印度金融服务公司 Zerodha 使用 Prometheus 在基础监控领域的实践

在 Zerodha,我们每一天要处理整个印度所有证券交易所每天交易量中大约 15% 的业务。这个过程中产生的数以十亿计的请求均交由我们内部构建的一套系统来处理。此外,我们特别致力于实现尽可能自托管更多的依赖组件,从各种 CRM 系统到大型数据库,Kafka 集群,邮件服务器等等。
为了支持这些主要系统,我们需要运行大量的辅助性质的工作负载,包括一些实时交易,文档处理,KYC 和开户,法律和合规性检查,复杂的、大规模的 P&L 和数字处理,以及各种各样的后台任务。这些系统交错地分布在各地;它们的物理机架横跨两个不同的数据中心(即交换机专线终止的地方)和 AWS。所有的这一切意味着我们拥有大量的动态工作负载和不尽相同的系统及环境,从裸机到 Kubernetes 集群,它们都需要被单独监控起来。
Prometheus

我们选择 Prometheus 的原因主要是看在它提供了一套统一标准的时间序列指标以及内置的一套强大的查询语言(我们确实评估了多个方案,比如 Sensu,Nagios,ELK 等,只是为了再确认一下)。Prometheus 最初是由 SoundCloud 开发的,它借鉴了 Borgmon 的一些想法。自那以后,它已经成为一个活跃的,独立的 FOSS 项目,有着活跃的社区参与。它也是 CNCF 基金会的一部分。
Prometheus 提供了一套多维方案来识别带有所谓标签(label)键值对的指标数据。借助PromQL,我们可以使用标签来过滤和汇总这些度量。不妨举个例子,当我们需要按照 HTTP 状态码将请求数分组的时候,我们可以编写如下的查询语句:
sum by (status) (rate(http_requests_total[5m]))
服务发现
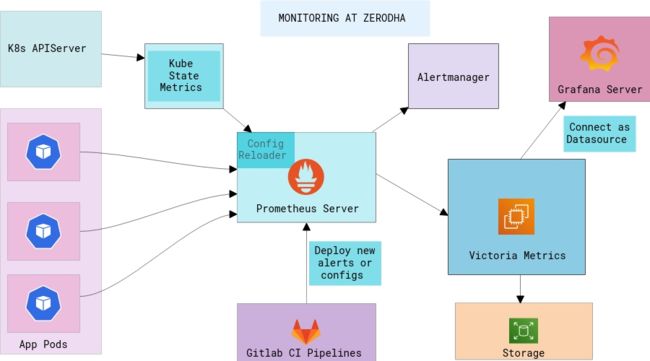
Prometheus 采取的是一种自上而下的“pull”模式,这意味着 Prometheus 需要先“发现”然后再从目标实例拉取对应的指标数据。这些目标可以是 EC2 实例,Kubernetes pods,又或者是一个包含了主机 IP 列表的简单 JSON 文件。老实说,在一个多机房、裸金属加云的环境里维护一个 IP 列表并不那么容易。
值得庆幸的是,Prometheus 拥有一个服务发现模块,它支持可插拔的对接各种云厂商后端,然后使用它来发现实例。在 Zerodha,我们使用 AWS 来承载我们所有云基础设施的需求,因此 ec2_sd_config 模块就够用了。我们使用 Packer 来定制我们的 AMI 镜像,然后再在系统里安装一组预配置好的 exporter。所谓 exporter,即是一组轻量的后台守护进程,它们会通过一个 HTTP 接口向Prometheus 暴露它们的指标数据。服务发现模块用起来非常顺手,我们只需要给相应的 EC2 加上 monitoring:enabled 的标签即可让 Prometheus 发现这些实例。下面是我们用来发现实例的 Prometheus 作业配置的相关片段:
- job_name: "zerodha-ec2"
ec2_sd_configs:
- region: ap-south-1
port: 9100
# Only monitor instances with tag monitoring
- source_labels: [__meta_ec2_tag_monitoring]
regex: "enabled"
action: keep
遍布多个机房的裸金属机架上同样也运行着多个 exporter 程序。这些机架通过 P2P 专线连接到我们的 AWS VPC 网络。由于这些实例事先已经配置好了对应的静态 IP ,和云环境不同的是,我们可以使用 static_config 模块来抓取这些目标实例的指标数据。如下一段简短的代码片段说明了这一点:
- job_name: "dc1-server-node"
scrape_interval: 1m
metrics_path: "/dc1/node-exporter/metrics"
scheme: "http"
static_configs:
- targets: ["dc1.internal"]
labels:
service: dc1-server
relabel_configs:
- source_labels: [__address__]
action: replace
replacement: "dc1-server"
target_label: hostname
跑在 Kubernetes 上的 Prometheus
最近,我们开始将各种类型的工作负载迁移到 Kubernetes 上,主要为了实现统一部署。相同的监控组件如果部署到了多个集群,然后又希望 Prometheus 是高可用的话,这就不那么容易了。下面是一些不得不首先解决的痛点:
Kubernetes 对象会产生大量的时序数据
我们运行了 kube-state-metrics,它会将每种 resource 类型对象的元数据存储到 Kubernetes。在 Kubernetes 里,你可以部署一个 metrics-server,HPA 控制器会借助它基于内存/CPU 规则来扩缩 Pod。但是,由于 Pod 天然就是非常动态的,有必要监控的就不仅仅只是 CPU 和内存这些数据了。目前,kube-state-metrics 支持大约 30 种资源,它们在一起共同产生了大量的数据。因此,首要目标就是先找到一个解决方案,它可以在任何给定的时间内在所有集群之间处理数亿个活跃数据点。
解决每个集群的存储问题
尽管 Prometheus 的实例是独立地部署在每个集群里,但是手动管理每个实例的长期存储并不可行。引用官方文档的说法是:
"注意,本地存储的局限性在于它不是集群式的或者说副本式的。因此,当遇到磁盘或者节点中断的情况,它不是任意可扩展的或是可持续的,我们应当像对待任何其他类型的单节点数据库一样对待它。"
这意味着存储会受限于该特定节点的可用性和可扩展性。值得庆幸的是,Prometheus 本身支持集成远程存储,我们研究了为 Prometheus 创建长期存储集群的各个方案。它的基本思想是,所有 Prometheus 节点都会将指标数据推送到一个存储集群里,在这里我们可以集中式地设置保留策略、备份和快照等。这比把数据分散在基础设施里的各个单独的 EBS 卷要容易管理得多。
我们着手探索过 Thanos,它在为 Prometheus 拓展高可用方面非常受欢迎。但是 Thanos 原本有很多组件,而我们只是想将它启动起来然后运行的话似乎没有必要引入这么多的运维复杂度。
Victoria Metrics 是另外一个相对比较新的项目,它在成立之初便致力于提供和 Thanos 类似的功能。不同的是,它是通过单个的二进制文件来交付的!早在 Victoria Metrics 还处于早期开发阶段时,我们就已经对 valyala 的(Victoria Metrics的主要贡献者)一些Go项目有所了解,这为我们之后的选型评估注入了额外的信心。它的基准测试 结果表现的相当不错,似乎表明和其他同类产品相比,它的数据提取性能更好,同时使用的 RAM 和磁盘空间也更少。
Prometheus 会将采集的指标数据写入本地磁盘存储,然后将其并行复制到远程存储。它维护一个WAL(预写日志),这意味着即使远程存储端点不可用时,指标数据也会在 --storage.tsdb.retention.time 时间内保留在本地存储。
在基于保留策略进行常规地定期清理之后,我们的 Victoria Metrics 集群里目前存储了约 560 亿个时间序列数据点。

平均而言,我们每秒会采集数万个时间序列指标(来自多个 Kubernetes 集群和 EC2 节点)。
VictoriaMetrics 本身就原生支持 Prometheus 的查询 API,这意味着它也可以直接充当Grafana 中的 Prometheus 数据源。我们可以使用相同的 PromQL 查询然后跨集群聚合指标,这一点真的很了不起。它针对具有高分叉率的时间序列指标进行了高度优化,并且还针对存储操作进行了优化。
根据我们的经验,单节点 Victoria Metrics 实例能够处理大量的时间序列数据而完全不显得吃力。
运维和管理集群之间的配置
我们使用 Prometheus Operator 来部署完整的 Prometheus 组件栈以及诸如 Node Exporter 和 Kube State Metrics 之类的辅助服务。Kubernetes Operator 是使用 Kubernetes SDK 管理应用程序整个生命周期的一种方式。配置的创建/删除/扩展和重新加载都由 Operator 处理。例如,我们可以使用 Kubernetes 原生的 spec 来配置 Prometheus:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
prometheus: k8s
name: k8s
namespace: monitoring
spec:
replicas: 3
externalLabels:
cluster: zerodha-k8s
remoteWrite:
- url: http://:8428/api/v1/write
我们大量使用 Kustomize 来组织 Kubernetes 清单文件,并围绕这块开发了一个小的实用程序 kubekutr。对于所有的 Prometheus Operator 的配置管理,我们也采用了 Kustomize 的 base 和 overlay 玩法。
它的理念是,每个集群所有的公共监控配置都称为 “base”,然后每个集群一些特殊唯一的配置被称为 “overlays”。在任意类型的联合设置中,指标采集实际都是从外部处理的,每个指标都需要有一个唯一的标识符用来标识来自不同的集群源。在没有唯一标识符的情况下,有可能从 2 个不同的集群发出的指标难以区分,从而导致采集了错误的数据。
我们可以将每个 Prometheus 实例配置为始终随生成的每个指标配置一个唯一的标签。以下是一个例子:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
prometheus: k8s
name: k8s
namespace: monitoring
spec:
replicas: 1
externalLabels:
zero_cluster: eks-cluster-dev
remoteWrite:
- url: http://monitoring.internal:8428/api/v1/write
additionalAlertManagerConfigs:
name: external-alertmanager
key: external-alertmanager.yml
在 .spec.externalLabels 字段中,我们将 Prometheus 实例配置为给发送的每个度量名称上都带有一个 zero_cluster:eks-cluster-dev 的标签。当查询任何度量数据时,我们可以看到已经正确加上了对应的标签:
{prometheus_replica="prometheus-k8s-0",zero_cluster="eks-cluster-dev"}
在上面的示例中,我们在每个集群中对 base 配置所做的一些额外覆盖都是可见的。例如:
副本数:根据该集群的工作负载自定义要运行的 Prometheus 实例的数量。
远端 Prometheus:远程存储 API 端点(在本例中为 Victoria Metrics)。
外部 alertmanager 端点:由于 Alertmanager 在集群外运行,因此我们在此处指定alertmanager 的配置。
Alertmanager
我们运行一个集中式的 Alertmanager 集群。所有 Prometheus 实例都直接连接到该集群。Alertmanager 可以对告警进行数据去重,这样一来通知系统在处理相同类型的告警时不会过于嘈杂。告警可以推送到任何目标,例如电子邮件和IM客户端。举个例子,使用 Alertmanager Webhook 接收器的话,通过采用我们编写的简单工具,它将会把告警推送到 Google chat。

我们所有的告警规则和配置都放在 GitLab 存储库中进行版本控制。GitLab CI 流水线可以检查并验证配置,然后将其上传到S3存储桶。Alertmanager 集群里有一个同步服务器,用于检查新配置,并在任何配置更新时自动重新加载 Alertmanager。

定制 exporter
我们有定制的 exporter 程序,它们对外公开了一些我们服务中的语义信息。
我们编写了一个通用的 store-exporter,它可以从任意 SQL 数据存储(如 PostgreSQL / MySQL)中获取数据,并以 Prometheus 指标格式的形式对外公开。我们还使用它来采集业务指标并在 Grafana 上进行可视化。这也使我们能够为偏离预期业务的“异常”行为设置告警。
我们也有一个基于 fasthttp 的可嵌入 HTTP exporter,用于公开各种内部 HTTP 服务的 RED 指标。VictoriaMetrics/metrics 库是官方提供的一款不错的轻量级替代方案,它的依赖项少得多。
旁注:我们特别注意在关键应用程序中将程序包的依赖关系保持在一个最低限度。这是我们每隔一个合理的时间定期会回顾的事情。
除了应用程序指标外,我们还使用 exporter 从各种 AWS API 中收集元数据。例如:
AWS P2P Direct Connection 带宽和运行状况。
提醒检查 EBS 快照策略和备份的告警。
Grafana
我们运行一个非常标准的 Grafana 6.x 实例,该实例会连接我们的主数据源(即 Victoria Metrics)。这上面已经有几十个定制看板以及监控股票相关的 Postgres,HAProxy,NGINX,MySQL 等的看板。




小结
这是我们在 Zerodha 涉及多个物理机房以及 AWS 基础设施的混合环境中构建监控栈的经验。我们已将 Victoria Metrics 用于长期的 Prometheus 存储,目前它在任意时间点均包含了数百亿个事件。我们在裸机集群和 Kubernetes 集群上设置了高可用的 Prometheus 集群。我们还开发了各种各样的指标 exporter,可以从我们的系统中收集各种信息,包括 HTTP,应用程序和基础设施特定相关的指标,AWS 元数据和业务指标。我们使用 Alertmanager 集群来生成告警,该集群已经和我们的IM工具做了集成。
我们的日志栈(ELK)具有数个TB数据的各种日志,其中一些日志必须保留数年才能符合法规,这会是以后的主题。敬请关注。
干杯!
原文链接:https://zerodha.tech/blog/infra-monitoring-at-zerodha/
基于Kubernetes的DevOps实战培训
基于Kubernetes的DevOps实战培训将于2020年8月14日在上海开课,3天时间带你系统掌握Kubernetes,学习效果不好可以继续学习。本次培训包括:容器特性、镜像、网络;Kubernetes架构、核心组件、基本功能;Kubernetes设计理念、架构设计、基本功能、常用对象、设计原则;Kubernetes的数据库、运行时、网络、插件已经落地经验;微服务架构、组件、监控方案等,点击下方图片或者阅读原文链接查看详情。
