Cloudera Manager 中角色迁移和配置的一些操作记录
最近大数据集群中有一台节点磁盘坏掉,因为用的aliyun服务器,在考虑现有业务不需要太多的服务器资源,准备下架这台坏掉的服务器,记录一下其中的一些操作
版本信息:CDH 6.0.1
1.先需要造的是 zookeeper 因为依赖他的组件必须先能找到健康的它才能干活

停掉坏的 server 节点,添加角色

添加完后zookeeper必须是奇数台才行,现在删掉那个坏的
配置文件过期需要中心这个zookeeper服务

这样依赖 zookeeper 的其他服务就得重新部署这个server才行
造完之后重启-重新部署 完了之后看看结果
2.hadoop003节点的 DataNode 和 JournalNode 都出现了问题,现在也需要迁移

选中停机提醒后继续
等待重新完成。。。。。。。。。。。。
JournalNode 和 zookeeper 一样都需要 奇数 台的服务才行,
3.ResourceManager 现在也坏了,但是我在其他节点添加一个ResourceManager 后他的配置立即发生变化,高可用 配置显示出来
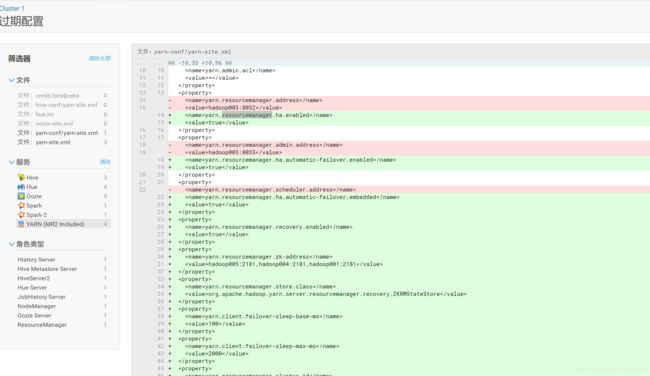
在hadoop005上安装了一个 ResourceManager 后发现启动不了,最后在报错日志里面发现
Error starting ResourceManager
org.apache.hadoop.HadoopIllegalArgumentException: Configuration doesn't specify yarn.resourcemanager.cluster-id
at org.apache.hadoop.yarn.conf.YarnConfiguration.getClusterId(YarnConfiguration.java:3390)
at org.apache.hadoop.yarn.server.resourcemanager.ActiveStandbyElectorBasedElectorService.serviceInit(ActiveStandbyElectorBasedElectorService.java:90)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.service.CompositeService.serviceInit(CompositeService.java:108)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.serviceInit(ResourceManager.java:326)
at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.main(ResourceManager.java:1420)增加到两台 ResourceManager 后设备 自动开启了HA 但是没有配置 yarn.resourcemanager.cluster-id 这个需要手动添加
cluster-id = yarn-ha
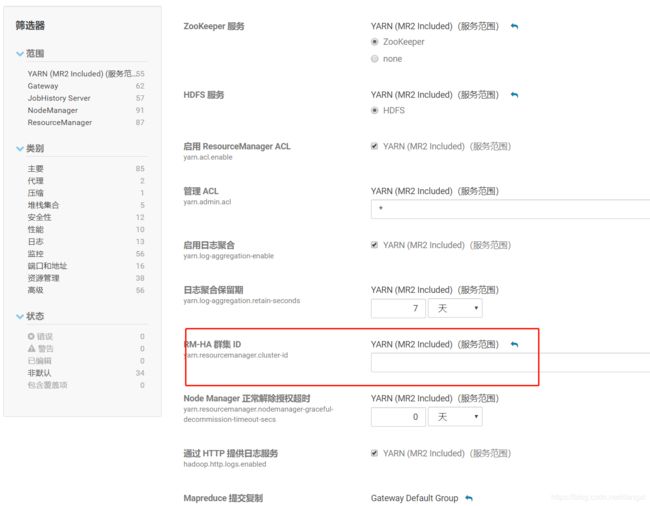
然后重新启动服务
就可以启动 resourcemanager 了
现在再把hadoop003 上的 resourcemanager
和 nodemanager 删除掉,添加角色在hadoop004S上面,可以看到配置,现在YARN 的 HA H和配置信息

重启----重新部署
等到重启完成。。。。。。。。。。。。。
4.配置了 resourcemanager 后 发现hue中 oozie 的任务显示的 jobTracker 显示的还是 hadoop003:8032

这里应该显示的应该是 ResourceManager 的 yarn-ha

这里是修改后需要重新配置启动

新跑的任务的时候。oozie 的配置项里面就会显示 jobTracker = yarn-ha

hadoop003 上面还有个 History Server 是spark 的一个实例,他只能在一个节点上添加一个服务,不能添加多个

现在停止了hadoop003上的 因为我要装在其他节点,而且这个只能装一个,所以只能先删除这一个