HttpClient
HttpClient主页: http://hc.apache.org/
HttpClient下载:http://hc.apache.org/downloads.cgi
主页:http://hc.apache.org/httpcomponents-client-4.5.x/index.html

HttpClient简介
超文本传输协议(HTTP)也许是现在 Internet 上使用得最多、最重要的协议了。Web服务,有网络功能的设备和网络计算的发展,都持续扩展了HTTP协议的角色,超越了用户使用的Web浏览器范畴,同时,也增加了需要HTTP协议支持的应用程序的数量。越来越多的 Java 应用程序需要直接通过 HTTP 协议来访问网络资源。HttpClient 是 Apache Jakarta Common 下的子项目,用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。HttpClient 已经应用在很多的项目中,比如 Apache Jakarta 上很著名的另外两个开源项目 Cactus 和 HTMLUnit 都使用了 HttpClient。
尽管java.net包提供了基本通过HTTP访问资源的功能,但它没有提供全面的灵活性和其他应用程序需要的功能。HttpClient就是需求弥补这项空白的组件,通过提供一个有效的,保持更新的,功能丰富的软件包来实现客户端最新的HTTP标准和建议。
HttpClient 为扩展而设计,同时为基本的HTTP协议提供强大的支持,HttpClient组件也许就是构建Http客户端应用程序,比如web浏览器,web服务器,利用或扩展Http协议进行分布式通信的系统的开发人员的关注点。
我们搞爬虫的,主要是用HttpClient模拟浏览器请求第三方站点url,然后响应,获取网页数据,然后用Jsoup来提取我们需要的信息。
Maven 地址:
import org.apache.http.HttpEntity;
import org.apache.http.HttpHost;
import org.apache.http.ParseException;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.junit.Test;
import org.apache.commons.io.FileUtils;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
org.apache.httpcomponents
httpclient
4.5.7
gradle 地址:
//添加 httpclient 支持
// https://mvnrepository.com/artifact/org.apache.httpcomponents/httpclient
compile group: 'org.apache.httpcomponents', name: 'httpclient', version: '4.5.7'
简单演示
前面我们介绍了HttpClient 这个框架主要用来请求第三方服务器,然后获取到网页,得到我们需要的数据。获取网站首页源码,要获得具体数据的话,要用到Jsoup。
gradle 配置:
//添加 httpclient 支持
// https://mvnrepository.com/artifact/org.apache.httpcomponents/httpclient
compile group: 'org.apache.httpcomponents', name: 'httpclient', version: '4.5.7'
//添加 jsoup 支持
// https://mvnrepository.com/artifact/org.jsoup/jsoup
compile group: 'org.jsoup', name: 'jsoup', version: '1.11.3'
//添加 FileUtils 支持
// https://mvnrepository.com/artifact/commons-io/commons-io
compile group: 'commons-io', name: 'commons-io', version: '2.6'@Test
public void test() throws IOException {
CloseableHttpClient httpClient = HttpClients.createDefault(); // 创建httpClient实例
HttpGet httpGet = new HttpGet("https://blog.csdn.net/"); // 创建httpget实例
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet); // 执行http get请求
} catch (ClientProtocolException e) { // http协议异常
e.printStackTrace();
} catch (IOException e) { // io异常
e.printStackTrace();
}
HttpEntity entity = response.getEntity(); // 获取返回实体
try {
System.out.println("网页内容:" + EntityUtils.toString(entity, "utf-8")); // 获取网页内容
} catch (ParseException e) { // 解析异常
e.printStackTrace();
} catch (IOException e) { // io异常
e.printStackTrace();
}
try {
response.close(); // response关闭
} catch (IOException e) { // io异常
e.printStackTrace();
}
try {
httpClient.close(); // httpClient关闭
} catch (IOException e) {
e.printStackTrace();
}
}假如你对这些异常都熟悉 我们可以简化下,异常抛出,这样代码可读性好点。
/**
* 异常全部抛出
* 这样请求容易被服务器拒绝,有些服务器做了限制,拒绝服务,只允许游览器(代理工具)代理
* 比如:推酷 爬取的别人的,但是他不让别爬取它的类容
*/
@Test
public void test2() throws IOException {
CloseableHttpClient httpClient = HttpClients.createDefault(); // 创建httpClient实例
HttpGet httpGet = new HttpGet("http://www.tuicool.com/"); // 创建httpget实例
CloseableHttpResponse response = httpClient.execute(httpGet); // 执行http get请求
HttpEntity entity = response.getEntity(); // 获取返回实体
System.out.println("网页内容:" + EntityUtils.toString(entity, "utf-8")); //获取网页内容( 指定编码打印网页内容) EntityUtils 工具类设置编码
response.close(); // response关闭
httpClient.close(); // httpClient关闭
}但是实际开发的话,我们对于每一种异常的抛出,catch里都需要做一些业务上的操作,所以以后用的话,还是第一种,假如爬虫任务很简单,容易爬取,并且量小,那就第二种。还是要根据具体情况来。
HttpClient设置请求头消息User-Agent模拟浏览器
HttpClient设置请求头消息User-Agent模拟浏览器,比如我们请求 www.tuicool.com 。
/**
* 不设置请求
*/
@Test
public void test3() throws IOException {
CloseableHttpClient httpClient=HttpClients.createDefault(); // 创建httpClient实例
HttpGet httpGet=new HttpGet("http://www.tuicool.com/"); // 创建httpget实例
CloseableHttpResponse response=httpClient.execute(httpGet); // 执行http get请求
HttpEntity entity=response.getEntity(); // 获取返回实体
System.out.println("网页内容:"+EntityUtils.toString(entity, "utf-8")); // 获取网页内容
response.close(); // response关闭
httpClient.close(); // httpClient关闭
}网页内容:
系统检测亲不是真人行为,因系统资源限制,我们只能拒绝你的请求。如果你有疑问,可以通过微博 http://weibo.com/tuicool2012/ 联系我们。
我们模拟下浏览器 设置下User-Agent头消息:加下
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0"); // 设置请求头消息User-Agent/**
* 模拟游览器
*/
@Test
public void test3() throws IOException {
CloseableHttpClient httpClient=HttpClients.createDefault(); // 创建httpClient实例
HttpGet httpGet=new HttpGet("http://www.tuicool.com/"); // 创建httpget实例
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0");
CloseableHttpResponse response=httpClient.execute(httpGet); // 执行http get请求
HttpEntity entity=response.getEntity(); // 获取返回实体
System.out.println("网页内容:"+EntityUtils.toString(entity, "utf-8")); // 获取网页内容
response.close(); // response关闭
httpClient.close(); // httpClient关闭
}当然通过火狐firebug,我们还可以看到其他请求头消息。
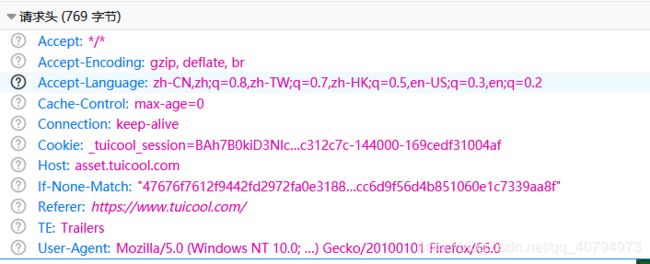
都是可以通过setHeader方法 设置key value;来得到模拟浏览器请求。
HttpClient获取响应内容类型Content-Type
响应的网页内容都有类型也就是Content-Type,通过火狐firebug,我们看响应头信息:
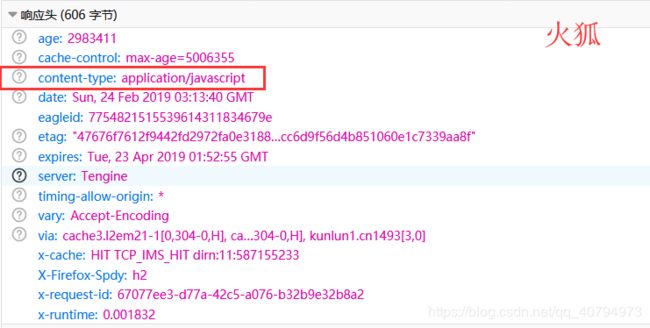
当然我们可以通过HttpClient接口来获取,HttpEntity的getContentType().getValue() 就能获取到响应类型。
/**
* 获取响应类型
*/
@Test
public void test4() throws IOException {
CloseableHttpClient httpClient=HttpClients.createDefault(); // 创建httpClient实例
HttpGet httpGet=new HttpGet("http://central.maven.org/maven2/HTTPClient/HTTPClient/0.3-3/HTTPClient-0.3-3.jar"); // 创建httpget实例
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0");
CloseableHttpResponse response=httpClient.execute(httpGet); // 执行http get请求
HttpEntity entity=response.getEntity(); // 获取返回实体
System.out.println("Content-Type:"+entity.getContentType().getValue());//entity.getContentType()返回的是 key, .getValue() 用于获取值
//System.out.println("网页内容:"+EntityUtils.toString(entity, "utf-8")); // 获取网页内容
response.close(); // response关闭
httpClient.close(); // httpClient关闭
}输出:
Content-Type:application/java-archive
一般网页是text/html当然有些是带编码的,比如请求www.tuicool.com:输出:
Content-Type:text/html; charset=utf-8
假如请求js文件,比如 http://www.open1111.com/static/js/jQuery.js
运行输出:
Content-Type:application/javascript
假如请求的是文件,比如 http://central.maven.org/maven2/HTTPClient/HTTPClient/0.3-3/HTTPClient-0.3-3.jar
运行输出:
Content-Type:application/java-archive
当然Content-Type还有一堆,那这东西对于我们爬虫有啥用的,我们再爬取网页的时候 ,可以通过Content-Type来提取我们需要爬取的网页或者是爬取的时候,需要过滤掉的一些网页。
HttpClient获取响应状态Status
我们HttpClient向服务器请求时,正常情况 执行成功 返回200状态码,不一定每次都会请求成功,比如这个请求地址不存在返回404,服务器内部报错返回500,有些服务器有防采集,假如你频繁的采集数据,则返回403 拒绝你请求。当然 我们是有办法的 后面会讲到用代理IP。
这个获取状态码,我们可以用 CloseableHttpResponse对象的getStatusLine().getStatusCode()
200 正常
403 拒绝
500 服务器报错
400 未找到页面/**
* 获取响应状态
*/
@Test
public void test5() throws IOException {
CloseableHttpClient httpClient=HttpClients.createDefault(); // 创建httpClient实例
HttpGet httpGet=new HttpGet("http://www.open1111.com/"); // 创建httpget实例
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0");
CloseableHttpResponse response=httpClient.execute(httpGet); // 执行http get请求
System.out.println("Status:"+response.getStatusLine().getStatusCode());//getStatusLine()返回Status:HTTP/1.1 200
HttpEntity entity=response.getEntity(); // 获取返回实体
//System.out.println("Content-Type:"+entity.getContentType().getValue());
//System.out.println("网页内容:"+EntityUtils.toString(entity, "utf-8")); // 获取网页内容
response.close(); // response关闭
httpClient.close(); // httpClient关闭
}假如换个页面 https://blog.csdn.net/qq_40794973/hehe.jsp 因为不存在,所以返回 404。
抓取图片
/**
* 抓取图片
* commons io apache io框架
*/
@Test
public void test6() throws IOException {
CloseableHttpClient httpClient=HttpClients.createDefault(); // 创建httpClient实例
HttpGet httpGet=new HttpGet("http://www.java1234.com/gg/dljd4.gif"); // 创建httpget实例
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0");
CloseableHttpResponse response=httpClient.execute(httpGet); // 执行http get请求
HttpEntity entity=response.getEntity(); // 获取返回实体
if(entity!=null){
System.out.println("ContentType:"+entity.getContentType().getValue());
InputStream inputStream=entity.getContent();
FileUtils.copyToFile(inputStream, new File("F:/Test/download.gif"));
}
response.close(); // response关闭
httpClient.close(); // httpClient关闭
}
HttpClient使用代理IP
在爬取网页的时候,有的目标站点有反爬虫机制,对于频繁访问站点以及规则性访问站点的行为,会采集屏蔽IP措施。这时候,代理IP就派上用场了。关于代理IP的话也分几种、透明代理、匿名代理、混淆代理、高匿代理。
1、透明代理(Transparent Proxy)
REMOTE_ADDR = Proxy IP
HTTP_VIA = Proxy IP
HTTP_X_FORWARDED_FOR = Your IP
透明代理虽然可以直接“隐藏”你的IP地址,但是还是可以从HTTP_X_FORWARDED_FOR来查到你是谁。
2、匿名代理(Anonymous Proxy)
REMOTE_ADDR = proxy IP
HTTP_VIA = proxy IP
HTTP_X_FORWARDED_FOR = proxy IP
匿名代理比透明代理进步了一点:别人只能知道你用了代理,无法知道你是谁。
3、混淆代理(Distorting Proxies)
REMOTE_ADDR = Proxy IP
HTTP_VIA = Proxy IP
HTTP_X_FORWARDED_FOR = Random IP address
如上,与匿名代理相同,如果使用了混淆代理,别人还是能知道你在用代理,但是会得到一个假的IP地址,伪装的更逼真。
4、高匿代理(Elite proxy或High Anonymity Proxy)
REMOTE_ADDR = Proxy IP
HTTP_VIA = not determined
HTTP_X_FORWARDED_FOR = not determined
可以看出来,高匿代理让别人根本无法发现你是在用代理,所以是最好的选择。一般我们搞爬虫 用的都是 高匿的代理IP。
那代理IP 从哪里搞呢 很简单 百度一下,你就知道 一大堆代理IP站点。 一般都会给出一些免费的,但是花点钱搞收费接口更加方便。比如 http://www.66ip.cn/ https://www.xicidaili.com/?=144581。
httpClient使用代理IP代码:
/**
* 使用代理 ip
* https://www.xicidaili.com/?=144581
*/
@Test
public void test7() throws IOException {
CloseableHttpClient httpClient=HttpClients.createDefault(); // 创建httpClient实例
HttpGet httpGet=new HttpGet("http://www.tuicool.com/"); // 创建httpget实例
HttpHost proxy=new HttpHost("116.209.54.43", 9999);
RequestConfig config=RequestConfig.custom().setProxy(proxy).build();
httpGet.setConfig(config);
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0");
CloseableHttpResponse response=httpClient.execute(httpGet); // 执行http get请求
HttpEntity entity=response.getEntity(); // 获取返回实体
System.out.println("网页内容:"+EntityUtils.toString(entity, "utf-8")); // 获取网页内容
response.close(); // response关闭
httpClient.close(); // httpClient关闭
}![]()
建议大家用国内代理IP 以及主干道网络大城市的代理IP 访问速度快。
HttpClient连接超时及读取超时
httpClient在执行具体http请求时候 有一个连接的时间和读取内容的时间。
HttpClient连接时间
所谓连接的时候 是HttpClient发送请求的地方开始到连接上目标url主机地址的时间,理论上是距离越短越快,线路越通畅越快,但是由于路由复杂交错,往往连接上的时间都不固定,运气不好连不上,HttpClient的默认连接时间,据我测试,默认是1分钟,假如超过1分钟 过一会继续尝试连接,这样会有一个问题 假如遇到一个url老是连不上,会影响其他线程的线程进去,说难听点,就是蹲着茅坑不拉屎。所以我们有必要进行特殊设置,比如设置10秒钟 假如10秒钟没有连接上 我们就报错,这样我们就可以进行业务上的处理,比如我们业务上控制 过会再连接试试看。并且这个特殊url写到log4j日志里去。方便管理员查看。
HttpClient读取时间
所谓读取的时间 是HttpClient已经连接到了目标服务器,然后进行内容数据的获取,一般情况 读取数据都是很快速的,但是假如读取的数据量大,或者是目标服务器本身的问题(比如读取数据库速度慢,并发量大等等..)也会影响读取时间。同上,我们还是需要来特殊设置下,比如设置10秒钟 假如10秒钟还没读取完,就报错,同上,我们可以业务上处理。
比如我们这里给个地址 http://central.maven.org/maven2/ ,这个是国外地址 连接时间比较长的,而且读取的内容多 很容易出现连接超时和读取超时。
我们如何用代码实现呢?
HttpClient给我们提供了一个RequestConfig类 专门用于配置参数比如连接时间,读取时间以及前面讲解的代理IP等。
这里给下示例代码:
/**
* 连接超时
* 读取超时
*/
@Test
public void test8() throws IOException {
CloseableHttpClient httpClient=HttpClients.createDefault(); // 创建httpClient实例
HttpGet httpGet=new HttpGet("http://central.maven.org/maven2/"); // 创建httpget实例
RequestConfig config=RequestConfig.custom()
.setConnectTimeout(10000) // 设置连接超时时间 10秒钟
.setSocketTimeout(20000) // 设置读取超时时间10秒钟
.build();
httpGet.setConfig(config);
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0");
CloseableHttpResponse response=httpClient.execute(httpGet); // 执行http get请求
HttpEntity entity=response.getEntity(); // 获取返回实体
System.out.println("网页内容:"+EntityUtils.toString(entity, "utf-8")); // 获取网页内容
response.close(); // response关闭
httpClient.close(); // httpClient关闭
}![]()