《深入理解LINUX内核》学习笔记——内存管理
x86架构中的内存管理
x86架构中的内存管理使用两种方式,分段和分页。
如下图所示:
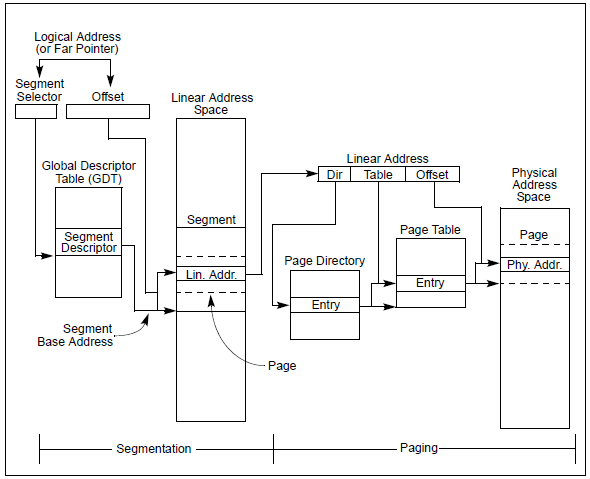
在x86架构中内存被分为三种形式,分别是逻辑地址(Logical Address),线性地址(Linear Address)和物理地址(Physical Address)。如上图所示,通过分段可以将逻辑地址转换为线性地址,而通过分页可以将线性地址转换为物理地址。
逻辑地址由两部分构成,一部分是段选择器(Segment Selector),一部分是偏移(Offset)。
段选择符存放在段寄存器中,如CS(存放代码段选择符)、SS(存放堆栈段选择符)、DS(存放数据段选择符)和ES、FS、GS(一般也用来存放数据段选择符)等;偏移与对应段描述符(由段选择符决定)中的基地址相加就是线性地址。
全局描述符表(Global Descriptor Table)需要OS在初始化时创建(每个CPU都有一张,基本内容大致相同,除了少数几项如TSS),创建好后将表的地址(这是个线性地址)放到全局描述符寄存器中(GDTR),这通过LGDT和SGDT指令来完成。上图只展示了全局描述符表,其实还有一种局部描述符表(Local Descriptor Table),结构与全局描述符表一致,当进程需要使用除了放在全局描述符表中的段之外的段时,就需要自己创建局部描述符表,这个用的不多,先不关注。
OS需要做的就是创建全局描述符表和提供逻辑地址,之后的分段操作x86的CPU会自动完成,并找到对应的线性地址。
对于全局描述符表中的段描述符表(Segment Descriptor)后面会详细介绍。
从线性地址到物理地址的转换也是CPU自动完成的,不过转化时使用的表(就是上图中的Page Directory和Page Table等(很多时候不只两张))也需要OS提供,对于表的创建后续也会详细介绍。
有几点需要注意:
1. 在x86架构中,分段是强制的,并不能关闭,而分页是可选的;
2. 以上是保护模式下的内存管理,在实模式下并不是这样;
3. 上述的内存管理机制通常在OS下实现,BIOS/UEFI下也不会使用(当前的UEFI应该是没有使用分页,待确定,不过可以确定的是UEFI下是可以直接访问物理地址的);
分段
对于分段来说,首先需要了解的是保存在段寄存器中的段选择符的意义,这样OS才知道要往里面放什么样的值。
段选择符是16位的值,如下所示:
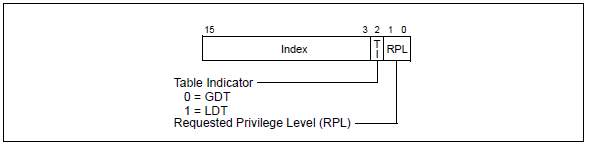
Index:表示的是在描述符表中的偏移,由于一个描述符的大小是8个字节,所以实际的位置是8 * Index在加上基地址,Index的大小是13位,所以最多可以寻址8K个描述符;
TI:全称是Table Indicator,它用来指示这张表到底是全局描述符表(0)还是局部描述符表(1);
RPL:全称是Requested Privilege Level,请求特权级,它是一种用来保护程序的机制,为了了解它就需要知道CPU的特权级(x86架构中使用了Ring的概念)。
下图表现了x86架构中CPU使用的特权级:
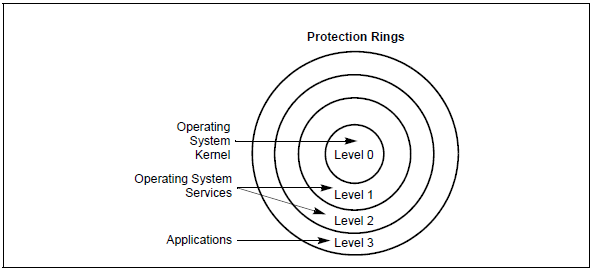
x86架构中的CPU存在4层特权级,分别是0-3(这也与RPL由两个BIT表示相对应),越靠近圆心,数字越小,特权级越高。
需要说明下,Linux只使用了Ring0和Ring3,分别对应内核态和用户态。
CPU会进行特权级别的检测,如果出现错误就触发General-Protection异常(#GP)。
为了进行检测,CPU会识别下面三种类型的特权级:
CPL:Current Privilege Level,它表示的是执行当前进程的CPU的特权级,它存放在CS和SS寄存器的BIT0和BIT1位置(实际就是RPL的位置,只不过名字不一样);
DPL:Descriptor Privilege Level,它位于段描述符中,用来表示该段的特权级别,如果当前执行的代码需要访问该段,DPL就会与CPL和RPL进行比较确定是否可访问,由于段描述符用于不同类型的段,对于每一种段类型,具体的比较方式不同,这里不做特别介绍了,可以参考Intel开发者手册。
RPL:前面已经提到一些,但是与CPL的关系似乎比较微妙。CPU检查是否可以访问一个段的时候,会一同检查RPL和CPL,它们中值较大(特权级较小)的那一个决定有效特权级。从前面的话中似乎也看不出来RPL的作用,RPL其实主要用于用户态的程序需要调用内核态的代码的时候,用户态传递给内核态的数据段的RPL应该是用户态自己的RPL(即3),这样即使用户态代码想通过调用内核态代码来访问内核态相关的数据也会因为特权级别不足而失败,如下图所示:
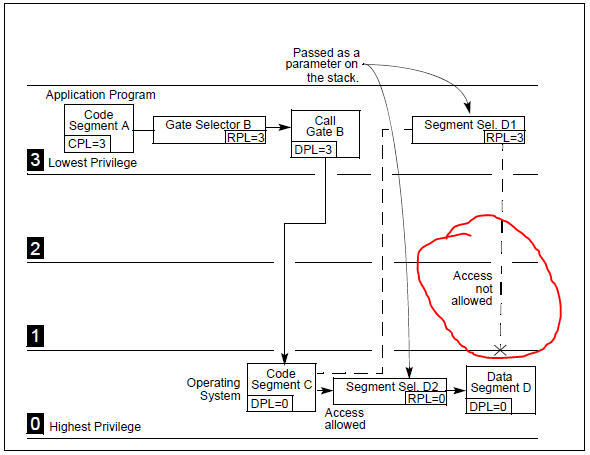
RPL一般用于数据段选择符(DS、ES、FS、GS),而对应CS和SS相应的位置是CPL。
在书中并没有特别介绍RPL,以上关于RPL的内容只是自己的理解。
段选择符最终的目的是指向段描述符,如图所示:
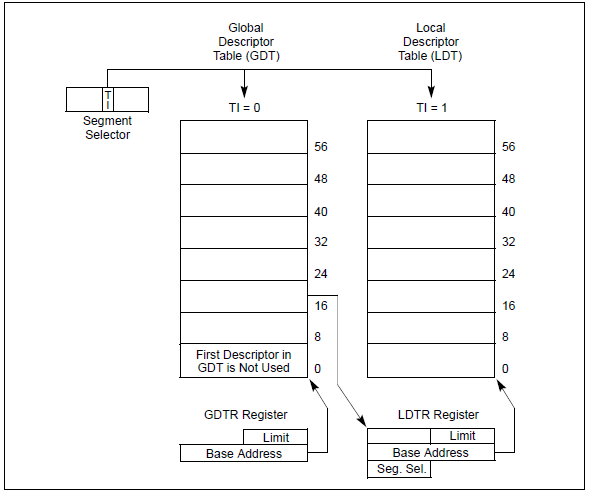
下面的主要内容就是介绍段描述符。
段描述符的结构如下所示:
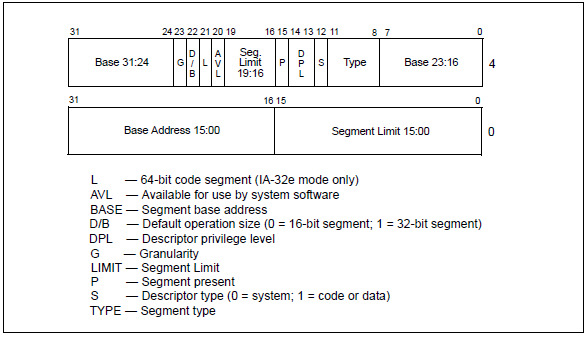
Base [Address]:表示段的线性地址,是个32位的值;
Segment Limit:表示段的长度(并不是真正的段大小),是个20位的值;
G:表示的是段的粒度,0表示1字节,1表示4K字节,它与Segment Limit相乘才是一个段的真正大小。
根据不同的值大致可以分为三种类型:
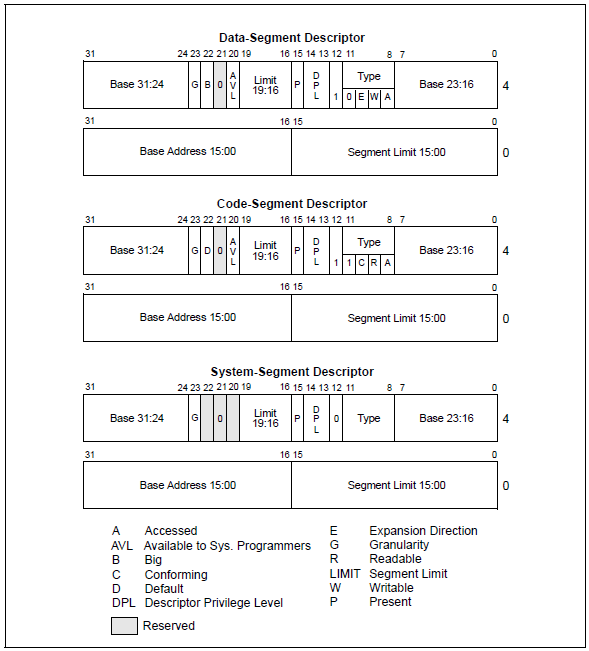
关于具体每一个位的意义不做介绍了,可以参考Intel开发者手册。
Linux下对分段的支持比较简单,事实上相对于分段,Linux更喜欢用分页。毕竟Linux需要支持不同的CPU架构,而其它CPU的分段的支持可能并不一样。
Linux中创建的全局描述符表如下所示:
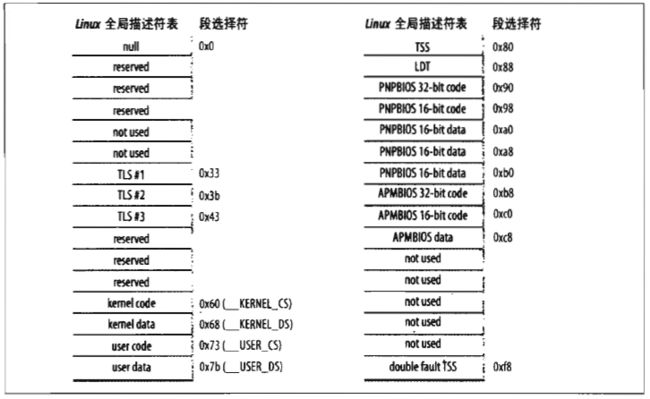
其中的内核态代码段数据段和用户态代码段数据段都设置成了比较简单的形式:

从上表可以看出,无论是内核态还是用户态,所有进程都可以访问相同的逻辑地址,且这个逻辑地址是与线性地址一致的(逻辑地址的偏移量字段和相应的线性地址的值相同)。
在include\asm-i386\Segment.h文件中定义了几个宏,它们指向了上图的全局描述符表和上表中的段描述符:
/*
* The layout of the per-CPU GDT under Linux:
*
* 0 - null
* 1 - reserved
* 2 - reserved
* 3 - reserved
*
* 4 - unused <==== new cacheline
* 5 - unused
*
* ------- start of TLS (Thread-Local Storage) segments:
*
* 6 - TLS segment #1 [ glibc's TLS segment ]
* 7 - TLS segment #2 [ Wine's %fs Win32 segment ]
* 8 - TLS segment #3
* 9 - reserved
* 10 - reserved
* 11 - reserved
*
* ------- start of kernel segments:
*
* 12 - kernel code segment <==== new cacheline
* 13 - kernel data segment
* 14 - default user CS
* 15 - default user DS
* 16 - TSS
* 17 - LDT
* 18 - PNPBIOS support (16->32 gate)
* 19 - PNPBIOS support
* 20 - PNPBIOS support
* 21 - PNPBIOS support
* 22 - PNPBIOS support
* 23 - APM BIOS support
* 24 - APM BIOS support
* 25 - APM BIOS support
*
* 26 - unused
* 27 - unused
* 28 - unused
* 29 - unused
* 30 - unused
* 31 - TSS for double fault handler
*/
#define GDT_ENTRY_TLS_ENTRIES 3
#define GDT_ENTRY_TLS_MIN 6
#define GDT_ENTRY_TLS_MAX (GDT_ENTRY_TLS_MIN + GDT_ENTRY_TLS_ENTRIES - 1)
#define TLS_SIZE (GDT_ENTRY_TLS_ENTRIES * 8)
#define GDT_ENTRY_DEFAULT_USER_CS 14
#define __USER_CS (GDT_ENTRY_DEFAULT_USER_CS * 8 + 3)
#define GDT_ENTRY_DEFAULT_USER_DS 15
#define __USER_DS (GDT_ENTRY_DEFAULT_USER_DS * 8 + 3)
#define GDT_ENTRY_KERNEL_BASE 12
#define GDT_ENTRY_KERNEL_CS (GDT_ENTRY_KERNEL_BASE + 0)
#define __KERNEL_CS (GDT_ENTRY_KERNEL_CS * 8)
#define GDT_ENTRY_KERNEL_DS (GDT_ENTRY_KERNEL_BASE + 1)
#define __KERNEL_DS (GDT_ENTRY_KERNEL_DS * 8)
#define GDT_ENTRY_TSS (GDT_ENTRY_KERNEL_BASE + 4)
#define GDT_ENTRY_LDT (GDT_ENTRY_KERNEL_BASE + 5)
#define GDT_ENTRY_PNPBIOS_BASE (GDT_ENTRY_KERNEL_BASE + 6)
#define GDT_ENTRY_APMBIOS_BASE (GDT_ENTRY_KERNEL_BASE + 11)
#define GDT_ENTRY_DOUBLEFAULT_TSS 31
/*
* The GDT has 32 entries
*/
#define GDT_ENTRIES 32
#define GDT_SIZE (GDT_ENTRIES * 8)
/* Simple and small GDT entries for booting only */
#define GDT_ENTRY_BOOT_CS 2
#define __BOOT_CS (GDT_ENTRY_BOOT_CS * 8)
#define GDT_ENTRY_BOOT_DS (GDT_ENTRY_BOOT_CS + 1)
#define __BOOT_DS (GDT_ENTRY_BOOT_DS * 8)
/*
* The interrupt descriptor table has room for 256 idt's,
* the global descriptor table is dependent on the number
* of tasks we can have..
*/
#define IDT_ENTRIES 256
具体怎么使用的还不知道,以后用到了再补充。
分页
前面已经提到,分页的作用是将线性地址转换为物理地址,其实它还有一个附加的作用,即确定这段线性地址的访问权限和Cache类型。
注意,线性地址的转换并不是按照地址来对应的,而是按照页来对应的,即一个页内的连续的线性地址对应一个页的连续的物理地址。
页是一个术语,表示的是一段连续的固定长度(长度可以是4K、2M、4M等值)的线性地址,有时也表示其中的数据。表示物理地址的“页”称为页框。
一个页与一个页框对应且等长。
从线性地址到物理地址的转换时通过一种称为“页表”的数据结构来完成的。
由于分页是可选的,所以默认是关闭的,需要手动开启,而在开启之前OS必须确保页表已经初始化完成,且它的起始物理地址已经放到了CR3寄存器中。
Intel的CPU有三种类型的分页模式,如下图所示:
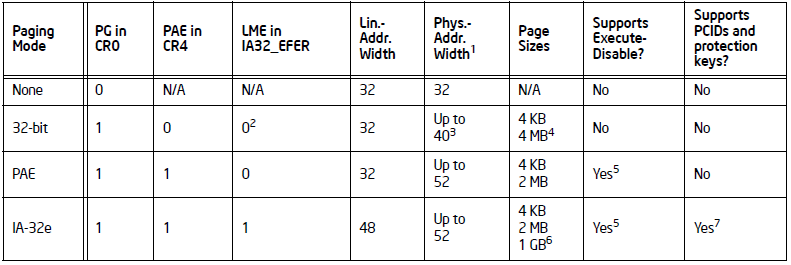
有上图可以看到,通过CR0.PG,CR4.PAE和IA32_EFER.LME来确定使用的到底是哪一种分页模式。
软件上可以通过mov指令往CR0和CR4里面写值,并通过MSR读写往IA32_EFER写值,来设置分页模式。
下面是几种分页模式之间的转换:
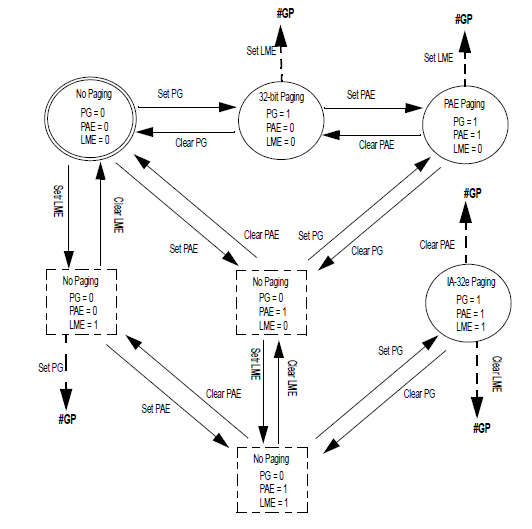
当然CPU并不一定支持所有的这三种模式,为了确定支持情况,需要通过CPUID来进行判断,具体参考Intel开发者手册。
前面已经提到分页靠的是页表,而CPU支持三种不同的分页模式,因此使用的页表也不一样,下图描述了所有可能的页表类型:
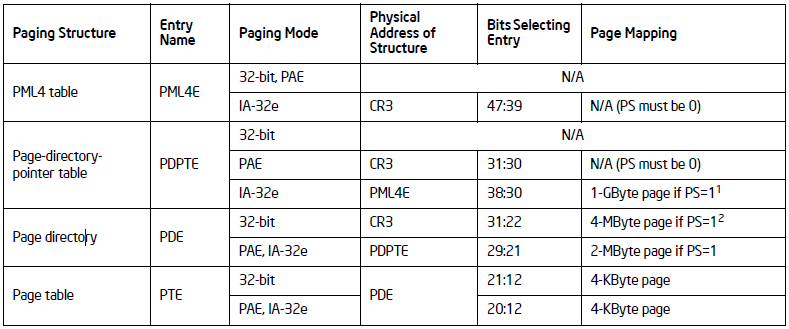
从上图可以看到IA-32e模式使用了所有的4中页表,而PAE使用了三种页表,32-bit使用了两种页表。
下面对最简单的32-bit分页模式做一个介绍,如下图:
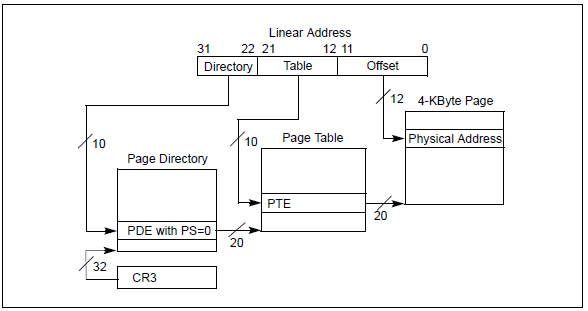
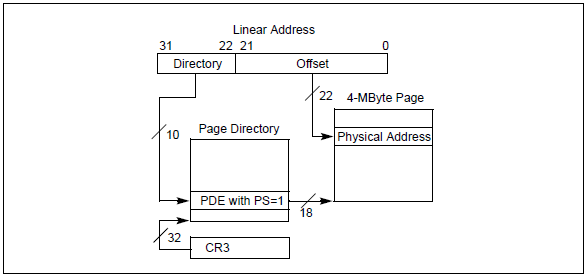
可以看到32-bit分页也有两种形式,最主要的差别就在于页的大小。
关于页表中的每一项,对于Page Director和Page Table大致相同,不过也有一些小差别,下图累出了CR3和页表项的结构:
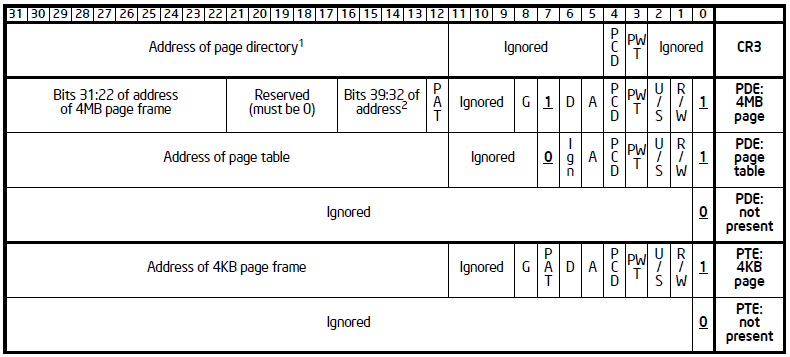
关于每一个BIT的具体意义参考Intel开发者手册,本节开头提到的分页可以通过确定访问权限和Cache类型的,就是由这里的某些位确定的。
需要注意,对于64位的系统CR3是64位的,不过高32位在32-bit分页中会被忽略。
Linux中对Intel的CPU的采用的分页模型同时适用于32位系统和64位系统,如下图所示:

由于要支持64位的,所以需要所有4张表:
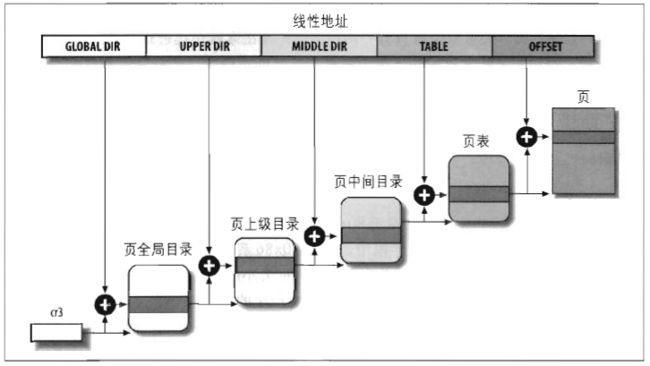
由于最后的offset是12位的,所以支持的页大小是4K的。
如果是32位的系统,则页上级目录和也中间目录为全0。
在Linux中,每一个进程都有自己的页表,当发生进程切换时,Linux会把CR3中的内容保存在前一个执行进程的描述符中,然后把下一个要执行的进程分页使用的页表地址(物理地址)放入到CR3中,这样当新进程执行的时候CPU就能够指向正确的页表。
to be continued...