Linux- 字符管理命令—grep/egrep/cut/sed/awk/sort/wc/xargs
1 grep
grep通过正则表达式查找文件中的关键字,其参数如下:
-i 忽略大小写 -v 排除匹配的关键字
-r 递归匹配 -n 显示匹配关键字的行号
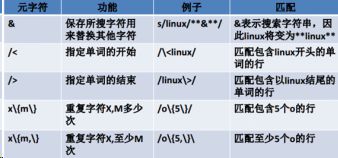
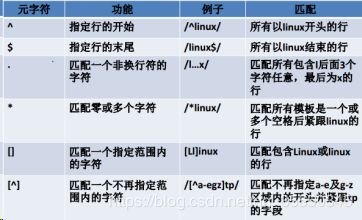
^ 匹配以什么为开头的 $ 匹配以什么为结尾的
这几个是重点
\< 指定单词的开始 \> 指定单词的结束
[ ] 匹配单个字符 [n-m]:n-m都符合要求
* 所有字符
例如:
grep -ri “test” ./ //在当前目录下查找包含test关键字的文件或目录,不区分大小写且递归查找
grep -n “test” f1 //显示匹配test的关键行并显示行号
grep -n “^#” 文件名 //查找以#为开头的行并显示行号
grep -n “#$” 文件名 //查找以#为结尾的行并显示行号
grep -r “c$” ./ //查找当前目录下所有内容包含以c结尾的文件
grep ‘\’ 文件名 //查找“man”仅匹配此三个字符
grep ‘\ 2 egrep 是grep的增强版
?:匹配?前的正则表达式0-1次 + :匹配+前的正则表达式1-多次
例如:
egrep ‘(^D|^d)’ 文件名 //查找以D或d字符为开头的行
egrep ^D? 文件名 //查找以D开头的0到1个字符
egrep -v ‘^(Linux|kvm)’ 文件名 //查找不包含Linux与 kvm的字段3 cut 截取需要的列
cut -d “n” -f n //n代表选取的分隔符,n 代表选择截取的列
例如:
cut -d “ ” -f 2 文件路径 //以空格符号为分界符,将第2列截取
cut -d “:” –f 1,3 文件路径 //以冒号为分界符,将第1,3列截取4 sed
sed是个流式编辑器,它将文件内容一行一行的读入内容,对内容中所在行匹配或者编辑,然后输出。
d 删除 -i 使操作生效 -e多点编辑 g 行内全面替换
-n取消默认输出 p 打印行 (-n与p配合使用)
例如:
sed ‘1,3d’ 文件名 //删除内存中的1到3行
sed -i 1,25d 文件名 //删除文件中的1-25行
sed ‘3,$d’ 文件名 //删除第3行到末尾行
sed -e ‘1,3d’-e ‘24d’ 文件名 //删除1到3行和第24行
sed –n “s/root/RoOt/g” 文件名 //将文件中所有的root替换为RoOt,g为行内全面替换
sed -i “s/Enforcing/disabled/g” /etc/selinux/config //关闭SELinux
sed ‘/data/d’ 文件名 //删除含有data字段的行
sed ‘/ftp/p’ 文件名 //打印匹配字段的行及所有行
sed -n ‘/ftp/p’ 文件名 //答应匹配字段的行
sed -n ‘/^[Aa]pache/p’ 文件名 //查找文件中以A或a为开头且后面字符为pache的字串
sed -n ‘/ra/,/data/p’ 文件名 //显示包含ra 和data字段的行
sed ‘s/noarch$/&.linux/’文件名 //将行尾noarch为结尾后面增加.linux字符
sed –n ‘s/data/date/p’ 文件名 //将data替换为date
sed –e ‘1,3d’-e ‘s/data/date/p’ 文件名 //删除1-3行,将data改为date
sed ‘/tzdata/r newtest’ 文件名 //查找tzdata字段,将newtest文件内容加入到该字段下5 awk
awk “关键字” 文件名 //可以匹配关键字 awk “/root/” passwd。与grep类似
df -h | awk ‘{print $1,$2}’ //获取指定的第1、2列,默认以空格作为分隔符
df -h | awk ‘NR=行号’ //获取指定的行
awk –F “分隔符” ‘{print $列号}’ 文件名 //也可以指定分隔符截取列
df -h |grep “sda2”|awk ‘{print $5}’ //抓取关键字这一行,然后截取第5列
df –h | awk ‘/data/ {print$2}’ 文件名 //抓取data行并输出第二列
date | awk ‘{print “Year:”$6“\nMonth:”$2}’ // \n代表enter换行
df –h | awk ‘$1~/sda/’ //在指定列第一列匹配关键字
df –h | awk ‘$1!~/sda/’ //在指定列第一列匹配关键字,但不打印出来6 sort
格式: sort –t “分隔符” –k 行数 -n数值排列 -r降序排列
sort –t “:” –k 3 -n -r passwd
//将passwd 中的第三列按照数值降序排列,默认是按照字符排列
sort -t “:” -k 3
//这就是默认情况,按照字符升序排列,结果会乱七八糟
7 wc
-l 统计行数(常用) -w统计单词数 -c统计字节数
ps aux //查看系统所有进程信息,占内存百分比,每个进程占一行,第一行属于是标题行
ps aux | sed 1d | wc -l //查看当前系统内有多少个进程
netstat -lantu | grep ESTABLISHED | wc –l //查看当前系统有多少个链接
wc -l 文件名 //查看文件有多少行
8 xargs用来传递命令参数
find /etc -name passwd | xargs file
//找到文件passwd并确定其文件类型。原本没有xargs命令的结果是/etc/passwd file ,xargs的作用就是将其变成 file /etc/passwd ,这样才能运行出结果,否则会报错。
转载请注明出处,谢谢!