pandas 基础设置(pd.values) data_preprocessing(缺失值)
本文是在做毕业设计 预处理(缺失值)部分的实践 参考pandas官方文档df.values
#例子1
>>> df2 = pd.DataFrame([('parrot', 24.0, 'second'),
... ('lion', 80.5, 1),
... ('monkey', np.nan, None)],
... columns=('name', 'max_speed', 'rank'))
>>> df2.dtypes
name object
max_speed float64
rank object
dtype: object
>>> df2.values
array([['parrot', 24.0, 'second'],
['lion', 80.5, 1],
['monkey', nan, None]], dtype=object)
# 例子2
>>> df = pd.DataFrame({'age': [ 3, 29],
... 'height': [94, 170],
... 'weight': [31, 115]})
>>> df
age height weight
0 3 94 31
1 29 170 115
>>> df.dtypes
age int64
height int64
weight int64
dtype: object
>>> df.values
array([[ 3, 94, 31],
[ 29, 170, 115]], dtype=int64)
- 以上是官方文档的例子 下面进行测试验证
1.求max_val (min)

>>> list(df2.max(axis=0))
['parrot', 80.11]
# 找到了row对应的最大值
>>> list(df2.min(axis=0))
['lion', 24.0]
2.mean_values
求max + min / 2 的时候报错了 不知道为什么

>>> mean_val = list((df2.max(axis=0) + df2.min(axis=0)) / 2)
3. nan_value

发现原来 value是将其值做为一个array 舍弃 col raw 的 label (isnull()判断全局数据是否为null)

接下来命名一下 并加上list 取每一行的具体形式
>>> nan_values = df2.isnull().values
>>> list(nan_values)
[array([False, False, False]), array([False, False, False]), array([False, True, True])]
>>> list(nan_values[0])
[False, False, False]
>>> list(nan_values[1])
[False, False, False]
>>> list(nan_values[2])
[False, True, True]
>>>
4. row_num

df.values:显示的是二维矩阵 显示行数 len(list(df.values))
>>> list(df.values)
[array([ 3, 94, 31]), array([ 29, 170, 115])]
>>> len(list(df.values))
2
>>> df
age height weight
0 3 94 31
1 29 170 115
>>> df.values
array([[ 3, 94, 31],
[ 29, 170, 115]])
5. col_num

get col num: len(list(df.values[n]))
>>> df.values
array([[ 3, 94, 31],
[ 29, 170, 115]])
>>> list(df.values[1])
[29, 170, 115]
>>> len(list(df.values[1]))
3
delete concrete value

>>> df
age height weight
0 3 94 31
1 29 170 115
>>> label = ['age']
>>> df.drop(label,axis=1)
height weight
0 94 31
1 170 115
>>> df_lab = df[label]
>>> print(df_lab)
age
0 3
1 29
add the col label

发现drop的时候只是copy了输出 原值不会改变 需要赋予新的变量
>>> df
age height weight
0 3 94 31
1 29 170 115
>>> label = ['age','height']
>>> df.drop(label,axis=1)
weight
0 31
1 115
>>> df
age height weight
0 3 94 31
1 29 170 115
>>> df_temp = df.drop(label,axis=1)
>>> df_temp
weight
0 31
1 115
>>> df_lab = df[label]
>>> df_lab
age height
0 3 94
1 29 170
>>> print(df_lab)
age height
0 3 94
1 29 170
>>> df[label]
age height
0 3 94
1 29 170
>>> # 以上是删除的值
- 以下是添加对应的col label & value


- DataFrame.insert(loc, column, value, allow_duplicates=False)

>>> for index,lab in enumerate(label):
... df_temp.insert(index,lab,df_lab[lab])
...
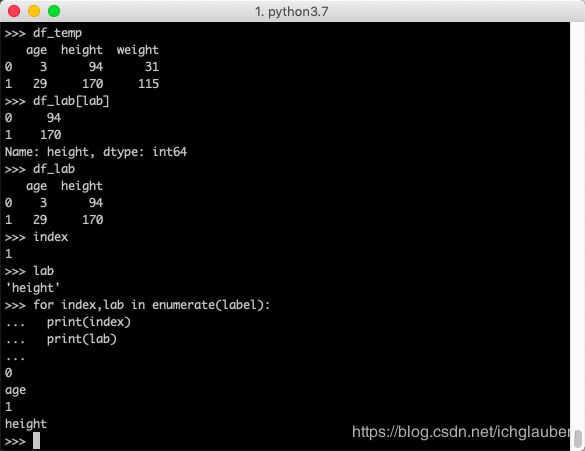
>>> df_temp
age height weight
0 3 94 31
1 29 170 115
>>> df_lab[lab]
0 94
1 170
Name: height, dtype: int64
>>> df_lab
age height
0 3 94
1 29 170
>>> for index,lab in enumerate(label):
... print(index , lab )
...
0 age
1 height
处理缺失值 需要以上的值
使用循环
for rn in range(row_num):
#data_values_r = list(data_values[rn])
nan_values_r = list(nan_values[rn])
for cn in range(col_num):#column number
if nan_values_r[cn] == False:
df_temp.values[rn][cn] = 2 * (df_temp.values[rn][cn] - mean_val[cn])/(max_val[cn] - min_val[cn])
else:
print ('Wrong')