UNIX再学习 -- 内存管理
C 语言部分,就一再的讲内存管理,参看:C语言再学习 -- 再论内存管理 UNIX、Linux 部分还是要讲,足见其重要。
一、存储空间布局
1、我们先了解一个命令 size,继而引出我们今天要讲的内容.
详细可自行 man size 查看
功能:
显示二进制文件中部分的大小,如果没有指定输入文件,则假定 a.out。
size 支持的目标: elf32-i386 a.out-i386-linux pei-i386 elf32-little elf32-big elf64-x86-64 elf32-x86-64 pei-x86-64 elf64-l1om elf64-k1om elf64-little elf64-big plugin srec symbolsrec verilog tekhex binary ihex trad-core
选项:
-A | -B --format = {sysv | berkeley}选择输出样式(默认为berkeley)
-o | -d | -x --radix = {8 | 10 | 16}以八进制,十进制或十六进制显示数字
-t -- totals 显示总大小(仅限伯克利)
-- common 显示* COM *符号的总大小
--target = 设置二进制文件格式
@ 从读取选项
-h --help显示此信息
-v --version显示程序的版本 示例:
# size
text data bss dec hex filename
1621 272 8 1901 76d a.out
讲解:
前 3 列分别为 正文段(text段)、数据段、bbs段(未初始数据段)的长度(以字节为单位)。
第 4 列 和第 5 列分别以十进制和十六进制表示的 3 段的总长度。
最后一列表示文件名,如果没有指定输出,则假定为 a.out。
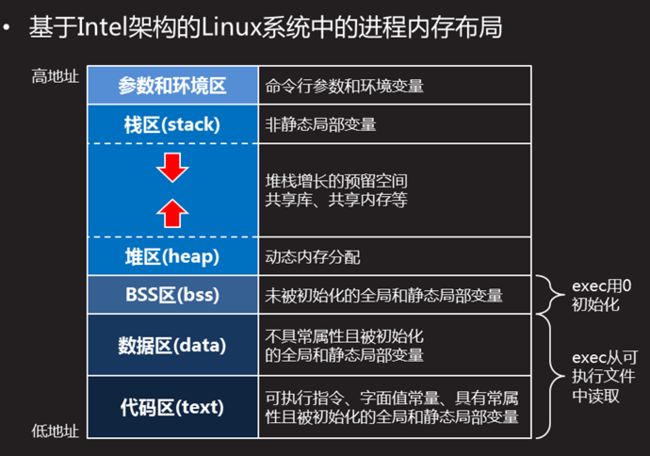
2、存储空间布局
历史沿袭至今,C 程序一直由下列几部分组成:

(1)正文段( text段/代码段)
这是由 CPU 执行的机器指令的部分。通常,正文段是可共享的,所以即使是频繁执行的程序(如文本编辑器,C 编译器和 shell 等)在存储器中也只需有一个副本,另外正文段常常是只读的,以防止程序由于意外而修改其指令。
正文段是用来存放可执行文件的操作指令,也就是说它是可执行程序在内存中的镜像。
(2)初始化数据段(数据段)
数据段用来存放可执行文件中已经初始化的全局变量,换句话说就是存放程序静态分配的变量和全局变量。
例如,C 程序中任何函数之外的声明:
int num = 10;(3)未初始化数据段(bbs段)
bbs段包含了程序中未初始化的全局变量,在程序开始执行之前,内核将此段中的数据初始化为 0 或空指针。
例如:函数外的声明:
long sum[100];(4)堆
堆是用于存放进程进行中被动态分配的内存段,它大小并不固定,可动态扩张或缩减。当进程调用 malloc 等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用 free 等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)。
由于历史上形成的惯例,
堆位于未初始化数据段和栈之间
。
(5)栈
栈是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static 声明的变量,static 意味着在数据段中存放变量)。除此之外在函数调用结束后,函数的返回值也会被存放回栈中。由于栈的后进先出(LIFO)特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲我们可以把堆栈看成一个临时数据寄存,交换的内存区。
(6)参数和环境区
命令行参数和环境变量。
命令行参数:
上篇文章已讲,参看:UNIX再学习 -- 进程环境
每个C语言程序都必须有一个称为main()的函数,作为程序启动的起点。当执行程序时,命令行参数(command-line argument)(由shell逐一解析)通过两个入参提供给 main() 函数。第一个参数int argc,表示命令行参数的个数。第二个参数char *argv[],是一个指向命令行参数的指针数组,每一参数又都是以空字符(null) 结尾的字符串。第一个字符串,亦即argv[0]指向的,(通常)是该程序的名称。argv中的指针列表以NULL指针结尾(即argv[argc]为NULL)。
环境变量:
参看:UNIX再学习 -- 环境变量
3、内容回顾
下图清楚的总结了存储空间布局:
看了一篇文章居然用 size 命令分析 linux 程序内存段的分布,厉害了我的哥。
参看:用size命令分析linux程序内存段的分布
(1)示例一
参考对象,依次与之比较 text、data、bss,查看下面的定义保存在哪个区域内。
int main (void)
{
return 0;
}
# size
text data bss dec hex filename
1056 252 8 1316 524 a.out
(2)示例二
定义可执行指令 、字面值常量 、具有常属性且被 初始化的全局、静态全局 和 静态局部变量,经比较其保存在代码段
参看:字面值常量
参看:什么是可执行语句
参看:什么是可执行语句
const int i = 10;
const static j = 12;
int main (void)
{
const int n = 8;
int a = 9; //变量 a 在栈区;字面值常量 9 在代码段
a = 10; //可执行指令,在代码段
const static int num = 10;
return 0;
}
# size
text data bss dec hex filename
1100 252 8 1360 550 a.out(3)示例三
定义 不具常属性且被初始化的 全局、静态全局 和 静态局部变量,经比较其保存在数据段
static int n = 10;
int num = 10;
int main (void)
{
static int i = 8;
return 0;
}
# size
text data bss dec hex filename
1056 264 8 1328 530 a.out(4)示例四
定义 未初始化全局、静态全局 和 静态局部变量 ,经比较其保存在 bbs段
static int n;
int num;
int main (void)
{
static int i;
return 0;
}
# size
text data bss dec hex filename
1056 252 20 1328 530 a.out
我们之前讲 C 语言再学习部分,涉及到这部分的内容也有不少处。
如:内存区域划分举例说明;段错误、值传递、址传递里的堆栈内容;关键字 static、const;存储类、链接。
看到下面如此多的参看链接,你还觉的内存管理部分简单吗
参看:C语言再学习 -- 内存管理
参看:C语言再学习 -- 段错误(核心已转储)
参看:C语言再学习 -- 值传递,址传递,引用传递
参看:C语言再学习 -- 存储类型关键字
参看:C语言再学习 -- 关键字const
参看:C语言再学习 -- 存储类、链接
二、存储空间分配
ISO C 说明了 3 个用于存储空间动态分配的函数。
#include
void *malloc(size_t size);
void *calloc(size_t nmemb, size_t size);
void *realloc(void *ptr, size_t size);
三个函数返回:若成功则为非空指针,若出错则为NULL
void free(void *ptr);
1、函数比较
(1)malloc,分配指定字节数的存储区。此存储区中的初始值不确定。
(2)calloc,为指定数量指定长度的对象分配存储空间。该空间中的每一位(bit)都初始化为 0.
(3)realloc,增加或减少以前分配区的长度。当增加长度时,可能需将以前分配区的内容移到另一个足都大的区域,以便在尾端提供增加的存储区,而新增区域内的初始值则不确定。
2、函数解析
参看:浅谈malloc,calloc,realloc函数之间的区别
(1)malloc 函数
功能:
malloc函数可以从堆上获得指定字节的内存空间。
返回值:
如果函数执行成功,malloc返回获得内存空间的首地址;如果函数执行失败,那么返回值为NULL。
由于 malloc函数值的类型为void型指针,因此,可以将其值类型转换后赋给任意类型指针,这样就可以通过操作该类型指针来操作从堆上获得的内存空间。
用法:
需要注意的是,malloc函数分配得到的内存空间是未初始化的。因此,一般在使用该内存空间时,要调用另一个函数 memset 来将其初始化为全 0。memset 函数的声明如下:
void * memset (void * p,int c,int n) ;
示例:
#include
#include
#include
int main (void)
{
int *p = (int *)malloc (sizeof (int));
if (NULL == p)
perror ("fail to malloc"), exit (1);
printf ("%d\n", *p);
memset (p, 0, sizeof (int));
printf ("%d\n", *p);
*p = 2;
printf ("%d\n", *p);
free (p);
p = NULL;
return 0;
}
输出结果:
0
0
2 (2)calloc 函数
功能:
calloc函数的功能与malloc函数的功能相似,都是从堆分配内存。int *p = (int *)calloc (SIZE, sizeof (int));
等同于
int *p = (int *)malloc (SIZE * sizeof (int));返回值:
函数返回值为 void 型指针。如果执行成功,函数从堆上获得size * n的字节空间,并返回该空间的首地址。如果执行失败,函数返回NULL。
用法:
该函数与malloc函数的一个显著不同时是,calloc函数得到的内存空间是经过初始化的,其内容全为0。calloc函数适合为数组申请空间,可以将 size 设置为数组元素的空间长度,将 n 设置为数组的容量。
示例:
#include
#include
#define SIZE 5
int main (void)
{
int i = 0;
int *p = (int *)calloc (SIZE, sizeof (int));
if (NULL == p)
perror ("fail to calloc"), exit (1);
for (i = 0; i < SIZE; i++)
p[i] = i;
for (i = 0; i < SIZE; i++)
printf ("p[%d] = %d\n", i, p[i]);
free (p);
p = NULL;
return 0;
}
输出结果:
p[0] = 0
p[1] = 1
p[2] = 2
p[3] = 3
p[4] = 4
(3)realloc 函数
功能:
realloc函数的功能比 malloc 函数和 calloc 函数的功能更为丰富,可以实现内存分配和内存释放。
返回值:
成功返回非空指针,失败返回 NULL
用法:
realloc 函数将指针 ptr 指向的内存块的大小改变为 size 字节。如果 size 小于或等于 ptr 之前指向的空间大小,那么。保持原有状态不变。如果 size 大于原来 ptr 之前指向的空间大小,那么,系统将 重新为 ptr 从堆上分配一块大小为 size 的内存空间,同时,将原来指向空间的内容依次复制到新的内存空间上,ptr 之前指向的空间被释放。relloc 函数分配的空间也是未初始化的。
示例:
#include
#include
int main (void)
{
int i = 0;
int* pn = (int*)malloc(5*sizeof(int));
printf ("malloc %p\n",pn);
for(i = 0;i < 5; i++)
pn[i]=i;
pn = (int*)realloc(pn, 10*sizeof(int));
printf("realloc %p\n",pn);
for(i = 5;i < 10; i++)
pn[i]=i;
for(i=0;i<10;i++)
printf("%d ",pn[i]);
printf ("\n");
free(pn);
return 0;
}
输出结果:
malloc 0x8d59008
realloc 0x8d59008
0 1 2 3 4 5 6 7 8 9
(4)free 函数
功能:
free函数可以实现释放内存的功能。
用法:
从堆上获得的内存空间在程序结束以后,系统不会将其自动释放,需要程序员来自己管理。一个程序结束时,必须保证所有从堆上获得的内存空间已被安全释放,否则,会导致内存泄露。
由于形参为void指针,free函数可以接受任意类型的指针实参。但是,free函数只是释放指针指向的内容,而该指针仍然指向原来指向的地方,此时,指针为野指针,如果此时操作该指针会导致不可预期的错误。
安全做法是:在使用free函数释放指针指向的空间之后,将指针的值置为NULL。因此,对于上面的demo,需要在return 语句前加入以下两行语句:
free(p);
p=NULL;
注意:使用 malloc 函数分配的堆空间在程序结束之前必须释放。
free(p);
p=NULL;
注意:使用 malloc 函数分配的堆空间在程序结束之前必须释放。
3、new、delete函数
这部分现在不求掌握,只要了解。
new/delete 为
C++ 中动态内存分配函数,那么它和 C 中的有何不同呢,简单介绍下。
(1)动态内存的分配和释放的基本语句,我们应该都比较熟悉的,如:
int* p = new int;
delete p;(2)C++ 的 new 操作符允许在动态分配内存时对其做初始化。
int* p = new int;
int* p = new int ();
int* p = new int (100);(3)以数组方式 new 的,也要以数组方式 delete。
int* p = new int[4] {10, 20, 30, 40};
delete[] p;new 操作符所返回的地址是数组首元素的地址,而非所分配内存的起始地址。如果将 new 操作符返回的地址直接交给 delete 操作符,将导致无效指针(invalidate pointer)异常。delete[] 操作符会将交给它的地址向低地址方向偏移 4 或 8个字节,避免了无效指针异常的发生。
delete使用需要注意的地方:
(1)不能通过delete操作符释放已释放过的内存
int* p = new int;
delete p;
delete p; // 核心转储(2)delete野指针后果未定义,delete空指针安全
int* p = new int;
delete p;
p = NULL;
delete p; // 什么也不做内存分配失败操作:
(1)malloc函数
char* p = (char*)malloc (0xFFFFFFFF);
if (p == NULL) {
cerr << "内存分配失败!" << endl;
exit (-1);
}(2)new 函数
try {
char* p = new char[0xFFFFFFFF];
}
catch (bad_alloc& ex) {
cerr << "内存分配失败!" << endl;
exit (-1);
}示例:
#include
#include
using namespace std;
struct Student
{
string name;
int age;
};
int main (void)
{
int *p1 = new int;
*p1 = 1234;
++*p1;
cout << *p1 << endl;
delete p1;
p1 = new int ();
cout << *p1 << endl;
delete p1;
p1 = new int (1234);
cout << *p1 << endl;
delete p1;
p1 = new int[4] {1, 2, 3, 4};
for (size_t i = 0; i < 4; i++)
cout << p1[i] << ' ';
cout << endl;
delete[] p1;
try {
p1 = new int [3];
delete[] p1;
p1 = NULL;
}
catch (exception& ex) {
cout << ex.what() << endl;
perror ("fail to new");
return -1;
}
int (*p2)[4] = new int[3][4];
for (int i = 0; i < 3; i++)
for (int j = 0; j < 4; j++)
p2[i][j] = (i + 1) * 10 + j + 1;
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 4; j++)
cout << p2[i][j] << ' ';
cout << endl;
}
delete[] p2;
int (*p3)[4][5] = new int[3][4][5];
for (int i = 0; i < 3; ++i)
for (int j = 0; j < 4; ++j)
for (int k = 0; k < 5; ++k)
p3[i][j][k] = (i+1)*100+(j+1)*10+k+1;
for (int i = 0; i < 3; ++i) {
for (int j = 0; j < 4; ++j) {
for (int k = 0; k < 5; ++k)
cout << p3[i][j][k] << ' ';
cout << endl;
}
cout << endl;
}
delete[] p3;
string *p4 = new string;
cout << '[' << *p4 << ']' << endl;
delete p4;
p4 = new string ("string");
cout << *p4 << endl;
delete p4;
p4 = new string[3] {"beijing", "shanghai", "shenzhen"};
for (int i = 0; i < 3; i++)
cout << p4[i] << ' ';
cout << endl;
delete[] p4;
Student *p5 = new Student;
p5->name = "mayun";
p5->age = 56;
cout << p5->name << "," << p5->age << endl;
delete p5;
return 0;
}
输出结果:
1235
0
1234
1 2 3 4
11 12 13 14
21 22 23 24
31 32 33 34
111 112 113 114 115
121 122 123 124 125
131 132 133 134 135
141 142 143 144 145
211 212 213 214 215
221 222 223 224 225
231 232 233 234 235
241 242 243 244 245
311 312 313 314 315
321 322 323 324 325
331 332 333 334 335
341 342 343 344 345
[]
string
beijing shanghai shenzhen
mayun,56 三、虚拟内存
1、这部分现在只做了解,Linux 部分会详细介绍的。
Linux 操作系统采用虚拟内存管理技术,使得每个进程都有各自互不干涉的进程地址空间。该空间是块大小为 4 G的线性虚拟空间,用户所看到和接触的都是该虚拟地址,无法看到实际的物理内存地址。利用这种虚拟地址不但能起到保护操作系统的效果(用户不能直接访问物理内存),而且更重要的是用户程序可使用比实际物理内存更大的地址空间。
4G的进程地址空间被认为的分成两部分 -- 用户空间和内核空间。
用户空间从 0 到 3G (0c0000000),内核空间占据3G到4G。用户进程通常情况下只能访问用户空间的虚拟地址,不能访问内核空间虚拟地址。例外情况只有用户进程进行系统调用(代表用户进程在内核态执行)等时刻可以访问到内核空间。
用户空间对应进程,所以每当进程切换,用户空间就会跟着变化;而内核空间是由内核负责映射,它并不会跟着进程改变,是固定的。内核空间地址有自己对应的页表(init_mm.pgd),用户进程各自有不同的页表。
每个进程的用户空间都是完全独立、互不相干的。你可以把程序同时运行 10 次(当然为了同时运行,让它们在返回前一同睡眠100秒吧),你会看到 10 个进程占用的线性地址一模一样。
四、物理内存管理(页管理)
Linux 内核管理物理内存是通过分页机制实现的,它将整个内存划分成无数 4K *(在i386体系结构中)大小页,从而分配和回收内存的基本单位便是内存页了。利用分页管理有助于灵活分配内存地址,因为分配时不必要求必须有大块的连续内存,系统可以东一页、西一页的凑出所需要的内存共进程使用。虽然如此,但是实际上系统使用内存还是倾向于分配连续的内存块,因为分配连续内存时,页表不需要更改,因此能降低刷新率(频繁刷新会很大增加访问速度)。
虚拟内存到物理内存的映射以页(4K = 4096字节)为单位。
涉及到一个函数 getpagesize
#include
int getpagesize(void);
(1)函数功能
主要用于获取当前系统中一个内存页的大小,一般为4Kb(2)示例说明
#include
#include
int main (void)
{
printf ("page size = %d Byte\n", getpagesize ());
return 0;
}
输出结果:
page size = 4096 Byte 五、虚拟内存管理
1、函数 sbrk
#include
void *sbrk(intptr_t increment); (1)函数功能
主要用于按照参数指定的大小来调整内存块的大小。(2)返回值
成功返回上次调用 sbrk/brk 后的堆尾指针,失败返回 -1.
(3)参数解析
increment:虚拟内存增量 (以字节为单位)
大于 0,分配虚拟内存
小于 0,释放虚拟内存
等于 0,当前堆尾指针
(4)函数解析
系统内部维护一个指针,指向当前堆尾,即堆区最后一个字节的下一个位置,sbrk 函数根据增量参数调整该指针的位置,同时返回该指针在调整前的位置,期间若发现内存也耗尽或空闲,则自动追加或取消内存页的映射。
规则:
申请比较小的内存时,一般会默认分配 1 个内存页,申请的内存超过 1 个内存页时,会再次分配 1 个内存页。释放内存时,释放完毕后剩余的内存如果在一个内存页内,则一次性释放 1 个内存页。
(5)示例说明
//sbrk函数的使用
#include
#include
#include
int main(void)
{
//申请4个字节的动态内存
void* p1 = sbrk(4);
void* p2 = sbrk(4);
void* p3 = sbrk(4);
printf("p1 = %p,p2 = %p,p3 = %p\n",p1,p2,p3);
printf("------------------\n");
//获取内存块当前的末尾位置+1
void* cur = sbrk(0);
printf("cur = %p\n",cur);//p3+4
//释放4个字节的内存空间
void* p4 = sbrk(-4);
printf("p4 = %p\n",p4);//p3+4
//获取内存块的当前位置
cur = sbrk(0);
printf("cur = %p\n",cur);//p3
printf("--------------\n");
//再次释放4个字节的内存
p4 = sbrk(-4);
printf("p4 = %p\n",p4);//p3
cur = sbrk(0);
printf("cur = %p\n",cur);//p2
printf("--------------\n");
//目前就剩下4个字节
printf("当前进程PID:%d\n",getpid());
printf("目前进程拥有4个字节\n");
getchar();
sbrk(4093);
printf("申请了4093个字节的内存,恰好超过了1个内存页\n");
getchar();
sbrk(-1);
printf("释放了1个字节的内存,回到了1个内存页的范围\n");
getchar();
return 0;
}
输出结果:
p1 = 0x8141000,p2 = 0x8141004,p3 = 0x8141008
------------------
cur = 0x814100c
p4 = 0x814100c
cur = 0x8141008
--------------
p4 = 0x8141008
cur = 0x8141004
--------------
当前进程PID:4787
目前进程拥有4个字节
1
申请了4093个字节的内存,恰好超过了1个内存页
释放了1个字节的内存,回到了1个内存页的范围
2
(6)示例总结
通过示例可以看出,用 sbrk 分配内存比较方便,用多少内存就传多少增量参数,同时返回指向新分配内存区域的指针,但用 sbrk 做一次性内存释放比较麻烦,因为必须将所有的既往增量进行累加。2、函数 brk
#include
int brk(void *addr); (1)函数功能
表示操作内存的末尾地址到参数指定的位置,如果参数指定的位置大于当前的末尾位置,则申请内存。如果参数指定的地址小于当前的末尾位置,则释放内存。
(2)返回值
成功返回上次调用 sbrk/brk 后的堆尾指针,失败返回 -1.
(3)参数解析
addr:堆尾指针的新位置
大于堆尾指针的原位置:分配虚拟内存
小于堆尾指针的原位置:释放虚拟内存
等于堆尾指针的原位置:什么也没有做
(4)函数解析
系统内部维护一个指针,指向当前堆尾,即堆区最后一个字节的下一个位置,brk函数根据指针参数设置该指针的位置,期间若发现内存页耗尽或空闲,则自动追加或取消内存页的映射。
(5)示例说明
#include
#include
#include
int main (void)
{
//获取一个有效位置
void *p = sbrk (0);
printf ("p = %p\n", p);
//使用 brk 函数申请 4 个字节内存
int res = brk (p + 4);
if (-1 == res)
perror ("fail to brk"), exit (1);
void *cur = sbrk (0);
printf ("cur = %p\n", cur);
//申请 4 个字节
brk (p + 8);
cur = sbrk (0);
printf ("cur = %p\n", cur);
//释放了 4 个字节
brk (p + 4);
cur = sbrk (0);
printf ("cur = %p\n", cur);
//释放了所有字节
brk (p);
cur = sbrk (0);
printf ("cur = %p\n", cur);
return 0;
}
输出结果:
p = 0x98cc000
cur = 0x98cc004
cur = 0x98cc008
cur = 0x98cc004
cur = 0x98cc000
(3)示例总结
通过示例可以看出,用 brk 释放内存比价方便,只需将堆尾指针设到一开始的位置即可一次性释放掉之前分多次分配的内存,但用 brk 分配内存比较麻烦,因为必须根据所需要的内存大小计算出堆尾指针的绝对位置。
3、函数 sbrk 和 brk 搭配使用 (重点)
事实上,sbrk 和 brk 不过是移动堆尾指针的两种不同方法,移动过程中还要兼顾虚拟内存和物理内存之间映射关系的建立和解除(以页为单位)。
上面讲到了:
使用sbrk函数申请内存比较方便,释放内存不太方便;使用brk 函数释放内存比较方便,申请内存不太方便;
所以一般使用sbrk函数和brk函数搭配使用,sbrk函数专门申请,brk函数专门释放。
所以一般使用sbrk函数和brk函数搭配使用,sbrk函数专门申请,brk函数专门释放。
(1)示例说明
//使用sbrk函数和brk函数操作内存
#include
#include
#include
int main()
{
void* cur=sbrk(0); //动态分配内存 和malloc一样的用法
printf("cur=%p\n",cur);
int* pi=(int*)sbrk(sizeof(int));
*pi=100;
double* pd=(double*)sbrk(sizeof(double));
*pd=3.1415926;
char* pc=(char*)sbrk(sizeof(char));
strcpy(pc,"hello");
printf("*pi=%d,*pd=%lf,pc=%s\n",*pi,*pd,pc);
//释放所有的动态内存
brk(pi);//申请开始的
cur=sbrk(0);
printf("cur=%p\n",cur);
return 0;
}
输出结果:
cur=0x9b4c000
*pi=100,*pd=3.141593,pc=hello
cur=0x9b4c000
4、详解 sbrk/brk
(1)man sbrk 查看对于sbrk/brk 描述:
DESCRIPTION
brk() and sbrk() change the location of the program break, which defines the end of the process's data segment (i.e., the program
break is the first location after the end of the uninitialized data segment). Increasing the program break has the effect of allo‐
cating memory to the process; decreasing the break deallocates memory.
brk() sets the end of the data segment to the value specified by addr, when that value is reasonable, the system has enough memory,
and the process does not exceed its maximum data size (see setrlimit(2)).
sbrk() increments the program's data space by increment bytes. Calling sbrk() with an increment of 0 can be used to find the cur‐
rent location of the program break.
简单翻译下:
brk()和sbrk()更改 program break 的位置,该位置定义进程 data segment 的结束(即program break 是 uninitialized data segment 结束后的第一个位置)。
根据下图看出,program break 指向当前堆尾,即堆区最后一个字节的下一个位置。
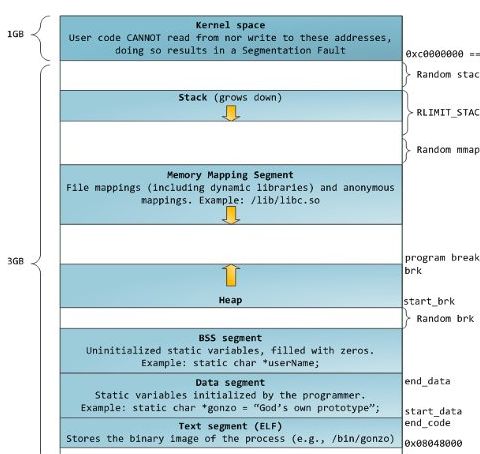
sbrk/brk 分配虚拟内存示意图,如下:


(2)上图分析
参看:Linux下进程内存管理之malloc和sbrk
Linux 下每个进程所分配的虚拟内存空间是 3G,主要包括正文段、数据段、bbs段、堆、栈。而 malloc 所申请的内存空间就是从堆中分配的。
值得注意的地方就是 program break,这是进程堆尾地址。当用户通过 malloc 函数申请空间的时候,实际就是利用 sbrk 函数移动 program break,使其向上增长,以获得更大的堆空间。所以看起来很神秘的内存申请只不过是移动一个指针而已。
(3)示例说明
#include
#include
#include
int main (void)
{
void *cur = sbrk (0);
printf ("cur = %p\n", cur);
void *ptr = malloc (100);
cur = sbrk (0);
printf ("cur = %p\n", cur);
printf ("ptr = %p\n", ptr);
free (ptr);
// ptr = NULL;
cur = sbrk (0);
printf ("cur = %p\n", cur);
printf ("ptr = %p\n", ptr);
return 0;
}
输出结果:
cur = 0x9d9b000
cur = 0x9dbc000
ptr = 0x9d9b008
cur = 0x9dbc000
ptr = 0x9d9b008
(4)示例总结
程序讲解:
程序首先用 sbrk (0) 得到堆尾地址,然后利用 malloc 申请了一个长 100 字节长度的空间,这个时候再看堆尾地址即申请空间的地址。最后,再释放申请的空间然后再看堆尾地址和申请空间地址。
从输出结果可到:
堆尾地址开始是 0x9d9b000 ,利用 malloc 申请完 100 字节空间之后,堆尾地址变为 0x9dbc000,增加了 0x21000。而 malloc 所申请的空间的起始地址是 0x9d9b008,比一开始的堆尾地址后移了 8 个字节。
到这里,参看文章结束,开始自己的理解内容。
工具:进制间转换工具
重点来了,十六进制 0x21000 转换成 十进制为 135168 = 33 * 4096
上面讲到当前系统
内存页的大小为 4Kb
得到结论:
malloc 申请内存,系统会一次映射 33 个内存页。如果超出申请内存不报错,但如果超出 33 个内存页的空间大小,则会出现段错误的。
举个例子:
#include
#include
#include
int main()
{
void *cur = sbrk (0);
printf ("cur=%p\n", cur);
int* pi=(int*)malloc(4);
printf("pi=%p\n",pi);
//故意越界使用一下内存
*(pi+10000)=250;
printf("越界存放的数据是:%d\n",*(pi+10000));//250
//故意超出33个内存页的范围
*(pi+1025*33)=250;
//*(pi+33789)=250;
printf("越界存放的数据是:%d\n",*(pi+1025*33));//int类型 加1等于4个字节
//十六进制的21000就是33个内存页也就是十六进制的1000就是1个内存页
while(1);
return 0;
}
输出结果:
cur=0x8966000
pi=0x8966008
越界存放的数据是:250
段错误 (核心已转储)
示例总结:
用 dmesg 查看错误:
参看:C语言再学习 -- 段错误(核心已转储) 得到:
#dmesg
[131882.277528] test[5977]: segfault at 94ee08c ip 08048476 sp bf8dfcd0 error 6 in test[8048000+1000]
参看:UNIX再学习 -- 错误和警告 得到:
#define ENXIO 6 /* No such device or address */
总结:
一般来说,使用 malloc 申请比较小的动态内存时,操作系统会一次性分配 33 个内存页,从而提高效率。
使用malloc申请的动态内存,千万不要越界访问,极有可能破坏管理信息,从而引发段错误。
5、查看内存结构
(1)通过 cat /proc/进程ID/maps 查看内存的分配情况:
#include
#include
#include
int main()
{
void *cur = sbrk (0);
printf ("cur = %p\n", cur);
//获取当前进程的进程号
printf("进程号是:%d\n",getpid());
int* pi=(int*)malloc(4);
printf("pi=%p\n",pi);
//故意越界使用一下内存
*(pi+10000)=250;
printf("越界存放的数据是:%d\n",*(pi+10000));//250
//故意超出33个内存页的范围
*(pi+33789)=250;
printf("越界存放的数据是:%d\n",*(pi+33789));//int类型 加1等于4个字节
//十六进制的21000就是33个内存页也就是十六进制的1000就是1个内存页
while (1);
return 0;
}
输出结果:
cur = 0x9e6c000
进程号是:6393
pi=0x9e6c008
越界存放的数据是:250
越界存放的数据是:250
//在另一个终端查看:
# cat /proc/6393/maps
08048000-08049000 r-xp 00000000 08:01 2102158 /home/tarena/project/c_test/a.out
08049000-0804a000 r--p 00000000 08:01 2102158 /home/tarena/project/c_test/a.out
0804a000-0804b000 rw-p 00001000 08:01 2102158 /home/tarena/project/c_test/a.out
09e6c000-09e8d000 rw-p 00000000 00:00 0 [heap]
b755c000-b755d000 rw-p 00000000 00:00 0
b755d000-b76fc000 r-xp 00000000 08:01 1704863 /lib/i386-linux-gnu/libc-2.15.so
b76fc000-b76fe000 r--p 0019f000 08:01 1704863 /lib/i386-linux-gnu/libc-2.15.so
b76fe000-b76ff000 rw-p 001a1000 08:01 1704863 /lib/i386-linux-gnu/libc-2.15.so
b76ff000-b7702000 rw-p 00000000 00:00 0
b7713000-b7716000 rw-p 00000000 00:00 0
b7716000-b7717000 r-xp 00000000 00:00 0 [vdso]
b7717000-b7737000 r-xp 00000000 08:01 1704843 /lib/i386-linux-gnu/ld-2.15.so
b7737000-b7738000 r--p 0001f000 08:01 1704843 /lib/i386-linux-gnu/ld-2.15.so
b7738000-b7739000 rw-p 00020000 08:01 1704843 /lib/i386-linux-gnu/ld-2.15.so
bfe48000-bfe69000 rw-p 00000000 00:00 0 [stack]
通过,09e6c000-09e8d000 rw-p 00000000 00:00 0 [heap] (堆)
也可以看出该进程,映射了 33 个内存页。
(2)讲解 maps 文件
参看:Linux下 /proc/maps 文件分析
如:08048000-08049000 r-xp 00000000 08:01 2102158 /home/tarena/project/c_test/a.out
该文件有6列,分别为:
地址:库在进程里地址范围
权限:虚拟内存的权限,r=读,w=写,x=,s=共享,p=私有;
偏移量:库在进程里地址范围
设备:映像文件的主设备号和次设备号;
节点:映像文件的节点号;
路径: 映像文件的路径
每项都与一个vm_area_struct结构成员对应,
地址:库在进程里地址范围
权限:虚拟内存的权限,r=读,w=写,x=,s=共享,p=私有;
偏移量:库在进程里地址范围
设备:映像文件的主设备号和次设备号;
节点:映像文件的节点号;
路径: 映像文件的路径
每项都与一个vm_area_struct结构成员对应,
六、建立/解除到内存的映射
参看:mmap详解
1、mmap 函数
#include
void *mmap(void *addr, size_t length, int prot, int flags,int fd, off_t offset); (1)参数解析
第一个参数:映射区内存起始地址,NULL 系统自动选定后返回
第二个参数:映射区字节长度,自动按页(4K)调整
第三个参数:映射区访问权限,可取以下值:
PROT_READ --映射区可读
PROT_WRITE--映射区可写
PROT_EXEC --映射区可执行
PROT_NONE --映射区不可访问
第四个参数:映射的模式,可取以下值:
MAP_ANONYMOUS 匿名映射,将虚拟内存映射到物理内存,而非文件,忽略 fd 和 offset 参数
MAP_PRIVATE 对映射区的写操作值反映搭配缓冲区中,并不会真正写入文件
MAP_SHARED 对映射区的写操作直接反映到文件中
MAP_SHARED 对映射区的写操作直接反映到文件中
MAP_DENYWRITE 拒绝其它对文件的写操作
MAP_FIXED 若在 addr 上无法创建映射,则失败(无此标志系统会自动调整)
MAP_LOCKED 锁定映射区,保证其不被换出
第五个参数:文件描述符,映射物理内存,给 0 即可
第六个参数:文件偏移量,自动按页(4K)对齐,映射物理内存,给 0 即可
(2)返回值
成功返回映射的地址,失败返回 MAP_FAILED(-1)
(3)函数功能
创建虚拟内存到物理内存或文件的映射
2、munmap 函数
#include
int munmap(void *addr, size_t length); (1)参数解析
第一个参数:映射区内存起始地址必须是页的首地址
第二个参数:映射区字节长度,自动按页(4K)调整
(2)返回值
成功返回 0,失败返回 -1
(3)函数功能
解除虚拟内存到物理内存或文件的映射
(4)示例说明
#include
#include
#include
#include
#include
#include
#include
int main (void)
{
int fd;
struct stat sb;
fd = open("/etc/passwd", O_RDONLY); /*打开/etc/passwd */
char *start = (char*)mmap(NULL, sb.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
if(start == MAP_FAILED) /* 判断是否映射成功 */
perror ("mmap"), exit (1);
printf("%s", start);
munmap(start, sb.st_size); /* 解除映射 */
close (fd);
return 0;
}
输出结果:
同 cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/bin/sh
bin:x:2:2:bin:/bin:/bin/sh
sys:x:3:3:sys:/dev:/bin/sh
.... 七、系统调用
UNIX/Linux 系统的大部分功能都是通过系统调用实现的,如 open、close 等。
UNIX/Linux 的系统调用已被封装成 C 函数的形式,但它们并不是 C 语言标准库的一部分。
标准库函数大部分时间运行在用户态,但部分函数偶尔也会调用系统调用,进入内核态,如 malloc、free 等。
程序员自己编写的代码也可以跳过标准库,直接使用系统调用,如 brk、sbrk、mmap和 munmap 等,与操作系统内核交互,进入内核态。
系统调用在内核中实现,其外部结构定义在 C 库中,该接口的实现借助软中断进入内核。
在学习内核驱动的时候,印象最深的一句话就是:
用户空间切换到内核空间利用系统调用,就是由USR模式切换到SVC模式,说明系统调用本质上靠软中断来实现。
(这部分在讲 Linux 时会重点讲的,现在只做了解)
从应用程序到操作系统内核需要经历如下调用链:

然后介绍两个用于系统调用的指令:
1、time
参看:time 指令
(1)功能
用于统计给定命令所花费的总时间。
(2)示例
# time ./a.out
real 0m0.004s
user 0m0.000s
sys 0m0.000s
(3)解析
输出的信息分别显示了该命令所花费的real时间、user时间和sys时间。
real时间 是指挂钟时间,也就是命令开始执行到结束的时间。这个短时间包括其他进程所占用的时间片,和进程被阻塞时所花费的时间。
user时间 是指进程花费在用户模式中的CPU时间,这是唯一真正用于执行进程所花费的时间,其他进程和花费阻塞状态中的时间没有计算在内。
sys时间 是指花费在内核模式中的CPU时间,代表在内核中执系统调用所花费的时间,这也是真正由进程使用的CPU时间。
real时间 是指挂钟时间,也就是命令开始执行到结束的时间。这个短时间包括其他进程所占用的时间片,和进程被阻塞时所花费的时间。
user时间 是指进程花费在用户模式中的CPU时间,这是唯一真正用于执行进程所花费的时间,其他进程和花费阻塞状态中的时间没有计算在内。
sys时间 是指花费在内核模式中的CPU时间,代表在内核中执系统调用所花费的时间,这也是真正由进程使用的CPU时间。
2、strace
参看:strace 指令(1)功能
我们可以使用strace对应用的系统调用和信号传递的跟踪结果来对应用进行分析,以达到解决问题或者是了解应用工作过程的目的。
(2)参数
-c 统计每一系统调用的所执行的时间,次数和出错的次数等.
-d 输出strace关于标准错误的调试信息.
-f 跟踪由fork调用所产生的子进程.
-ff 如果提供-o filename,则所有进程的跟踪结果输出到相应的filename.pid中,pid是各进程的进程号.
-F 尝试跟踪vfork调用.在-f时,vfork不被跟踪.
-h 输出简要的帮助信息.
-i 输出系统调用的入口指针.
-q 禁止输出关于脱离的消息.
-r 打印出相对时间关于,,每一个系统调用.
-t 在输出中的每一行前加上时间信息.
-tt 在输出中的每一行前加上时间信息,微秒级.
-ttt 微秒级输出,以秒了表示时间.
-T 显示每一调用所耗的时间.
-v 输出所有的系统调用.一些调用关于环境变量,状态,输入输出等调用由于使用频繁,默认不输出.
-V 输出strace的版本信息.
-x 以十六进制形式输出非标准字符串
-xx 所有字符串以十六进制形式输出.
-a column
设置返回值的输出位置.默认 为40.
-e expr
指定一个表达式,用来控制如何跟踪.格式如下:
[qualifier=][!]value1[,value2]...
qualifier只能是 trace,abbrev,verbose,raw,signal,read,write其中之一.value是用来限定的符号或数字.默认的 qualifier是 trace.感叹号是否定符号.例如:
-eopen等价于 -e trace=open,表示只跟踪open调用.而-etrace!=open表示跟踪除了open以外的其他调用.有两个特殊的符号 all 和 none.
注意有些shell使用!来执行历史记录里的命令,所以要使用\\.
-e trace=set
只跟踪指定的系统 调用.例如:-e trace=open,close,rean,write表示只跟踪这四个系统调用.默认的为set=all.
-e trace=file
只跟踪有关文件操作的系统调用.
-e trace=process
只跟踪有关进程控制的系统调用.
-e trace=network
跟踪与网络有关的所有系统调用.
-e strace=signal
跟踪所有与系统信号有关的 系统调用
-e trace=ipc
跟踪所有与进程通讯有关的系统调用
-e abbrev=set
设定 strace输出的系统调用的结果集.-v 等与 abbrev=none.默认为abbrev=all.
-e raw=set
将指 定的系统调用的参数以十六进制显示.
-e signal=set
指定跟踪的系统信号.默认为all.如 signal=!SIGIO(或者signal=!io),表示不跟踪SIGIO信号.
-e read=set
输出从指定文件中读出 的数据.例如:
-e read=3,5
-e write=set
输出写入到指定文件中的数据.
-o filename
将strace的输出写入文件filename
-p pid
跟踪指定的进程pid.
-s strsize
指定输出的字符串的最大长度.默认为32.文件名一直全部输出.
-u username
以username 的UID和GID执行被跟踪的命令(3)示例
主要用法,跟踪程序系统调用使用情况:
starce ./a.out
示例太多,自行尝试。
参看:strace 使用
参看:strace 指令
八、未讲部分
虚拟内存映射部分,我没有往深了去讲,就这已经写了很多内容。
malloc 和 sbrk 关系未讲,malloc/free 源代码未讲,另起一篇文章继续研究内存管理。