导读
针对爬取的北京市数据分析师岗位数据进行数据分析,如岗位分布的地区情况、工作经验要求、公司融资情况、学历要求及薪资水平。数据中存在着实习岗位,如果不想将其算在数据分析里可以将他们删除。
数据:
链接:https://pan.baidu.com/s/1dMTPlCLT0CcbOQFCHLv37Q
提取码:ct01
df.drop(df[df['职位名称'].str.contains('实习')].index, inplace=True) #剔除实习岗位 print(df.describe())
岗位分布地区情况
#北京市数据分析岗位分布柱形图 from pyecharts import Map df_drop = df["工作地点"].dropna() #去除空值 num_jobarea = Counter(df_drop) job_area = list(num_jobarea.keys()) # print(job_area) job_num = list(num_jobarea.values()) bar_job_area = Bar("北京市数据分析岗位分布",title_pos='40%') bar_job_area.add("",job_area,job_num,yaxis_name="公司数量",yaxis_name_gap=40,xaxis_rotate=30,is_label_show = True) bar_job_area.render('D:\\2\\1\\北京市数据分析岗位分布.html') #地图 map = Map("北京市数据分析岗位分布",title_pos='40%') map.add( "", job_area, job_num, maptype="北京", is_label_show=True,is_visualmap=True, visual_text_color="#000" ) map.render('D:\\2\\1\\北京市数据分析岗位分布地图.html')
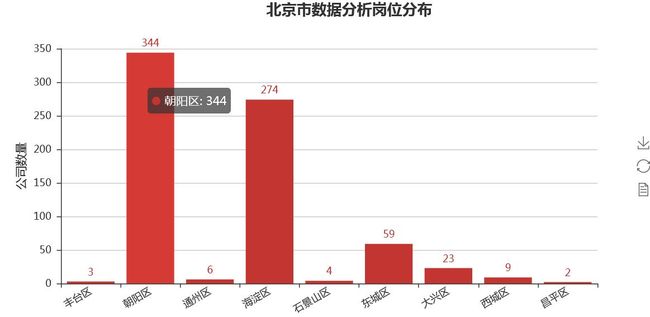
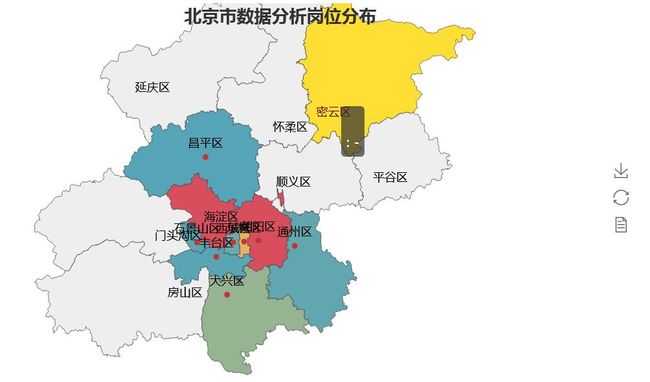
工作经验要求
#工作经验 from pyecharts import Funnel job_experience = Counter(df["工作经验"]) # print(job_experience) job_experience_attr = list(job_experience.keys()) job_experience_value = list(job_experience.values()) funnel = Funnel("工作经验要求",title_pos = "center") funnel.add( "", job_experience_attr, job_experience_value, is_label_show=True, label_pos="outside", legend_orient="vertical", legend_pos="left", # label_text_color="#fff", ) funnel.render('D:\\2\\1\\工作经验.html')

公司融资情况
#公司融资情况 from collections import Counter from pyecharts import Pie,Bar,Grid num_financeStage = Counter(df["融资阶段"]) finance_stage = list(num_financeStage.keys()) finance_num = list(num_financeStage.values()) bar_financeStage = Bar("融资阶段-柱状图",title_pos='20%') bar_financeStage.add("",finance_stage,finance_num,yaxis_name="公司数量",yaxis_name_gap=40,xaxis_rotate=30,is_label_show = True) pie_financeStage = Pie("融资阶段-饼状图",title_pos='55%') pie_financeStage.add("",finance_stage,finance_num,is_label_show = True, radius=[45, 65],center=[62, 50],legend_orient = "vertical",legend_pos = "85%") grid = Grid(width=1200) grid.add(bar_financeStage,grid_right="60%") grid.add(pie_financeStage,grid_left="60%") grid.render('D:\\2\\1\\公司融资情况.html')
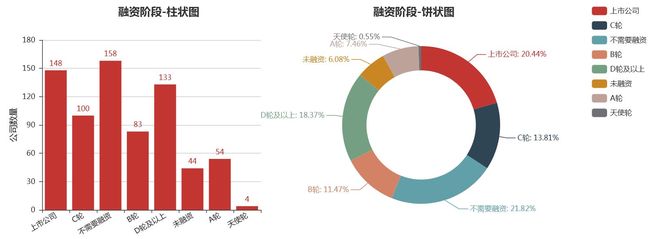
学历要求
#学历要求 job_education = Counter(df["学历要求"]) job_education_attr = list(job_education.keys()) job_education_value = list(job_education.values()) job_education_pie = Pie("数据分析岗位学历分布",title_pos = "center") job_education_pie.add("",job_education_attr,job_education_value,is_label_show = True,legend_orient = "vertical",legend_pos = "left") job_education_pie.render('D:\\2\\1\\学历要求.html')
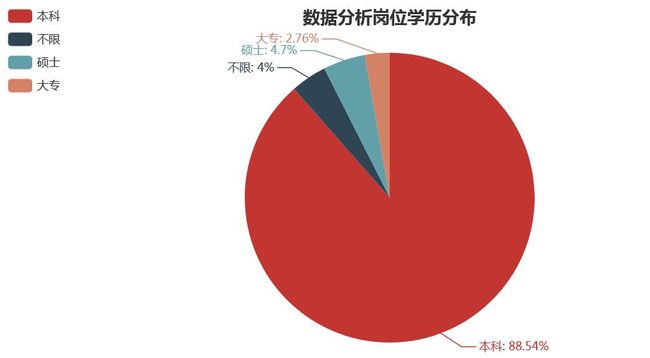
薪资水平
#工资水平 str_salary="".join(df['薪资']) str_salary_1=str_salary.replace("-","") list_salary=str_salary_1.lower().split('k')[0:-1] list_salary.reverse() list_salary_average = [] for i in range(int(len(list_salary)/2)): a = int(list_salary.pop()) b = int(list_salary.pop()) average = (a+b)/2 list_salary_average.append(average) #print(list_salary_average) num_10,num_10_15,num_15_20,num_25_down,num_25_up = 0,0,0,0,0 for i in list_salary_average: #print(i) if i < 10: num_10 += 1 elif i<15: num_10_15 += 1 elif i<20: num_15_20 +=1 elif i <25: num_25_down+=1 else: num_25_up+=1 list_end = [num_10,num_10_15,num_15_20,num_25_down,num_25_up] from pyecharts import Bar job_salary_message = ["小于10万","10万—15万","15万—20万","20万-25万","大于25万"] job_salary_number = list_end[:] bar_job_area = Bar("数据分析岗位工资分布",title_pos='40%') bar_job_area.add("",job_salary_message,job_salary_number,yaxis_name="公司数量",yaxis_name_gap=40,xaxis_rotate=30,is_label_show = True) bar_job_area.render('D:\\2\\1\\薪资水平.html')

还有一些数据可以进行分析,如前文提到的,也可以将福利待遇做词云图,分析更多的数据。O(∩_∩)O~