ElasticSearch基本操作(二)
目录
2.1倒排索引
2.1.2 倒排索引原理
2.1.3 分词器介绍及内置分词器
2.2使用ElasticSearch API 实现CRUD
2.3批量获取文档
2.4使用Bulk API 实现批量操作
2.5版本控制
2.6 什么是Mapping
2.7基本查询(Query查询)
2.1倒排索引
Elasticsearch 使用一种称为 倒排索引 的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
示例:
(1):假设文档集合包含五个文档,每个文档内容如图所示,在图中最左端一栏是每个文档对应的文档编号。我们的任务就是对这个文档集合建立倒排索引。
(2):中文和英文等语言不同,单词之间没有明确分隔符号,所以首先要用分词系统将文档自动切分成单词序列。这样每个文档就转换为由单词序列构成的数据流,为了系统后续处理方便,需要对每个不同的单词赋予唯一的单词编号,同时记录下哪些文档包含这个单词,在如此处理结束后,我们可以得到最简单的倒排索引
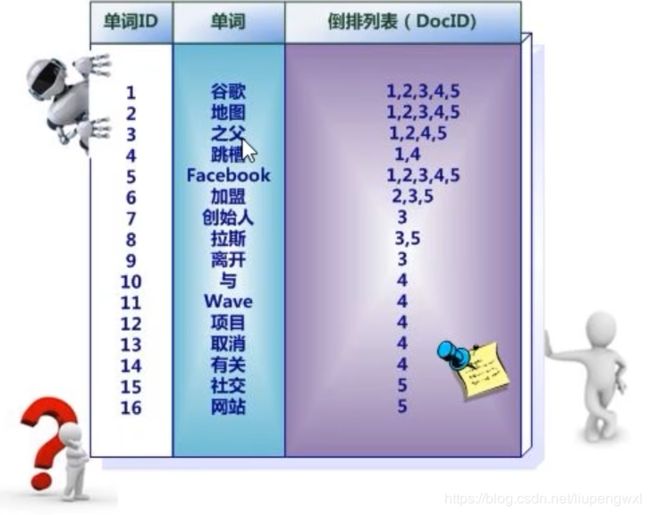
“单词ID”一栏记录了每个单词的单词编号,第二栏是对应的单词,第三栏即每个单词对应的倒排列表
(3):索引系统还可以记录除此之外的更多信息,下图还记载了单词频率信息(TF)即这个单词在某个文档中的出现次数,之所以要记录这个信息,是因为词频信息在搜索结果排序时,计算查询和文档相似度是很重要的一个计算因子,所以将其记录在倒排列表中,以方便后续排序时进行分值计算。
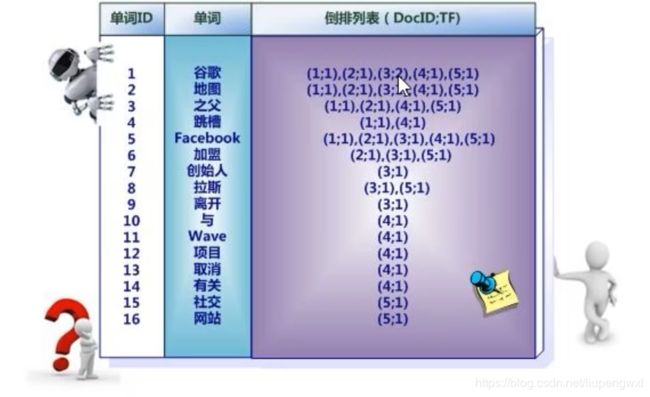
(4):倒排列表中还可以记录单词在某个文档出现的位置信息
(1,<11>,1),(2,<7>,1),(3,<3,9>,2)
有了这个索引系统,搜索引擎可以很方便地响应用户的查询,比如用户输入查询词“Facebook”,搜索系统查找倒排索引,从中可以读出包含这个单词的文档,这些文档就是提供给用户的搜索结果,而利用单词频率信息、文档频率信息即可以对这些候选搜索结果进行排序,计算文档和查询的相似性,按照相似性得分由高到低排序输出,此即为搜索系统的部分内部流程。
2.1.2 倒排索引原理
1.The quick brown fox jumped over the lazy dog
2.Quick brown foxes leap over lazy dogs in summer
倒排索引:
Term Doc_1 Doc_2
-------------------------
Quick | | X
The | X |
brown | X | X
dog | X |
dogs | | X
fox | X |
foxes | | X
in | | X
jumped | X |
lazy | X | X
leap | | X
over | X | X
quick | X |
summer | | X
the | X |
搜索quick brown :
Term Doc_1 Doc_2
-------------------------
brown | X | X
quick | X |
------------------------
Total | 2 | 1
计算相关度分数时,文档1的匹配度高,分数会比文档2高
问题:
Quick 和 quick 以独立的词条出现,然而用户可能认为它们是相同的词。
fox 和 foxes 非常相似, 就像 dog 和 dogs ;他们有相同的词根。
jumped 和 leap, 尽管没有相同的词根,但他们的意思很相近。他们是同义词。
搜索含有 Quick fox的文档是搜索不到的
使用标准化规则(normalization):
建立倒排索引的时候,会对拆分出的各个单词进行相应的处理,以提升后面搜索的时候能够搜索到相关联的文档的概率
Term Doc_1 Doc_2
-------------------------
brown | X | X
dog | X | X
fox | X | X
in | | X
jump | X | X
lazy | X | X
over | X | X
quick | X | X
summer | | X
the | X | X
2.1.3 分词器介绍及内置分词器
分词器:从一串文本中切分出一个一个的词条,并对每个词条进行标准化
包括三部分:
character filter:分词之前的预处理,过滤掉HTML标签,特殊符号转换等
tokenizer:分词
token filter:标准化
内置分词器:
standard 分词器:(默认的)他会将词汇单元转换成小写形式,并去除停用词和标点符号,支持中文采用的方法为单字切分
simple 分词器:首先会通过非字母字符来分割文本信息,然后将词汇单元统一为小写形式。该分析器会去掉数字类型的字符。
Whitespace 分词器:仅仅是去除空格,对字符没有lowcase化,不支持中文;
并且不对生成的词汇单元进行其他的标准化处理。
language 分词器:特定语言的分词器,不支持中文
2.2使用ElasticSearch API 实现CRUD
添加索引:

PUT lib
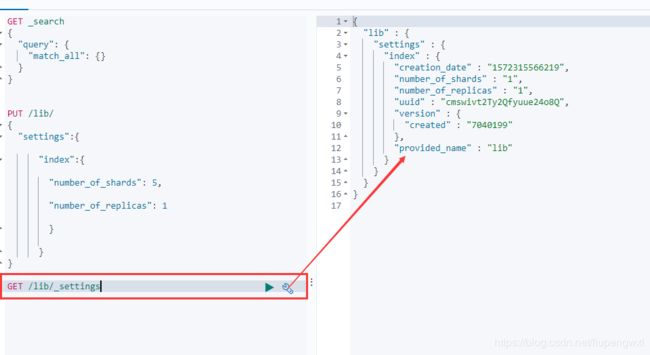
查看索引信息:
GET /lib/_settings
GET _all/_settings
添加文档:
PUT /lib/user/1
{
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 32,
"about" : "I like to collect rock albums",
"interests": [ "music" ]
}
POST /lib/user/
{
"first_name" : "Douglas",
"last_name" : "Fir",
"age" : 23,
"about": "I like to build cabinets",
"interests": [ "forestry" ]
}
查看文档:
GET /lib/user/1
GET /lib/user/
GET /lib/user/1?_source=age,interests
更新文档:可以覆盖更新,也可以直接修改某个字段
PUT /lib/user/1
{
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 36,
"about" : "I like to collect rock albums",
"interests": [ "music" ]
}
POST /lib/user/1/_update
{
"doc":{
"age":33
}
}
删除一个文档
DELETE /lib/user/1
删除一个索引
DELETE /lib
2.3批量获取文档
使用es提供的Multi Get API:
使用Multi Get API可以通过索引名、类型名、文档id一次得到一个文档集合,文档可以来自同一个索引库,也可以来自不同索引库
使用curl命令:
curl 'http://192.168.25.131:9200/_mget' -d '{
"docs":[
{
"_index": "lib",
"_type": "user",
"_id": 1
},
{
"_index": "lib",
"_type": "user",
"_id": 2
}
]
}'
在客户端工具中:
GET /_mget
{
"docs":[
{
"_index": "lib",
"_type": "user",
"_id": 1
},
{
"_index": "lib",
"_type": "user",
"_id": 2
},
{
"_index": "lib",
"_type": "user",
"_id": 3
}
]
}
可以指定具体的字段:
GET /_mget
{
"docs":[
{
"_index": "lib",
"_type": "user",
"_id": 1,
"_source": "interests"
},
{
"_index": "lib",
"_type": "user",
"_id": 2,
"_source": ["age","interests"]
}
]
}
获取同索引同类型下的不同文档:
GET /lib/user/_mget
{
"docs":[
{
"_id": 1
},
{
"_type": "user",
"_id": 2,
}
]
}
GET /lib/user/_mget
{
"ids": ["1","2"]
}
2.4使用Bulk API 实现批量操作
bulk的格式:
{action:{metadata}}\n
{requstbody}\n
action:(行为)
create:文档不存在时创建
update:更新文档
index:创建新文档或替换已有文档
delete:删除一个文档
metadata:_index,_type,_id
create 和index的区别
如果数据存在,使用create操作失败,会提示文档已经存在,使用index则可以成功执行。
示例:
{"delete":{"_index":"lib","_type":"user","_id":"1"}}
批量添加:
POST /lib2/books/_bulk
{"index":{"_id":1}}
{"title":"Java","price":55}
{"index":{"_id":2}}
{"title":"Html5","price":45}
{"index":{"_id":3}}
{"title":"Php","price":35}
{"index":{"_id":4}}
{"title":"Python","price":50}
批量获取:
GET /lib2/books/_mget
{
"ids": ["1","2","3","4"]
}
删除:没有请求体
POST /lib2/books/_bulk
{"delete":{"_index":"lib2","_type":"books","_id":4}}
{"create":{"_index":"tt","_type":"ttt","_id":"100"}}
{"name":"lisi"}
{"index":{"_index":"tt","_type":"ttt"}}
{"name":"zhaosi"}
{"update":{"_index":"lib2","_type":"books","_id":"4"}}
{"doc":{"price":58}}
bulk一次最大处理多少数据量:
bulk会把将要处理的数据载入内存中,所以数据量是有限制的,最佳的数据量不是一个确定的数值,它取决于你的硬件,你的文档大小以及复杂性,你的索引以及搜索的负载。
一般建议是1000-5000个文档,大小建议是5-15MB,默认不能超过100M,可以在es的配置文件(即$ES_HOME下的config下的elasticsearch.yml)中。
2.5版本控制
ElasticSearch采用了乐观锁来保证数据的一致性,也就是说,当用户对document进行操作时,并不需要对该document作加锁和解锁的操作,只需要指定要操作的版本即可。当版本号一致时,ElasticSearch会允许该操作顺利执行,而当版本号存在冲突时,ElasticSearch会提示冲突并抛出异常(VersionConflictEngineException异常)。
ElasticSearch的版本号的取值范围为1到2^63-1。
内部版本控制:使用的是_version
外部版本控制:elasticsearch在处理外部版本号时会与对内部版本号的处理有些不同。它不再是检查_version是否与请求中指定的数值_相同_,而是检查当前的_version是否比指定的数值小。如果请求成功,那么外部的版本号就会被存储到文档中的_version中。
为了保持_version与外部版本控制的数据一致
使用version_type=external
2.6 什么是Mapping
PUT /myindex/article/1
{
"post_date": "2018-05-10",
"title": "Java",
"content": "java is the best language",
"author_id": 119
}
PUT /myindex/article/2
{
"post_date": "2018-05-12",
"title": "html",
"content": "I like html",
"author_id": 120
}
PUT /myindex/article/3
{
"post_date": "2018-05-16",
"title": "es",
"content": "Es is distributed document store",
"author_id": 110
}
GET /myindex/article/_search?q=2018-05
GET /myindex/article/_search?q=2018-05-10
GET /myindex/article/_search?q=html
GET /myindex/article/_search?q=java
#查看es自动创建的mapping
GET /myindex/article/_mapping
es自动创建了index,type,以及type对应的mapping(dynamic mapping)
什么是映射:mapping定义了type中的每个字段的数据类型以及这些字段如何分词等相关属性
{
"myindex": {
"mappings": {
"article": {
"properties": {
"author_id": {
"type": "long"
},
"content": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"post_date": {
"type": "date"
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
}
创建索引的时候,可以预先定义字段的类型以及相关属性,这样就能够把日期字段处理成日期,把数字字段处理成数字,把字符串字段处理字符串值等
支持的数据类型:
(1)核心数据类型(Core datatypes)
字符型:string,string类型包括
text 和 keyword
text类型被用来索引长文本,在建立索引前会将这些文本进行分词,转化为词的组合,建立索引。允许es来检索这些词语。text类型不能用来排序和聚合。
Keyword类型不需要进行分词,可以被用来检索过滤、排序和聚合。keyword 类型字段只能用本身来进行检索
数字型:long, integer, short, byte, double, float
日期型:date
布尔型:boolean
二进制型:binary
(2)复杂数据类型(Complex datatypes)
数组类型(Array datatype):数组类型不需要专门指定数组元素的type,例如:
字符型数组: [ "one", "two" ]
整型数组:[ 1, 2 ]
数组型数组:[ 1, [ 2, 3 ]] 等价于[ 1, 2, 3 ]
对象数组:[ { "name": "Mary", "age": 12 }, { "name": "John", "age": 10 }]
对象类型(Object datatype):_ object _ 用于单个JSON对象;
嵌套类型(Nested datatype):_ nested _ 用于JSON数组;
(3)地理位置类型(Geo datatypes)
地理坐标类型(Geo-point datatype):_ geo_point _ 用于经纬度坐标;
地理形状类型(Geo-Shape datatype):_ geo_shape _ 用于类似于多边形的复杂形状;
(4)特定类型(Specialised datatypes)
IPv4 类型(IPv4 datatype):_ ip _ 用于IPv4 地址;
Completion 类型(Completion datatype):_ completion _提供自动补全建议;
Token count 类型(Token count datatype):_ token_count _ 用于统计做了标记的字段的index数目,该值会一直增加,不会因为过滤条件而减少。
mapper-murmur3
类型:通过插件,可以通过 _ murmur3 _ 来计算 index 的 hash 值;
附加类型(Attachment datatype):采用 mapper-attachments
插件,可支持_ attachments _ 索引,例如 Microsoft Office 格式,Open Document 格式,ePub, HTML 等。
支持的属性:
"store":false//是否单独设置此字段的是否存储而从_source字段中分离,默认是false,只能搜索,不能获取值
"index": true//分词,不分词是:false
,设置成false,字段将不会被索引
"analyzer":"ik"//指定分词器,默认分词器为standard analyzer
"boost":1.23//字段级别的分数加权,默认值是1.0
"doc_values":false//对not_analyzed字段,默认都是开启,分词字段不能使用,对排序和聚合能提升较大性能,节约内存
"fielddata":{"format":"disabled"}//针对分词字段,参与排序或聚合时能提高性能,不分词字段统一建议使用doc_value
"fields":{"raw":{"type":"string","index":"not_analyzed"}} //可以对一个字段提供多种索引模式,同一个字段的值,一个分词,一个不分词
"ignore_above":100 //超过100个字符的文本,将会被忽略,不被索引
"include_in_all":ture//设置是否此字段包含在_all字段中,默认是true,除非index设置成no选项
"index_options":"docs"//4个可选参数docs(索引文档号) ,freqs(文档号+词频),positions(文档号+词频+位置,通常用来距离查询),offsets(文档号+词频+位置+偏移量,通常被使用在高亮字段)分词字段默认是position,其他的默认是docs
"norms":{"enable":true,"loading":"lazy"}//分词字段默认配置,不分词字段:默认{"enable":false},存储长度因子和索引时boost,建议对需要参与评分字段使用 ,会额外增加内存消耗量
"null_value":"NULL"//设置一些缺失字段的初始化值,只有string可以使用,分词字段的null值也会被分词
"position_increament_gap":0//影响距离查询或近似查询,可以设置在多值字段的数据上火分词字段上,查询时可指定slop间隔,默认值是100
"search_analyzer":"ik"//设置搜索时的分词器,默认跟ananlyzer是一致的,比如index时用standard+ngram,搜索时用standard用来完成自动提示功能
"similarity":"BM25"//默认是TF/IDF算法,指定一个字段评分策略,仅仅对字符串型和分词类型有效
"term_vector":"no"//默认不存储向量信息,支持参数yes(term存储),with_positions(term+位置),with_offsets(term+偏移量),with_positions_offsets(term+位置+偏移量) 对快速高亮fast vector highlighter能提升性能,但开启又会加大索引体积,不适合大数据量用
映射的分类:
(1)动态映射:
当ES在文档中碰到一个以前没见过的字段时,它会利用动态映射来决定该字段的类型,并自动地对该字段添加映射。
可以通过dynamic设置来控制这一行为,它能够接受以下的选项:
true:默认值。动态添加字段
false:忽略新字段
strict:如果碰到陌生字段,抛出异常
dynamic设置可以适用在根对象上或者object类型的任意字段上。
POST /lib2
#给索引lib2创建映射类型
{
"settings":{
"number_of_shards" : 3,
"number_of_replicas" : 0
},
"mappings":{
"books":{
"properties":{
"title":{"type":"text"},
"name":{"type":"text","index":false},
"publish_date":{"type":"date","index":false},
"price":{"type":"double"},
"number":{"type":"integer"}
}
}
}
}
POST /lib2
#给索引lib2创建映射类型
{
"settings":{
"number_of_shards" : 3,
"number_of_replicas" : 0
},
"mappings":{
"books":{
"properties":{
"title":{"type":"text"},
"name":{"type":"text","index":false},
"publish_date":{"type":"date","index":false},
"price":{"type":"double"},
"number":{
"type":"object",
"dynamic":true
}
}
}
}
}
2.7基本查询(Query查询)
2.7.1数据准备
PUT /lib3
{
"settings":{
"number_of_shards" : 3,
"number_of_replicas" : 0
},
"mappings":{
"user":{
"properties":{
"name": {"type":"text"},
"address": {"type":"text"},
"age": {"type":"integer"},
"interests": {"type":"text"},
"birthday": {"type":"date"}
}
}
}
}
GET /lib3/user/_search?q=name:lisi
GET /lib3/user/_search?q=name:zhaoliu&sort=age:desc
2.7.2 term查询和terms查询
term query会去倒排索引中寻找确切的term,它并不知道分词器的存在。这种查询适合keyword 、numeric、date。
term:查询某个字段里含有某个关键词的文档
GET /lib3/user/_search/
{
"query": {
"term": {"interests": "changge"}
}
}
terms:查询某个字段里含有多个关键词的文档
GET /lib3/user/_search
{
"query":{
"terms":{
"interests": ["hejiu","changge"]
}
}
}
2.7.3 控制查询返回的数量
from:从哪一个文档开始
size:需要的个数
GET /lib3/user/_search
{
"from":0,
"size":2,
"query":{
"terms":{
"interests": ["hejiu","changge"]
}
}
}
2.7.4 返回版本号
GET /lib3/user/_search
{
"version":true,
"query":{
"terms":{
"interests": ["hejiu","changge"]
}
}
}
2.7.5 match查询
match query知道分词器的存在,会对filed进行分词操作,然后再查询
GET /lib3/user/_search
{
"query":{
"match":{
"name": "zhaoliu"
}
}
}
GET /lib3/user/_search
{
"query":{
"match":{
"age": 20
}
}
}
match_all:查询所有文档
GET /lib3/user/_search
{
"query": {
"match_all": {}
}
}
multi_match:可以指定多个字段
GET /lib3/user/_search
{
"query":{
"multi_match": {
"query": "lvyou",
"fields": ["interests","name"]
}
}
}
match_phrase:短语匹配查询
ElasticSearch引擎首先分析(analyze)查询字符串,从分析后的文本中构建短语查询,这意味着必须匹配短语中的所有分词,并且保证各个分词的相对位置不变:
GET lib3/user/_search
{
"query":{
"match_phrase":{
"interests": "duanlian,shuoxiangsheng"
}
}
}
2.7.6 指定返回的字段
GET /lib3/user/_search
{
"_source": ["address","name"],
"query": {
"match": {
"interests": "changge"
}
}
}
2.7.7控制加载的字段
GET /lib3/user/_search
{
"query": {
"match_all": {}
},
"_source": {
"includes": ["name","address"],
"excludes": ["age","birthday"]
}
}
使用通配符*
GET /lib3/user/_search
{
"_source": {
"includes": "addr*",
"excludes": ["name","bir*"]
},
"query": {
"match_all": {}
}
}
2.7.8 排序
使用sort实现排序:
desc:降序,asc升序
GET /lib3/user/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order":"asc"
}
}
]
}
GET /lib3/user/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order":"desc"
}
}
]
}
2.7.9 前缀匹配查询
GET /lib3/user/_search
{
"query": {
"match_phrase_prefix": {
"name": {
"query": "zhao"
}
}
}
}
2.7.10 范围查询
range:实现范围查询
参数:from,to,include_lower,include_upper,boost
include_lower:是否包含范围的左边界,默认是true
include_upper:是否包含范围的右边界,默认是true
GET /lib3/user/_search
{
"query": {
"range": {
"birthday": {
"from": "1990-10-10",
"to": "2018-05-01"
}
}
}
}
GET /lib3/user/_search
{
"query": {
"range": {
"age": {
"from": 20,
"to": 25,
"include_lower": true,
"include_upper": false
}
}
}
}
2.7.11 wildcard查询
允许使用通配符* 和 ?来进行查询
*代表0个或多个字符
?代表任意一个字符
GET /lib3/user/_search
{
"query": {
"wildcard": {
"name": "zhao*"
}
}
}
GET /lib3/user/_search
{
"query": {
"wildcard": {
"name": "li?i"
}
}
}
2.7.12 fuzzy实现模糊查询
value:查询的关键字
boost:查询的权值,默认值是1.0
min_similarity:设置匹配的最小相似度,默认值为0.5,对于字符串,取值为0-1(包括0和1);对于数值,取值可能大于1;对于日期型取值为1d,1m等,1d就代表1天
prefix_length:指明区分词项的共同前缀长度,默认是0
max_expansions:查询中的词项可以扩展的数目,默认可以无限大
GET /lib3/user/_search
{
"query": {
"fuzzy": {
"interests": "chagge"
}
}
}
GET /lib3/user/_search
{
"query": {
"fuzzy": {
"interests": {
"value": "chagge"
}
}
}
}
2.7.13 高亮搜索结果
GET /lib3/user/_search
{
"query":{
"match":{
"interests": "changge"
}
},
"highlight": {
"fields": {
"interests": {}
}
}
}
2.8 Filter查询
filter是不计算相关性的,同时可以cache。因此,filter速度要快于query。
POST /lib4/items/_bulk
{"index": {"_id": 1}}
{"price": 40,"itemID": "ID100123"}
{"index": {"_id": 2}}
{"price": 50,"itemID": "ID100124"}
{"index": {"_id": 3}}
{"price": 25,"itemID": "ID100124"}
{"index": {"_id": 4}}
{"price": 30,"itemID": "ID100125"}
{"index": {"_id": 5}}
{"price": null,"itemID": "ID100127"}
2.8.1 简单的过滤查询
GET /lib4/items/_search
{
"post_filter": {
"term": {
"price": 40
}
}
}
GET /lib4/items/_search
{
"post_filter": {
"terms": {
"price": [25,40]
}
}
}
GET /lib4/items/_search
{
"post_filter": {
"term": {
"itemID": "ID100123"
}
}
}
查看分词器分析的结果:
GET /lib4/_mapping
不希望商品id字段被分词,则重新创建映射
DELETE lib4
PUT /lib4
{
"mappings": {
"items": {
"properties": {
"itemID": {
"type": "text",
"index": false
}
}
}
}
}
2.8.2 bool过滤查询
可以实现组合过滤查询
格式:
{
"bool": {
"must": [],
"should": [],
"must_not": []
}
}
must:必须满足的条件---and
should:可以满足也可以不满足的条件--or
must_not:不需要满足的条件--not
GET /lib4/items/_search
{
"post_filter": {
"bool": {
"should": [
{"term": {"price":25}},
{"term": {"itemID": "id100123"}}
],
"must_not": {
"term":{"price": 30}
}
}
}
}
嵌套使用bool:
GET /lib4/items/_search
{
"post_filter": {
"bool": {
"should": [
{"term": {"itemID": "id100123"}},
{
"bool": {
"must": [
{"term": {"itemID": "id100124"}},
{"term": {"price": 40}}
]
}
}
]
}
}
}
2.8.3 范围过滤
gt: >
lt: <
gte: >=
lte: <=
GET /lib4/items/_search
{
"post_filter": {
"range": {
"price": {
"gt": 25,
"lt": 50
}
}
}
}
2.8.5 过滤非空
GET /lib4/items/_search
{
"query": {
"bool": {
"filter": {
"exists":{
"field":"price"
}
}
}
}
}
GET /lib4/items/_search
{
"query" : {
"constant_score" : {
"filter": {
"exists" : { "field" : "price" }
}
}
}
}
2.8.6 过滤器缓存
ElasticSearch提供了一种特殊的缓存,即过滤器缓存(filter cache),用来存储过滤器的结果,被缓存的过滤器并不需要消耗过多的内存(因为它们只存储了哪些文档能与过滤器相匹配的相关信息),而且可供后续所有与之相关的查询重复使用,从而极大地提高了查询性能。
注意:ElasticSearch并不是默认缓存所有过滤器,
以下过滤器默认不缓存:
numeric_range
script
geo_bbox
geo_distance
geo_distance_range
geo_polygon
geo_shape
and
or
not
exists,missing,range,term,terms默认是开启缓存的
开启方式:在filter查询语句后边加上
"_catch":true
2.9 聚合查询
(1)sum
GET /lib4/items/_search
{
"size":0,
"aggs": {
"price_of_sum": {
"sum": {
"field": "price"
}
}
}
}
(2)min
GET /lib4/items/_search
{
"size": 0,
"aggs": {
"price_of_min": {
"min": {
"field": "price"
}
}
}
}
(3)max
GET /lib4/items/_search
{
"size": 0,
"aggs": {
"price_of_max": {
"max": {
"field": "price"
}
}
}
}
(4)avg
GET /lib4/items/_search
{
"size":0,
"aggs": {
"price_of_avg": {
"avg": {
"field": "price"
}
}
}
}
(5)cardinality:求基数
GET /lib4/items/_search
{
"size":0,
"aggs": {
"price_of_cardi": {
"cardinality": {
"field": "price"
}
}
}
}
(6)terms:分组
GET /lib4/items/_search
{
"size":0,
"aggs": {
"price_group_by": {
"terms": {
"field": "price"
}
}
}
}
对那些有唱歌兴趣的用户按年龄分组
GET /lib3/user/_search
{
"query": {
"match": {
"interests": "changge"
}
},
"size": 0,
"aggs":{
"age_group_by":{
"terms": {
"field": "age",
"order": {
"avg_of_age": "desc"
}
},
"aggs": {
"avg_of_age": {
"avg": {
"field": "age"
}
}
}
}
}
}
2.10 复合查询
将多个基本查询组合成单一查询的查询
2.10.1 使用bool查询
接收以下参数:
must:
文档 必须匹配这些条件才能被包含进来。
must_not:
文档 必须不匹配这些条件才能被包含进来。
should:
如果满足这些语句中的任意语句,将增加 _score,否则,无任何影响。它们主要用于修正每个文档的相关性得分。
filter:
必须 匹配,但它以不评分、过滤模式来进行。这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档。
相关性得分是如何组合的。每一个子查询都独自地计算文档的相关性得分。一旦他们的得分被计算出来, bool 查询就将这些得分进行合并并且返回一个代表整个布尔操作的得分。
下面的查询用于查找 title 字段匹配 how to make millions 并且不被标识为 spam 的文档。那些被标识为 starred 或在2014之后的文档,将比另外那些文档拥有更高的排名。如果 _两者_ 都满足,那么它排名将更高:
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }},
{ "range": { "date": { "gte": "2014-01-01" }}}
]
}
}
如果没有 must 语句,那么至少需要能够匹配其中的一条 should 语句。但,如果存在至少一条 must 语句,则对 should 语句的匹配没有要求。
如果我们不想因为文档的时间而影响得分,可以用 filter 语句来重写前面的例子:
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }}
],
"filter": {
"range": { "date": { "gte": "2014-01-01" }}
}
}
}
通过将 range 查询移到 filter 语句中,我们将它转成不评分的查询,将不再影响文档的相关性排名。由于它现在是一个不评分的查询,可以使用各种对 filter 查询有效的优化手段来提升性能。
bool 查询本身也可以被用做不评分的查询。简单地将它放置到 filter 语句中并在内部构建布尔逻辑:
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }}
],
"filter": {
"bool": {
"must": [
{ "range": { "date": { "gte": "2014-01-01" }}},
{ "range": { "price": { "lte": 29.99 }}}
],
"must_not": [
{ "term": { "category": "ebooks" }}
]
}
}
}
}
2.10.2 constant_score查询
它将一个不变的常量评分应用于所有匹配的文档。它被经常用于你只需要执行一个 filter 而没有其它查询(例如,评分查询)的情况下。
{
"constant_score": {
"filter": {
"term": { "category": "ebooks" }
}
}
}
term 查询被放置在 constant_score 中,转成不评分的filter。这种方式可以用来取代只有 filter 语句的 bool 查询。