五种实现网络爬虫的方法(二,基于HttpURLConnection类编写爬虫)
好了,接上一篇。
这篇是基于HttpURLConnection类编写爬虫:java se的net包的核心类,主要用于http的相关操作。
这时候我们的项目结构就变成这样了。
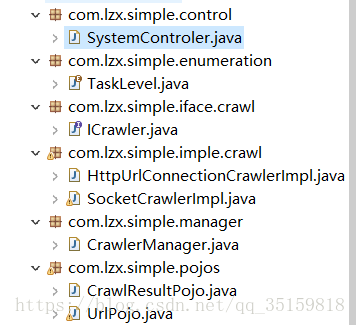
可以看到多了几个类,主要用HttpURLConnection的主要就是HttpUrlConnectionCrawlerImpl类,其他多出来的两个类主要是为了让项目便于管理和维护。
UrlPojo类也加入了一个函数
public HttpURLConnection getConnection(){
try {
URL url=new URL(this.url);
URLConnection connection=url.openConnection();
if (connection instanceof HttpURLConnection) {
return (HttpURLConnection)connection;
}else{
throw new Exception("connection is err");
}
} catch (Exception e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return null;
}将获取并返回HttpURLConnection的工作交给UrlPojo对象来做,
用面向对象的思维来看,这显然是合理的,因为如果把这个工作给HttpURLConnectionCrawlerImpl来做的话,
要更改获取的HttpURLConnection都要改动代码,这显然不是我们想要的。
然后就是
HttpURLConnectionCrawlerImpl
package com.lzx.simple.imple.crawl;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import com.lzx.simple.iface.crawl.ICrawler;
import com.lzx.simple.pojos.CrawlResultPojo;
import com.lzx.simple.pojos.UrlPojo;
public class HttpUrlConnectionCrawlerImpl implements ICrawler{
public CrawlResultPojo crawl(UrlPojo urlPojo) {
CrawlResultPojo crawlResultPojo=new CrawlResultPojo();
if (urlPojo==null||urlPojo.getUrl()==null ){
crawlResultPojo.setSuccess(false);
crawlResultPojo.setPageContent(null);
return crawlResultPojo;
}
HttpURLConnection httpURLConnection=urlPojo.getConnection();
if (httpURLConnection!=null) {
BufferedReader bReader=null;
StringBuilder stringBuilder=new StringBuilder();
try {
bReader=new BufferedReader(new InputStreamReader(httpURLConnection.getInputStream(),"gb2312"));
String line=null;
while ((line=bReader.readLine())!=null) {
stringBuilder.append(line+"\n");
}
crawlResultPojo.setSuccess(true);
crawlResultPojo.setPageContent(stringBuilder.toString());
return crawlResultPojo;
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}finally {
if (bReader!=null) {
try {
bReader.close();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
System.out.println("流最终未关闭");
}
}
}
}
return null;
}
public static void main(String[] args) {
HttpUrlConnectionCrawlerImpl httpUrlConnectionCrawlerImpl=new HttpUrlConnectionCrawlerImpl();
UrlPojo urlPojo=new UrlPojo("http://www.qq.com");
CrawlResultPojo crawlResultPojo=httpUrlConnectionCrawlerImpl.crawl(urlPojo);
System.out.println(crawlResultPojo.getPageContent());
}
}
看着略长,其实呢,和上一篇比对起来其实差别不大
简单来看就是,通过UrlPojo的函数来获得HttpURLConnection对象,然后获取输入流下载网页。
当然,不同的网页可能会有不同的编码格式,如百度是utf-8,qq是gb2312,我们可以在输入流中改变编码格式。
然后我们来看看多出来的两个类,
首先是CrawlerManager
package com.lzx.simple.manager;
/**
* 包含业务逻辑抓取管理器
* @author Administrator
*
*/
import com.lzx.simple.iface.crawl.ICrawler;
import com.lzx.simple.imple.crawl.HttpUrlConnectionCrawlerImpl;
import com.lzx.simple.imple.crawl.SocketCrawlerImpl;
import com.lzx.simple.pojos.CrawlResultPojo;
import com.lzx.simple.pojos.UrlPojo;
public class CrawlerManager {
private static ICrawler crawler;
private static CrawlerManager single_crawlerManager=new CrawlerManager(true);
public CrawlResultPojo crawl(UrlPojo urlPojo){
return crawler.crawl(urlPojo);
}
private CrawlerManager(boolean isSocket){
crawler=new SocketCrawlerImpl();
}
public static void setMethod(boolean isSocket) {
if (isSocket) {
crawler=new SocketCrawlerImpl();
}else {
crawler=new HttpUrlConnectionCrawlerImpl();
}
}
public static CrawlerManager getCrawlerManager(){
return single_crawlerManager;
}
public static void main(String[] args) {
CrawlerManager crawlerManager=new CrawlerManager(true);
UrlPojo urlPojo=new UrlPojo("http://www.baidu.com");
CrawlResultPojo crawlResultPojo=crawlerManager.crawl(urlPojo);
System.out.println(crawlResultPojo.getPageContent());
}
}
很显然这是爬虫的管理类,为什么要这么写呢。
现在通过setMethod函数可以选择用Socket还是HttpURLConnection来抓取页面
通过这么写我们在外部就可以很容易的调用封装后的抓取过程

很显然,管理类是单例的,我们不需要随时随地有不同的管理类,
而且这个管理类会经常调用,所以我们直接使用饿汉式的单例写法就可以了。
关于单例模式不了解的可以去看看相关书籍,
主要用途就是让一个类只能有一个实例。
然后我们再给UrlPojo加一个toString函数,直接让系统自动生成就好了
最后就是外部调用的SystemControler类
package com.lzx.simple.control;
import java.util.ArrayList;
import java.util.List;
import com.lzx.simple.manager.CrawlerManager;
import com.lzx.simple.pojos.CrawlResultPojo;
import com.lzx.simple.pojos.UrlPojo;
public class SystemControler {
public static void main(String[] args) {
List urlPojos=new ArrayList();
UrlPojo urlPojo1=new UrlPojo("http://www.baidu.com");
UrlPojo urlPojo2=new UrlPojo("http://www.qq.com");
urlPojos.add(urlPojo1);
urlPojos.add(urlPojo2);
CrawlerManager crawlerManager=CrawlerManager.getCrawlerManager();
CrawlerManager.setMethod(false);
for(UrlPojo urlPojo:urlPojos){
CrawlResultPojo crawlResultPojo=crawlerManager.crawl(urlPojo);
System.out.println("抓取任务为:"+urlPojo.toString());
System.out.println("抓取结果为:"+crawlResultPojo.isSuccess());
}
}
}
经过刚刚的封装我们让抓取变得更加简洁了,管理也更加方便。
如上