Android进阶——性能优化之一种更高效更轻量的序列化方案Protocol Buffer完全攻略(十)
文章大纲
- 引言
- 一、Protocol Buffer概述
- 1、Protocol Buffer 的语言无关及平台无关
- 2、序列化和反序列化
- 3、Protocol Buffer 的优点
- 4、Protocol Buffer 的不足
- 5、Protocol Buffer 的数据结构
- 6、Protocol Buffer的序列化原理
- 7、Protocol Buffer的编码方式
- 7.1、Varint编码
- 7.2、Zigzag编码
- 8、T-V存储及原理
- 二、小结
引言
从早期时代网络编程应用XML作为数据交换的基本格式,再到后来Json 逐渐变成主流的数据格式,我想大部分对于这两种数据格式都不会陌生,今天就再介绍一种新的方案,一种更轻量的更高效的序列化方案——Protocol Buffer。以下是性能优化系列的链接地址列表(持续更新):
- Android进阶——性能优化之APP启动时黑白屏的根源解析及对应的优化措施小结(一)
- Android进阶——性能优化之APP启动过程相关源码解析(二)
- Android进阶——性能优化之APP启动速度优化实战总结(三)
- Android进阶——性能优化之布局渲染原理和底层机制详解(四)
- Android进阶——性能优化之布局优化实战经验小结(五)
- Android进阶——性能优化之内存管理机制和垃圾采集回收机制(六)
- Android进阶——性能优化之内存泄漏和内存抖动的检测及优化措施总结(七)
- Android进阶——性能优化之进程提权与保活原理及手段完全解析(八)
- Android进阶——性能优化之进程提权与拉活原理及手段完全解析(九
- Android进阶——性能优化之一种更高效更轻量的序列化方案Protocol Buffer完全攻略(十)
一、Protocol Buffer概述
Google Protocol Buffer( 简称 Protobuf) 是 Google 公司内部的混合语言数据标准,目前已经正在使用的有超过 48,162 种报文格式定义和超过 12,183 个 .proto 文件,他们用于 RPC 系统和持续数据存储系统、可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以高效对结构化数据进行序列化或反序列化。以上为官方定义,接下来将就我的理解逐一说明下:
1、Protocol Buffer 的语言无关及平台无关
Protocol Buffer 顾名思义“协议缓冲区”(或许不是很精确,但是本质差别不大),实际上是Google 开发的一整套方案,主要包含两部分:接口描述语言(Interface Description Language)和平台语言编译器:
-
接口描述语言(Interface Description Language)——该接口语言定义了一整套基本的语法规则,开发者根据语法编写用于描述数据结构的.proto文件。
-
平台语言编译器——方案提供了Java、C++、C#、Python、ObjectC、JavaScript、Ruby、Php语言对应的编译器,用于把** .proto 文件编译为对应语言的源文件 (比如说对Java来说,通过对应的Java语言编译器编译为对应的.java文件),这也是为什么说与平台无关!简单来说,同一个.proto源文件可以应用于全平台,因为对于平台来说.proto文件是无差别的,其实这个机制有点类似Java的跨平台,我们开发语言不是直接使用.proto文件,而是使用经过编译之后的产物。
2、序列化和反序列化
- 序列化——将数据结构或对象转换成二进制串的过程
以下为序列化的核心代码
if ((value & ~0x7F) == 0) {
buffer[position++] = (byte) value;
return;
} else {
buffer[position++] = (byte) ((value & 0x7F) | 0x80);
value >>>= 7;
}

- 反序列化——将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程
3、Protocol Buffer 的优点
-
采用灵活的编码方式,序列化之后体积小,相比XML、JSON数据体积可缩小3——10倍,可以节省网络传输的带宽消耗同时提高减少传输耗时。
-
序列化速度快,相比XML、JSON数据体积可缩小3——10倍。
-
使用便捷,方案提供了一系列的API,无需第三方只需调用自身API就可以完成序列化和反序列化操作。
-
与平台无关,与语言无关,一个.proto文件可以应用在全平台
-
向后兼容性强,不需要破坏旧数据格式就可以直接对数据结构进行更新,维护成本低
-
采用字节传输,具有一定的加密性
基于以上特点Protocol Buffer 适用于传输数据量大且网络环境不稳定的数据存储、RPC数据交互的场景(比如说即时IM的应用),因为在传输数据量较大的需求场景下,Protocol Buffer 比XML、JSON更高效,当然这里是从整个项目的成本去考虑的,包括开发、维护及软硬件成本等等,个人觉得你可以在你使用XML、JSON格式存储文件时都可以考虑下Protocol Buffer。
4、Protocol Buffer 的不足
不过呢Protocol Buffer不适合用于对基于文本的标记文档(比如说HTML)建模,因为文本不适合描述数据结构,由于采用二进制流方式存储(不可读)必须依赖.proto文件才能知道数据结构,导致自解耦性较差,再者Protobuf 最早只是应用于Google内部的(Android Studio 自身也有用到xx\AndroidStudio3.0\lib),没有像XML、JSON它们早已成为行业标准具有很强的通用性。
5、Protocol Buffer 的数据结构
Protocol Buffer是本质是以二进制数据流的形式存储的,具体采用TLV(全称Tag-Length-Value 即标识-长度-字段值)结构存储,不需要使用额外的分隔符就可以隔开字段,减少了额外分隔符的消耗,各个字段存储得非常紧凑,自然存储空间利用率十分高,而且假如字段值没有被设置,那么该字段在序列化时的数据中是完全不存在的(即这个字段不需要进行编码)。

6、Protocol Buffer的序列化原理
Protocol Buffer实现序列化,主要是通过对消息里的每个字段进行灵活编码,按照T-L-V形式存储,最终得到一个二进制字节流,对于不同的数据类型采用不同的序列化(即编码)方式,主要有四大类数据类型:

以上表格的意思就是,Protobuf 把数据大致分为四组,比如int32、int64等类型使用Varint编码。
7、Protocol Buffer的编码方式
在学习Protobuf的编码方式时,你或许需要复习下关于计算机进制的相关知识。
7.1、Varint编码
Varints是一种使用一个或多个字节序列化整数的方法, 较小的数字占用较少的字节数。首先1对应二进制为0000 0001只需要使用一个字节存储就够了,而300需要使用两个字节存储,对应二进制1010 1100 0000 0010,当然这是最原始的二进制码,Protocol Buffer采用Varints进行编码优化,过程如下:

解码很简单,把Varint编码后的字节进行位置交换,并且忽略字节的最高位,再取加权和:
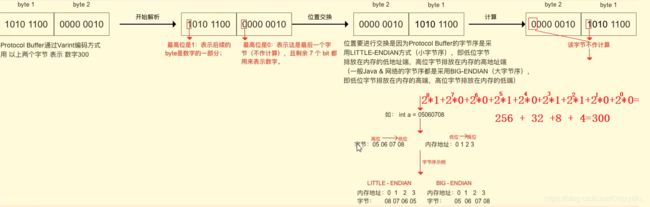
采用Varint方法对于很小的int32类型的数字(小于256)可以仅适用1个字节来表示,虽然大的数字需要5个字节来表示,不过据Google 统计消息都不会有很大的数据,因此采用Varint 编码方式可以有效节省字节数表示数字,从而实现数据压缩。
7.2、Zigzag编码
如果采用Varint 编码一个负数,那么一定需要5个字节来表示(因为负数的最高位为1,会被当成很大的整数去处理)所以Protobuf 定义了sint32 、sint64类型来表示负数,首先通过Zigzag编码将有符号数转为无符号数,再采用Varint编码,从而有效减少编码后的字节数。
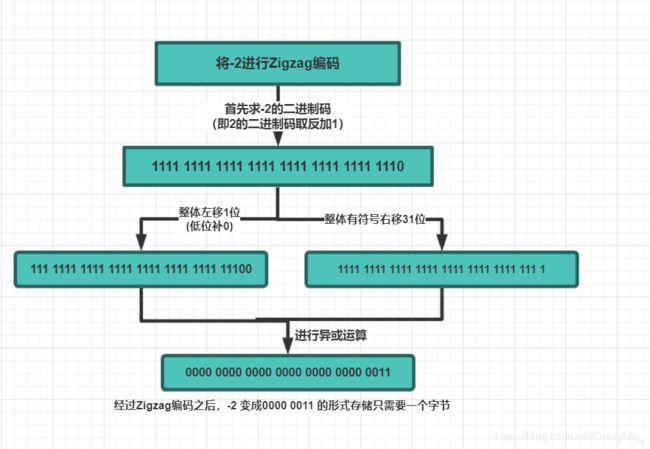
对于int32、int64类型的字段值(正数),Protobuf 直接采用Varint方式进行编码;而对于sint32、sint64类型的则先进行Zigzag编码再采用Varint编码。
8、T-V存储及原理
- Tag编码原理
Tag的取值根据公式(field_num << 3)| type的计算结果,其中type取值上表中的0——5,field_num 并不是对应的字段值而是定义.proto文件时设置的"Id"值,只需要三位表示。
- Value的编码原理
根据类型采用灵活的编码方式。
syntax = "proto2";
package user;
option java_package = "com.crazymo.user";
option java_outer_classname = "Demo";
message Worker {
//type =0 ,field_number=1
//Tag =(field_number << 3) | type => 1000 =8
required int32 age=1;
//type =0 ,field_number=2
//Tag =(field_number << 3) | type => 1000 =16
required int32 weight=2;
}
//.java代码
Demo.Worker worker=Demo.Worker.newBuilder()
.setAge(300)
.setWeight(296)
.build();
byte[] bytes=worker.toByteArray();
//输出[8,-84,2,16,-88,2] 这就是采用Varint编码存储的缘故,从上面
Log.e("CrazyMo",Arrays.toString(bytes);
输出 [8,-84,2,16,-88,2] 这就是采用Varint编码存储的缘故,从上面得知
二、小结
- 尽量多使用 optional 或repeated 修饰符,因为被optional 或repeated修饰的字段没有被设置值,那么对应的字段在序列化时的数据中是完全不存在的,即是不需要进行编码的。
- 字段标识好(Field_Number)尽量使用连续的且范围控制在1——15,且不要跳动使用,因为Tag编码时候需要涉及到Field_Number,必然是占存储空间的,如果Field_Number >16时就需要占用2个字节,Tag在编码时自然占用更多的字节,而且将Field_Number定义为连续递增的数值,编解码性能也会更好。
- 若出现负数,请使用sint32/sint64,不要使用int32 /int64 ,因为采用sint32/sint64时会先采用Zigzag编码进行优化再采用Varint。
- 尽量对repeated 字段使用packed=true修饰,因为添加了packed=true的repeated字段将会采用T-L-V-V-V连续存储的形式。
PS:未完待续,由于篇幅问题,Protobuf的简单使用见下文