JAVA常见关键字及JDK 常用方法源码解读(持续更新...)
版权声明:本文为博主原创文章,转载请注明CSDN博客源地址!共同学习,一起进步~ https://blog.csdn.net/qq_29473881/article/details/82384062
JAVA常见关键字及JDK 常用方法源码分析(持续更新...)
一、JAVA常见关键字
1、this
1)、常用于指向当前类对象本身(指向当前对象的本身),具体实现代码如下:
public class Student {
private String name = "默认值1";
public Student(){
System.out.println("姓名:"+name);
}
public String getName(String name){
this.name = name;
return this.name;
}
}public class Main1 {
public static void main(String[] args) {
Student student = new Student();
String name = student.getName("张三");
System.out.println("返回结果:"+name);
}
}姓名:默认值1
返回结果:张三
Process finished with exit code 0this.name 指向的是private 定义的成员变量name,而不是形参name
2)、this 调用本类构造函数,代码如下:
public class Student {
private String name = "默认值1";
public Student(String name){
System.out.println("姓名:"+name);
}
public Student(String name, int age){
this(name);//调用具有相同形参的构造方法
System.out.println("年纪:"+age);
}
public String getName(String name){
this.name = name;
return this.name;
}
}public class Main1 {
public static void main(String[] args) {
Student student = new Student("李四", 20);
String name = student.getName("张三");
System.out.println("返回结果:"+name);
}
}姓名:李四
年纪:20
返回结果:张三
Process finished with exit code 0this另外一个作用就是调用本类中构造函数(同super,后续再讲)
另外,this只能在类中的非静态方法中使用,静态方法和静态的代码块中绝对不能出现this。
2、super
调用父类构造函数,代码如下:
父类:
public class Class1 {
public Class1(){
System.out.println("父类无参构造函数C");
}
public Class1(String cname){
System.out.println("班级是:"+cname);
}
}子类:
public class Teacher1 extends Class1{
public Teacher1(){
super();
System.out.println("调用父类无参构造函数成功T");
}
public Teacher1(String cname){
super(cname);
System.out.println("调用父类有参构造函数成功K");
}
}public class Main1 {
public static void main(String[] args) {
Teacher1 teacher1 = new Teacher1();
Teacher1 teacher2 = new Teacher1("精英班");
}
}
结果:
父类无参构造函数C
调用父类无参构造函数成功T
班级是:精英班
调用父类有参构造函数成功K
Process finished with exit code 0
可以看出,super可实现调用父类的无参或有参构造函数
super和this的异同:
- super(参数):调用基类中的某一个构造函数(应该为构造函数中的第一条语句)
- this(参数):调用本类中另一种形成的构造函数(应该为构造函数中的第一条语句)
- super: 它引用当前对象的直接父类中的成员(用来访问直接父类中被隐藏的父类中成员数据或函数,基类与派生类中有相同成员定义时如:super.变量名 super.成员函数据名(实参)
- this:它代表当前对象名(在程序中易产生二义性之处,应使用this来指明当前对象;如果函数的形参与类中的成员数据同名,这时需用this来指明成员变量名)
- 调用super()必须写在子类构造方法的第一行,否则编译不通过。每个子类构造方法的第一条语句,都是隐含地调用super(),如果父类没有这种形式的构造函数,那么在编译的时候就会报错。
- super()和this()类似,区别是,super()从子类中调用父类的构造方法,this()在同一类内调用其它方法。
- super()和this()均需放在构造方法内第一行。
- 尽管可以用this调用一个构造器,但却不能调用两个。
- this和super不能同时出现在一个构造函数里面,因为this必然会调用其它的构造函数,其它的构造函数必然也会有super语句的存在,所以在同一个构造函数里面有相同的语句,就失去了语句的意义,编译器也不会通过。
- this()和super()都指的是对象,所以,均不可以在static环境中使用。包括:static变量,static方法,static语句块。
- 从本质上讲,this是一个指向本对象的指针, 然而super是一个Java关键字。
3、final 最终、不可变
final在Java中是一个保留的关键字,可以声明成员变量、方法、类以及本地变量。一旦你将引用声明作final,你将不能改变 这个引用了,编译器会检查代码,如果你试图将变量再次初始化的话,编译器会报编译错误。例子如下:
1)、修饰变量,变量不可改变

提示:Cannot assign a value to final variable 'i' :不能为最终变量'i'赋值。被final修饰的变量初始值是什么,调用时不能重新赋值。
2)、修饰方法,不能被子类重写

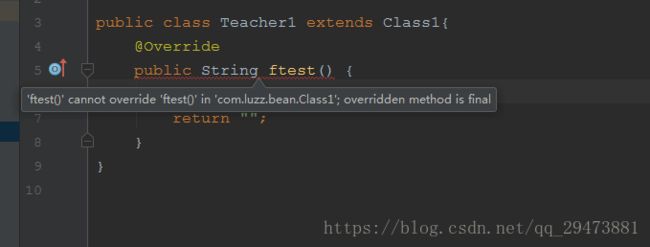
Class1 父类final 修饰的方法ftest() 不能被override重写。
3)、修饰类,类不可被继承

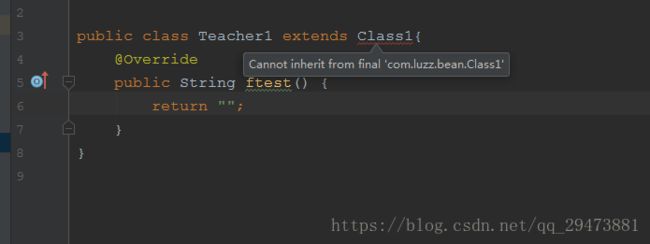
final 修饰的类不能被继承。
网上也有这样解释不可变,挺有道理:如果一个对象,在它创建完成之后,不能再改变它的状态,那么这个对象就是不可变的。不能改变状态的意思是,不能改变对象内的成员变量,包括基本数据类型的值不能改变,引用类型的变量不能指向其他的对象,引用类型指向的对象的状态也不能改变。
4、synchronized 同步锁
主要用于多线程,可修饰类,代码块,方法。一个线程访问一个对象中的synchronized(this)同步代码块时,其他试图访问该对象的线程将被阻塞。修饰类也是一样道理。
(未完待续,后续陆续解析java 其它关键字,评论可留言先说明....)
二、JDK 常用方法源码分析
JDK总体按照以下顺序进行分析:





后期大体会陆续按照以上顺序对jdk常用知识进行分析------------------
1、String 源码分析
谈到String,最常想到的是String 赋值后不可变,这时肯定能想到上文中提到的final修饰的变量不可变原理。
创建一个String对象,查看源码可知,String类确实是被final修饰了。
public final class String
implements java.io.Serializable, Comparable, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = -6849794470754667710L; 可以发现,String类被final修饰,导致不可被继承。细心的同学会发现,同样final还修饰了一个字符数组变量 value[],Java中的String其实就是对字符数组的封装,所以导致String 创建后是不可变的,至于为什么要设计为不可变,那就涉及到内存、同步、数据结构相关方面知识。简单分析:

先看这张图,当创建一个字符串对象时,如果字符串值已经存在于常量池里面,则不会再创建一个新的对象,而是引用已经存在的对象,也就是以下情况时。
String st1 = "abcd";
String st2 = "abcd";这里涉及到一个字符串常量池稍作解释:
字符串常量池是java堆内存中一个特殊的存储区域,JVM(java 虚拟机)为了提高性能和减少内存开销,在实例化字符串常量时进行了一些优化,单独开辟一个字符串常量池,创建字符串常量时,首先判断字符串常量池是否存在该字符串,如果有则直接返回引用实例,不存在,则该字符串放在常量池中。
要实现字符串常量池的前提是,必须保证字符串不可变,不然数据共享时就会产生冲突。 同样,字符串的不可变保证了对应的hashcode永远不变,每次在使用一个字符串的hashcode的时候就不需要重新计算一次,提高了效率。
/** Cache the hash code for the string */
private int hash; // Default to 0(译:缓存字符串的散列码)
另外,不可变对象是线程安全的,多个线程共享时,无需做同步处理
总结来讲,String 设计成不可变,提高了效率和安全性
下面再调试看看String 究竟是如何赋值的:
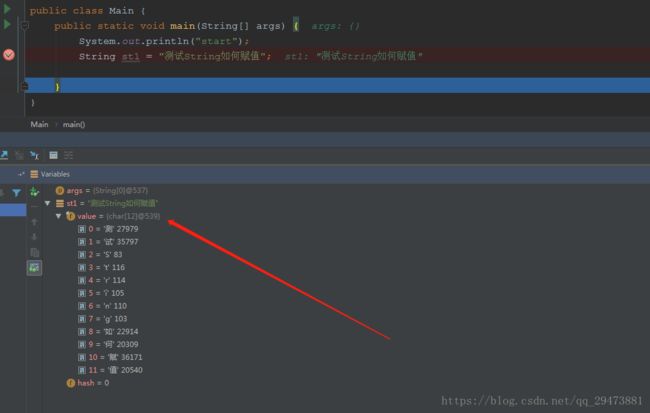
字符串赋值,实际是对字符数组char[]的赋值,这步的时候就可以说明,为什么String不是基本数据类型,String本质是对char[]数组的封装,String只是个类。
/**
* Initializes a newly created {@code String} object so that it represents
* the same sequence of characters as the argument; in other words, the
* newly created string is a copy of the argument string. Unless an
* explicit copy of {@code original} is needed, use of this constructor is
* unnecessary since Strings are immutable.
*
* @param original
* A {@code String}
*/
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}进行new操作,给String赋值的时候,实际上把原字符串的字符数组赋给新字符串的字符数组。
String st1 = "测试String如何赋值";
//相当于----
char[] c = {'测','试','S','t','r','i','n','g','如','何','赋','值'};String 实现了三个接口 Serializable、Comparable
- java.io.Serializable 序列化接口,仅用于表示序列化(后期再做详细分析...)
public interface Serializable {
}- Comparable
接口只有一个compareTo(T 0)接口,用于对两个实例化对象比较大小
public int compareTo(T o);
- CharSequence 包括length(), charAt(int index), subSequence(int start, int end)这几个API接口

以上就是对String 源码的一些简单分析-----
2、StringBuffer和StringBuilder
StringBuffer类
public final class StringBuffer
extends AbstractStringBuilder
implements java.io.Serializable, CharSequence
{
/**
* A cache of the last value returned by toString. Cleared
* whenever the StringBuffer is modified.
*/StringBuilder 类
public final class StringBuilder
extends AbstractStringBuilder
implements java.io.Serializable, CharSequence
{
/** use serialVersionUID for interoperability */
查看这2个类的源码可以看到,StringBuffer和StrnigBuilder都继承了AbstractStringBuilder类
1)、StringBuffer类分析
StringBuffer 也是对字符串的操作,但是String的区别在于StringBuffer 字符串可变,至于为什么可变,那必然要了解StringBuffer的扩容机制。StringBuffer对字符串的操作主要用append和insert方法,append追加内容至末尾,insert在任意处添加内容,以append为例先来看一段代码:
/**
* Constructs a string buffer initialized to the contents of the
* specified string. The initial capacity of the string buffer is
* {@code 16} plus the length of the string argument.
*
* @param str the initial contents of the buffer.
*/
public StringBuffer(String str) {
super(str.length() + 16);
append(str);
}当我们 StringBuffer buffer = new StringBuffer(" ") 初始化StringBuffer 对象时,会在原字符长度基础上加16个长度,所以想要触发扩容机制,增加的字符串长度必须要大于16才行。一步一步来调试观察:
原先字符长度 (测试StringBuffer)为14长度,添加字段长度为17长度。
public static void main(String[] args) {
System.out.println("start");
StringBuffer buffer = new StringBuffer("测试StringBuffer");
System.out.println("未扩容之前内容:"+buffer);
System.out.println("未扩容之前长度:"+buffer.length());
buffer.append("添加扩容测试ABCDEFJHIJK");//设置长度为17 大于默认的16 时才会进行扩容
System.out.println("扩容之后内容:"+buffer);
System.out.println("扩容之后长度:"+buffer.length());
}append追加字符长度为17,和原先的长度14加起来为31,作为参数传进ensureCapacityInternal(minimumCapacity)扩容方法进行判断是否要扩容:

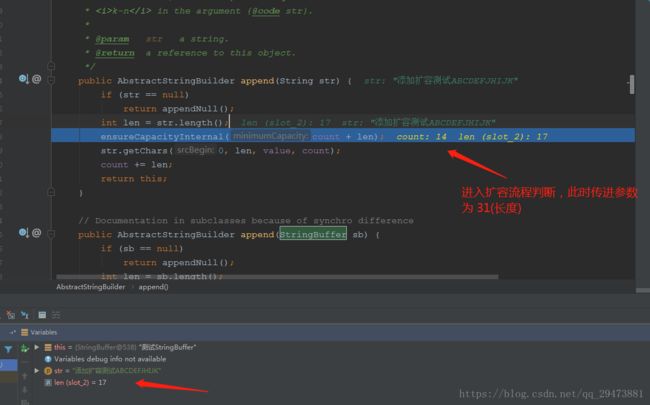
原先总长度为30,31大于30满足扩容条件,进入newCapacity(minimumCapacity) 扩容方法进行扩容
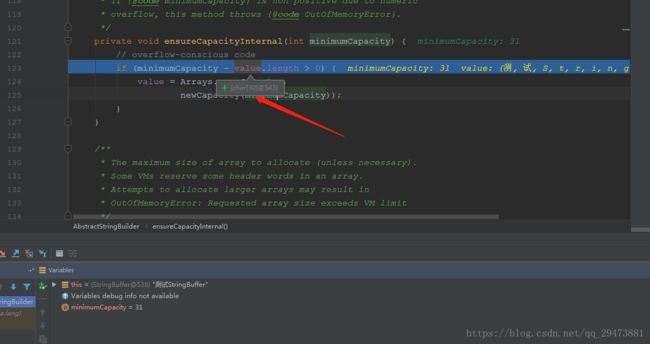
进行扩容,左移1位加2,最后得到结果 62 为扩容后的长度:

回到一开始的方法,可以看到,value长度已经为62,扩容成功,到这一步,返回结果,扩容机制流程基本结束:
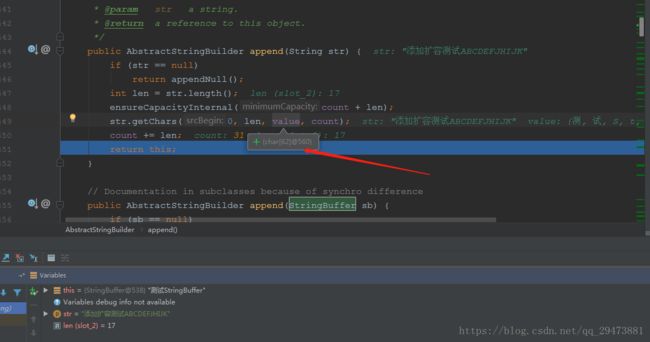
(insert扩容同append基本一直,这里就不多讲,有兴趣的同学可以去看源码,或者评论区留言,再做补充...)
另外也看看StringBuffer中的toString 强转String 方法,实际上就是new一个String对象
@Override
public synchronized String toString() {
if (toStringCache == null) {
toStringCache = Arrays.copyOfRange(value, 0, count);
}
return new String(toStringCache, true);
}StringBuffer 相对于StringBuider 是线程安全的,这点有必要讲一下,留心的同学可以发现,一开始对StringBuffer进行操作时,加了一个synchronized 关键字同步锁,因为加了这个关键字就确保了线程安全。而StringBuider是没有synchronized 修饰的,所以是非线程安全
3、Boolean 类
Boolean 是boolean 的实例化对象类,类似于Integer 对应 int 一样,在jdk1.5.0之后,Boolean在赋值和判断上就已经和boolean一样了。即:
boolean = true —》 Boolean = true 都可以一般在封装集合的时候用到Boolean,(Boolean)map.get(i) 时。
先看下Boolean 的构造方法:
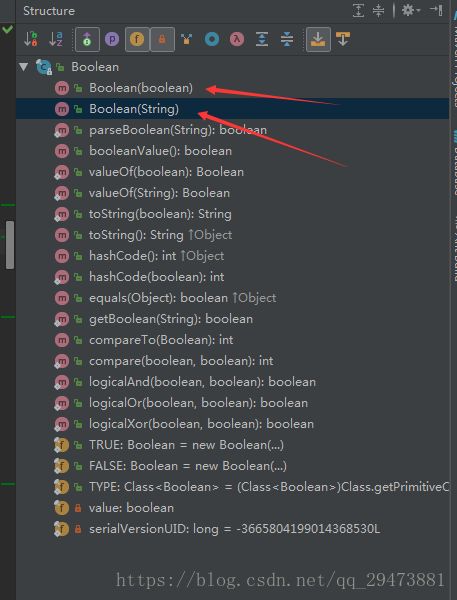
平常主要用到Boolean(boolean) 和 Boolean(String) ,分别做分析,先看Boolean(boolean):
先初始化一个Boolean 为 true
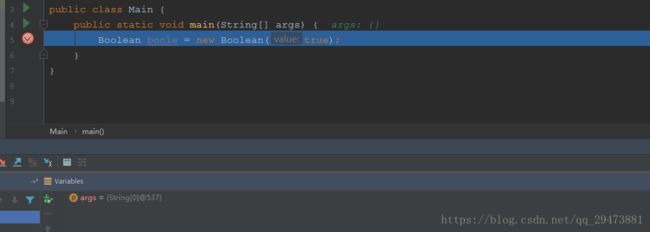
boolean 默认的是false ,当我们创建boolean时,系统会自动赋默认值false,类似于int的默认值是0,其实这一步是由java 虚拟机来实现的,想要深入了解的同学可以看看这篇博客,详细介绍类的初始化与实例化过程:
https://blog.csdn.net/justloveyou_/article/details/72466416

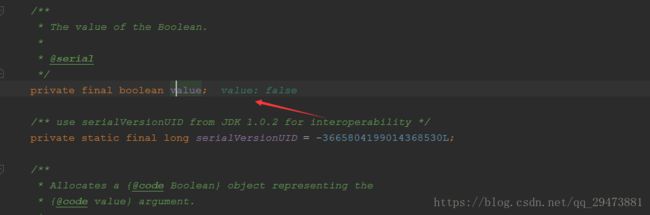
再来看看Boolean(String):
先初始化一个Boolean(String),参数赋为String 类型的 true。
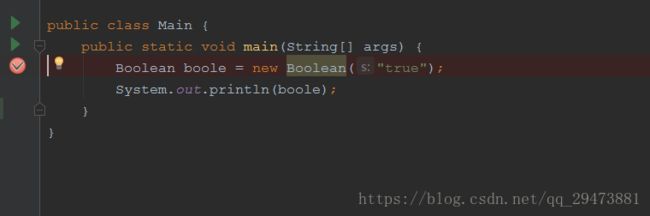
s为"true",调用parseBoolean方法

s 为null时,直接返回false,调用String类的equalsIgnoreCase("true")方法,该方法与比较字符串是否一致方法equals类似,区别是equalsIgnoreCase("true")方法不区分大小写,而equals区分大小写。
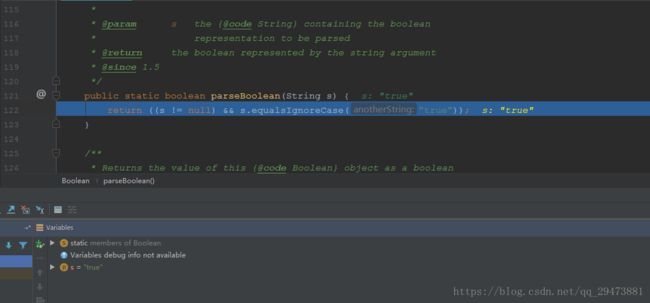
只要是非 true (大小写不区分)时,返回结果都为false,看几个测试的结果就明白:

String 为 TRuE时,返回结果为true
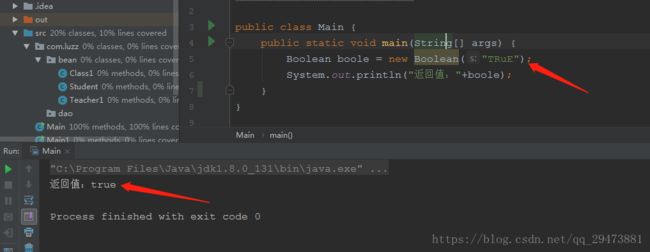
非true时,返回结果为false

以上就是Boolean主要2个方法的分析介绍。
4、集合类
1)、List
它是有序的,允许存放重复元素。因为List的三个实现类ArrayList、LinkedList、Vector分别是有动态数组、双链表、动态数组实现的。而数组和和链表都是允许存放重复数据的。这里我们重点分析这三个实现类,以及List常用的几个方法。
在分析之前,我们先来了解小数组和链表的概念,方便后面的分析。
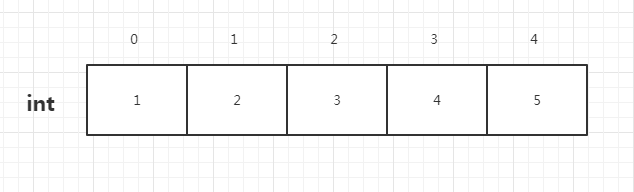
数组:不管是int数组还是String数组,都是有具体数值和数组下标(也可称为索引)组成,数组下标由0开始,依次递增,直到等于数组 长度为止,数组访问时也是根据索引进行访问。
链表:是一种常见的基础数据结构,是一种线性表。常见的链表有:单向链表、双向链表、循环链表、块状链表等。
单向链表:是最简单的一种链表,包含两个组成部分,信息域和指针域。

信息域储存当前节点的信息,指针域储存下一个节点的地址,最后一个节点指向空值。单向链表只能向一个方向遍历。
双向链表:比单向链表稍微复杂些,包含3个域,一个信息域,两个指针域。
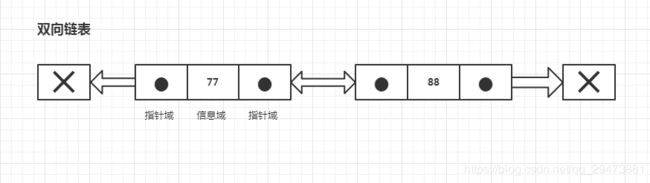
双向链表不仅指向下一个节点的指针,还指向上一个节点的指针,如此设计的目的可以从任何一个节点访问前一个节点,也可以访问 后一个节点,甚至整个链表。
循环链表:就是把第一个节点指向最后一个节点,同样把最后一个节点指向第一个节点,来实现循环链接
(未完待续...)