一.背景
随着技术部dubbo服务的使用,应用和机器数量急剧增长,程序配置也愈加繁杂:各种功能的开关、参数的配置、服务器的地址等等。同时,我们对程序配置的期望值也越来越高:配置修改后实时生效,灰度发布,分环境、分集群管理,完善的权限、审核机制等等。
在这样的大环境下,传统的通过配置文件、数据库等方式已经越来越无法满足我们对配置管理的需求。
动态配置中心的意义:随时对程序发号施令
于是我们要采用配置中心去处理上述问题。通过配置中心,我们可以方便地管理微服务在不同环境中的配置,从而可以在运行时动态调整服务行为,真正实现配置即『控制』的目标。
1.一系列的背景,我们需要动态配置。
2.动态配置需要治理。
静态配置VS动态配置中心:
静态配置只能在项目重启的时候配置,没有实时性,同时增加了运维成本,同时增加可用性风险。
动态配置不用重启项目,实时配置生效,没有运维成本,可用性不受影响。
数据库配置VS动态配置中心
数据库配置造成数据库访问很高,数据库挂了就不可用,新增属性要开发页面数据库等不灵活,没有灰度,历史版本管理,分类管理等。
动态配置在数据库,本地硬盘,内存都保存,保证了可用性。属性改变了才会访问数据库,数据库的访问量不高。提供配置后即生效,不需要额外的开发。
提供灰度,历史版本,分类管理等功能。
二.apollo介绍:
1.基础模型:
Apollo 的基础模型:
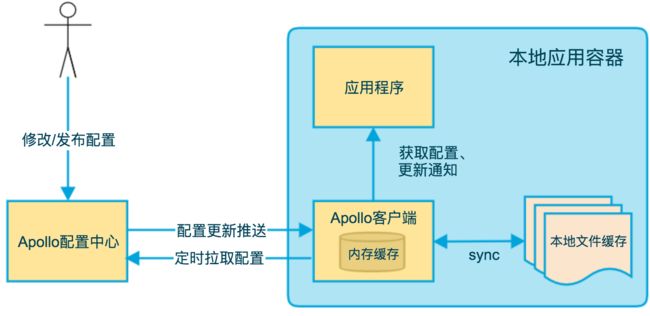
用户在配置中心对配置进行修改并发布
配置中心通知 Apollo 客户端有配置更新
-
Apollo 客户端从配置中心拉取最新的配置、更新本地配置并通知到应用
[图片上传失败...(image-15d0c-1556444319516)]
2.治理能力
1)统一管理不同环境、不同集群的配置。
2)支持灰度发布。
3)支持已发布的配置回滚。
4)完善的权限管理、操作审计日志。
Apollo 配置中心的管理界面如下图所示。
3.可用性
配置中心控制了整个微服务的运行时的行为,这样它的可用性就要求很高。
1)客户端高可用:
客户端和服务端保持了一个长连接,从而能第一时间获得apollo服务端配置更新的推送。
-
客户端还会定时从 Apollo 配置中心服务端拉取应用的最新配置;
这是一个 fallback 机制(补偿机制),为了防止推送机制失效导致配置不更新;
客户端定时拉取会上报本地版本,所以一般情况下(配置没有变化),对于定时拉取的操作,服务端都会返回 304 - Not Modified。
客户端从 Apollo 配置中心服务端获取到应用的最新配置后,会保存在内存中,所以我们的应用程序来获取配置的时候其实始终是从内存中获取的;
-
客户端还会把从服务端获取到的配置在本地文件系统缓存一份;
这主要是为了容灾,假设应用程序重启的时候,恰好远端服务全挂了,或者网络有故障,应用程序依然能从本地恢复配置。
通过这种推拉结合的机制,以及内存和本地文件双缓存的方式,有效地保证了客户端的可用性。
2)服务端高可用:
首先最下面是一个 DB,我们的配置是放在 DB 里的,然后在 DB 之上有两个服务:Config Service 和 Admin Service;
Config Service 提供配置的读取、推送等功能,服务对象是 Apollo 客户端;
Admin Service 提供配置的修改、发布等功能,服务对象是 Apollo Portal(管理界面);
Config Service 和 Admin Service 都是多实例、无状态部署,所以需要将自己注册到 Eureka 中并保持心跳;
在 Eureka 之上我们架了一层 Meta Server 用于封装 Eureka 的服务发现接口,主要是为了让客户端和 Eureka 解耦;
Client 通过域名访问 Meta Server 获取 Config Service 服务列表(IP+Port),而后直接通过 IP+Port 访问服务,同时在 Client 侧会做 load balance、错误重试;
Portal 通过域名访问 Meta Server 获取 Admin Service 服务列表(IP+Port),而后直接通过 IP+Port 访问服务,同时在 Portal 侧会做 load balance、错误重试;
为了简化部署,我们实际上会把 Config Service、Eureka 和 Meta Server 三个逻辑角色部署在同一个 JVM 进程中;
通过上述的设计,可以看到整个服务端是无单点,有效地保证了服务端的可用性。
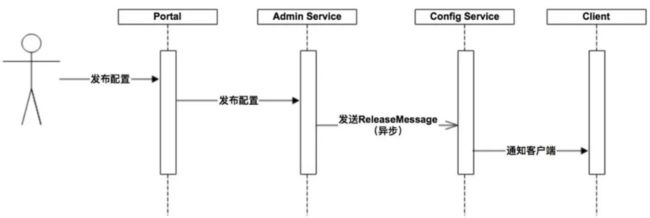
4.实时性:
我们希望我们的配置能够迅速触达应用。
5.适用场景
1)开关
1.发布开关:用于发布过程中
有些新功能依赖于其它系统的新接口,而其它系统的发布周期未必和自己的系统一致,可以加个发布开关,默认把该功能关闭,等依赖系统上线后再打开;
有些新功能有较大风险,可以加个发布开关,上线后一旦有问题可以迅速关闭。
**注意:一旦功能稳定后需要及时清除**发布开关**代码。**
2.灰度开关
A/B 测试:针对特定用户应用新的推荐算法;针对特定百分比的用户使用新的下单流程
白名单:可以事先发到生产环境,只对内部用户打开,测试没问题后按时对全部用户开放
注意:一旦功能稳定后需要及时清除灰度开关代码。
3.运维开关:运维开关通常用于提升系统稳定性
大促前可以把一些非关键功能关闭来提升系统容量;当系统出现问题时可以关闭非关键功能来保证核心功能正常工作。
注意:运维开关可能会长期存在,而且一般会涉及多个系统,所以需要提前规划
2)服务治理
1.黑白名单
对于一些关键服务,哪怕是在内网环境中一般也会对调用方有所限制,比如:
有敏感信息的服务可以通过配置白名单来限制,只有某些应用或 IP 才能调用
某个调用方代码有问题导致超大量调用,对服务稳定性产生了影响,可以通过配置黑名单来暂时屏蔽这个调用方或 IP
一般的做法是在 RPC 框架层添加校验逻辑,结合配置中心的动态推送能力来实现动态调整黑白名单配置。
3)数据库迁移
数据库的迁移也是挺普遍的,比如:原来使用的 SQL Server,现在需要迁移到 MySQL,(同时因为系统整合造成的mysql数据库之间的数据迁移也适用)这种情况就可以结合配置中心来实现平滑迁移:
单写 SQL Server,100% 读 SQL Server;
初始化 MySQL;
双写 SQL Server 和 MySQL,100% 读 SQL Server;
线下校验、补齐 MySQL 数据;
双写 SQL Server 和 MySQL,90% 读 SQL Server,10% 读 MySQL;
双写 SQL Server 和 MySQL,100% 读 MySQL;
单写 MySQL,100% 读 MySQL;
切换完成。
上述的读写开关和比例配置都可以通过配置中心实现动态调整。
4)动态日志级别
服务运行过程中,经常会遇到需要通过日志来排查定位问题的情况,然而这里却有个两难:
如果日志级别很高(如:ERROR),可能对排查问题也不会有太大帮助
-
如果日志级别很低(如:DEBUG),日常运行会带来非常大的日志量,造成系统性能下降
为了兼顾性能和排查问题,我们可以借助于日志组件和配置中心实现日志级别动态调整。
5)动态数据源
数据库是应用运行过程中的一个非常重要的资源,承担了非常重要的角色。
在运行过程中,我们会遇到各种不同的场景需要让应用程序切换数据库连接,比如:数据库维护、数据库宕机主从切换等。