视频的时候会发现视频会携带水印,下面是去完水印的样子


下面是去水印的具体方法,完整的代码在文章的最下方。
首先得拿到视频的分享地址就像下面这个一样
https://v.douyin.com/JYNyMo6/
然后我们直接请求的地址会是这个页面
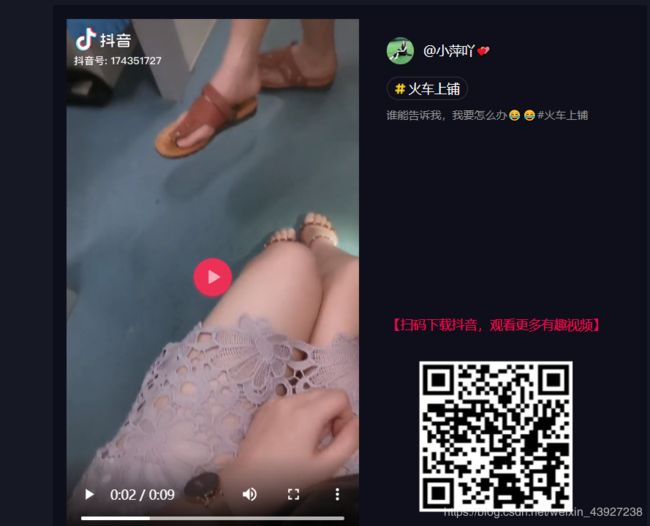
细心的人会发现上面的地址已经改变了,
https://www.iesdouyin.com/share/video/6850852785345400064/?region=CN&mid=6635819768786094852&u_code=i34h585b&titleType=title&utm_source=copy_link&utm_campaign=client_share&utm_medium=android&app=aweme
变成了上面的地址,先卖个关子往下看。当我们去右键检查的时候点开xhr会发现这个界面里面有熟悉的video字样,说明视频地址就是这个。我们只要拿到这个json的地址就可以了
**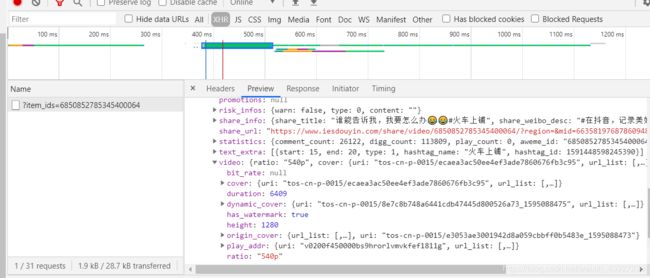
直接打开这个地址里面就有视频的地址,地址就是url_list内的地址

那我们怎么拿到这个json的地址呢?
https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=6850852785345400064
这个地址不难发现只有item_ids后面的数字变了,那我们怎么来到这个地址的呢,我们从上一层的地址也就是
https://www.iesdouyin.com/share/video/6850852785345400064/?region=CN&mid=6635819768786094852&u_code=i34h585b&titleType=title&utm_source=copy_link&utm_campaign=client_share&utm_medium=android&app=aweme`
这个视频的地址video后面的数字跟json的地址是一样的,那我们直接拿到这个数字直接拼接json的地址不就可以了。代码如下:
uq=re.findall('video/(\d+)/',str(est1.url))[0]
ur11=f'https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids={uq}'
那我们拿到这个json的地址之后,就应该去拿到视频的地址了,在json文件里面有视频的地址也有作者的信息,具体的东西自己去解析就行了。文章只提取了视频的标题和视频无水印的地址,当我们把视频地址复制下来打开发现还是带水印的,"https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f450000bs9hrorlvmvkfef1811g&ratio=720p&line=0",当我们把playwm替换成play的时候再用浏览器打开的时候发现打不开了,不要着急自己尝试下用手机打开,你们会发现手机能开也没水印,说明无水印的地址就是这个,不过得是手机端,那我们直接用手机请求头不就行了?当我们直接用手机的请求头请求时,发现能打开也能保存到本地,具体代码如下:
est2=requests.get(ur11).text
js1=json.loads(est2)
#视频的地址
url3=str(js1['item_list'][0]['video']['play_addr']['url_list'][0]).replace('playwm','play')
标题
title=str(js1['item_list'][0]['desc'])
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3329.0 Mobile Safari/537.36'}
est=requests.get(url=url3,headers=headers).url
到目前为止我们已经拿到无水印的地址了,这个地址在电脑端也是可以打开的
http://v3-dy-b.ixigua.com/26c9f5a4782ef181f0cc82e31d63c415/5f20393d/video/tos/cn/tos-cn-ve-15/26999eff3588428b94e7574d3ad67a37/?a=1128&br=3234&bt=1078&cr=0&cs=0&dr=0&ds=6&er=&l=20200728214159010012023024202E88B3&lr=&mime_type=video_mp4&qs=0&rc=ajQ0aG5wb3JrdjMzOGkzM0ApN2VnZDs0ZjtnNzc8NTw3N2cuNWNjc3NvbzZfLS0xLS9zc2FgNmE1MDEtMDRhYjYzNDQ6Yw%3D%3D&vl=&vr=
上面是播放的地址,那我们怎么保存呢?具体代码如下:
est=requests.get(url=url3,headers=headers)
with open(f'{title}.mp4','wb') as f:
f.write(est.content)
下面是本文的完整代码
也可以去github上去clone我的项目
#encoding=utf-8
import requests,re,json
url='https://v.douyin.com/JYNyMo6/'
est1=requests.get(url)
uq=re.findall('video/(\d+)/',str(est1.url))[0]
ur11=f'https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids={uq}'
est2=requests.get(ur11).text
js1=json.loads(est2)
url3=str(js1['item_list'][0]['video']['play_addr']['url_list'][0]).replace('playwm','play')
title=str(js1['item_list'][0]['desc'])
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3329.0 Mobile Safari/537.36'}
#est=requests.get(url=url3,headers=headers).url
est=requests.get(url=url3,headers=headers)
with open(f'{title}.mp4','wb') as f:
f.write(est.content)