你还不懂Unicode、UTF8、UTF16、UTF32吗!?
JAVA学习笔记190919
字符编码是计算机技术的基石,想要熟练使用计算机,就必须懂得一点字符编码的知识。关于这个知识的学习我也参考了很多其他人的学习笔记,但是基本是大同小异,不过有一篇是真的还不错,供大家参考。(但主要说的是UTF-8和Unicode的关系)
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
Unicode是什么
Unicode是计算机领域的一项行业标准,它对世界上绝大部分的文字的进行整理和统一编码,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。(摘自百度百科)
Unicode的编码空间可以划分为17个平面(plane),每个平面包含2的16次方(65536)个码位。17个平面的码位可表示为从U+0000到U+10FFFF,共计1114112个码位。Unicode 为世界上所有字符都分配了一个唯一的数字编号,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。Unicode 就相当于一张表,建立了字符与编号之间的联系。
但是需要区分的是,unicode是编码字符集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
UTF-32
UTF-32编码以32位无符号整数为单位。Unicode的UTF-32编码就是其对应的32位无符号整数。UTF-32 是固定长度的编码,始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 编号即可,不需要任何编码转换。浪费了空间,提高了效率。简单的说,这个就是直接转换,就是字符所对应编号的整数二进制形式,四个字节。 比如马的 Unicode 为:U+9A6C,那么直接转化为二进制,它的表示就为:1001 1010 0110 1100。
UTF-32 用四个字节表示,但一次拿到四个字节进行处理的时候如果不分大小端的话,就会出现解读错误,比如我们一次要处理四个字节 12 34 56 78,这四个字节是表示 0x12 34 56 78 还是 0x78 56 34 12?不同的解释最终表示的值是不一样的。
所以我们 用UTF-32BE 和 UTF-32LE两种高低字节的存储位置来判断他们所代表的含义,分别对应大端和小端,来正确地解释多个字节(这里是四个字节)的含义。(如下图)

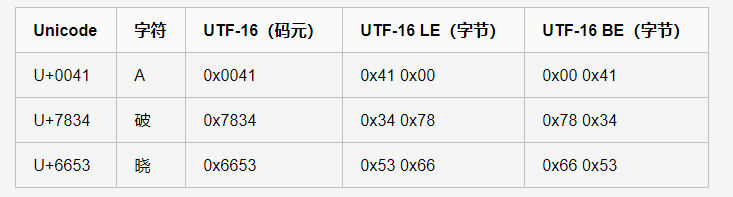
UTF-16
UTF-16编码以16位无符号整数为单位。UTF-16 使用变长字节表示 ,即① 对于编号在 U+0000 到 U+FFFF 的字符(常用字符集),直接用两个字节表示;编号在 U+10000 到 U+10FFFF 之间的字符,需要用四个字节表示。
同样,UTF-16 也有字节的顺序问题(大小端),所以就有 UTF-16BE 表示大端,UTF-16LE 表示小端。(如下图)
UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式,而像前面介绍的32、16其实在互联网上基本不用。UTF-8 和UTF-16其实比较相似,也是变长字节,但最大的一个特点是对不同范围的字符使用不同长度的编码,就是它可以使用1~4个字节表示一个符号,而这个变化是根据 Unicode 编号的大小有关,编号小的使用的字节就少,编号大的使用的字节就多。使用的字节个数从 1 到 4 个不等。
UTF-8 的编码规则很简单,只有二条:
①对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
②对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。

跟据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
下面,还是汉字“严”为例,演示如何实现 UTF-8 编码。
严的 Unicode 是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5。
它们之间的关系
需要注意的是unicode是编码字符集,而UTF-8、UTF-16、UTF-32是字符集编码。
比如汉字的”汉”,在unicode中,汉”的unicode值为0x6C49。问:把这个”汉”字保存到计算机中(硬盘、内存),机器码是多少呢?
学过《计算机组成原理》的人都知道,计算机内部存储的形式都是0101的二进制数字串。”汉”字保存在计算机里肯定也是0101的数字串。”汉”的unicode值是0x6C49,转化为2进制 1101100 01001001,那么把这个”汉”字保存到计算机中也是 1101100 01001001 吗?答案是否定的,根据上面我们介绍的三种字符集编码我们可以知道这取决于用到的字符集编码是哪种。
比如你用到的字符集编码是UTF-8,那么”汉”字在计算机内部保存的值为0xE6B189,也就是111001101011000110001001,可以看到”汉”字变成了3个字节。而如果用UTF-16来保存,那么”汉”字仍为0x6C49,也就是 1101100 01001001。而UTF-32也仍为0x6C49,也就是 1101100 01001001。
所以这就是编码字符集和字符集编码的区别。
这么整理完大家对这些的认识有没有更清晰呢?