【Spark】SparkCore入门解析(二)

(图片来源于网络,侵删)
一、RDD概念
【1】RDD概述
① RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合
② 在 Spark 中,对数据的所有操作不外乎创建 RDD、转化已有RDD 以及调用 RDD 操作进行求值
③ RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性
④ RDD支持两种操作:转化操作和行动操作
⑤ Spark采用惰性计算模式,只有在执行行动算子的时候,才会真正计算
⑥ 默认情况下,Spark 的 RDD 会在你每次对它们进行行动操作时重新计算。如果想在多个行动操作中重用同一个 RDD,可以使用 RDD.persist()让 Spark 把这个 RDD 缓存下来,后续的查询能够重用RDD,这极大地提升了查询速度,减少资源消耗
【2】RDD的属性
① 一组分区(Partition):即数据集的基本组成单位。对于RDD来说,每个分区都会被一个计算任务(Task)处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分区个数,如果没有指定,那么就会采用默认值
② 一个计算每个分区的函数:Spark中RDD的计算是以分区为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果
③ RDD之间的依赖关系(血缘关系):RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算
④ 一个Partitioner,即RDD的分区函数:当前Spark中实现了两种类型的分区函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分区数量,也决定了parent RDD Shuffle输出时的分区数量
⑤ 一个列表,存储存取每个Partition的优先位置(preferred location):对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置
【3】RDD弹性
① 自动进行内存和磁盘数据存储的切换:
Spark优先把数据放到内存中,如果内存放不下,就会放到磁盘里面,程序进行自动的存储切换
② 基于血统的高效容错机制
在RDD进行转换和动作的时候,会形成RDD的Lineage依赖链,当某一个RDD失效的时候,可以通过重新计算上游的RDD来重新生成丢失的RDD数据
③ Task如果失败会自动进行特定次数的重试
RDD的计算任务如果运行失败,会自动进行任务的重新计算,默认次数是4次
④ Stage如果失败会自动进行特定次数的重试
如果Job的某个Stage阶段计算失败,框架也会自动进行任务的重新计算,默认次数也是4次
⑤ Checkpoint和Persist可主动或被动触发
RDD可以通过Persist持久化将RDD缓存到内存或者磁盘,当再次用到该RDD时直接读取就行。也可以将RDD进行检查点,检查点会将数据存储在HDFS中,该RDD的所有父RDD依赖都会被移除
⑥ 数据调度弹性
Spark把这个Job执行模型抽象为通用的有向无环图DAG,可以将多Stage的任务串联或并行执行,调度引擎自动处理Stage的失败以及Task的失败
⑦ 数据分区的高度弹性
可以根据业务的特征,动态调整数据分区的个数,提升整体的应用执行效率
【4】RDD特点
① 分区
RDD逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过compute函数得到每个分区的数据
② 只读
RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD
③ 依赖
RDDs通过操作算子进行转换,转换得到的新RDD包含了从其他RDDs衍生所必需的信息,RDDs之间维护着这种血缘关系,也称之为依赖
④ 缓存
如果多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据,在后续用到该RDD的时候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用
⑤ checkpoint
RDD支持checkpoint将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为checkpoint后的RDD不需要知道它的父RDDs了,它可以从checkpoint处获取数据
【5】RDD操作
RDD将操作分为两类:transformation与action
无论执行了多少次transformation操作,RDD都不会真正执行运算,只有当action操作被执行时,计算才会触发。而在RDD的内部实现机制中,底层接口则是基于迭代器的,从而使得数据访问变得更高效,也避免了大量中间结果对内存的消耗
二、RDD持久化、检查点
【1】RDD的缓存
Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或缓存个数据集。当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此RDD或衍生出的RDD进行的其他动作中重用。这使得后续的动作变得更加迅速。RDD相关的持久化和缓存,是Spark最重要的特征之一。可以说,缓存是Spark构建迭代式算法和快速交互式查询的关键。如果一个有持久化数据的节点发生故障,Spark 会在需要用到缓存的数据时重算丢失的数据分区。如果希望节点故障的情况不会拖累我们的执行速度,也可以把数据备份到多个节点上
【2】RDD缓存方式
RDD通过persist方法或cache方法可以将前面的计算结果缓存,默认情况下 persist() 会把数据以序列化的形式缓存在 JVM 的堆空间中
但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用

过查看源码发现cache最终也是调用了persist方法,默认的存储级别都是仅在内存存储一份,Spark的存储级别还有好多种,存储级别在object StorageLevel伴生对象中定义的


在存储级别的末尾加上"_2"来把持久化数据存为两份
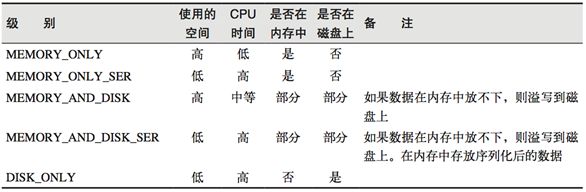
缓存有可能丢失,或者存储存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition
注意:使用 Tachyon 可以实现堆外缓存
【3】RDD检查点(checkpoint)机制
Spark中对于数据的保存除了持久化操作之外,还提供了一种检查点的机制,检查点(本质是通过将RDD写入Disk做检查点)是为了通过lineage做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。检查点通过将数据写入到HDFS文件系统实现了RDD的检查点功能。
cache 和 checkpoint 是有显著区别的,缓存把 RDD 计算出来然后放在内存中,但是RDD 的依赖链(血缘关系)也不会删除, 当某个点某个 executor 宕机了,上面 cache 的RDD就会失效, 需要通过依赖链重新计算出来; 不同的是, checkpoint 是把 RDD 保存在 HDFS中, 是多副本可靠存储,所以就可以切断依赖链, 是通过复制实现的高容错
如果存在以下场景,则比较适合使用检查点机制:
- 1)DAG中的
Lineage过长,如果重算,则开销太大(例如在PageRank中) - 2)在
宽依赖上做Checkpoint获得的收益更大
为当前RDD设置检查点,该函数将会创建一个二进制的文件,并存储到checkpoint目录中,该目录是用SparkContext.setCheckpointDir()设置的,在checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移出。对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发
【3】checkpoint写流程
RDD checkpoint 过程中会经过以下几个状态
[ Initialized → marked for checkpointing → checkpointing in progress → checkpointed ]
转换流程如下:

- 1)
data.checkpoint这个函数调用中,设置的目录中,所有依赖的 RDD 都会被删除, 函数必须在job 运行之前调用执行, 强烈建议RDD缓存在内存中, 否则保存到文件的时候需要从头计算。初始化RDD的 checkpointData变量为ReliableRDDCheckpointData。 这时候标记为Initialized状态 - 2)在所有
job action的时候,runJob方法中都会调用rdd.doCheckpoint, 这个会向前递归调用所有的依赖的RDD, 看看需不需要 checkpoint,如果需要 checkpoint, 然后调用checkpointData.get.checkpoint(), 里面标记状态为CheckpointingInProgress, 里面调用具体实现类的ReliableRDDCheckpointData 的 doCheckpoint 方法 - 3)
doCheckpoint->writeRDDToCheckpointDirectory, 注意这里会把 job 再运行一次, 如果已经cache了,就可以直接使用缓存中的 RDD了, 就不需要重头计算一遍了, 这时候直接把RDD输出到HDFS,每个分区一个文件,会先写到一个临时文件,如果全部输出完,进行 rename,如果输出失败,就回滚delete - 4)
标记状态为Checkpointed,markCheckpointed方法中清除所有的依赖,把RDD变量的强引用设置为null, 触发ContextCleaner里面监听清除实际BlockManager 缓存中的数据
【4】checkpoint 读流程
提问:如果一个RDD 我们已经 checkpoint了那么是什么时候用呢?
checkpoint 将 RDD 持久化到 HDFS 或本地文件夹,如果不被手动 remove 掉,是一直存在的,也就是说可以被下一个 driver program 使用。 比如 spark streaming 挂掉了, 重启后就可以使用之前 checkpoint 的数据进行 recover ,当然在同一个 driver program 也可以使用
如果一个RDD被checkpoint了, 并且这个 RDD 上有 action 操作时候,或者回溯的这个 RDD 的时候,这个 RDD 进行计算的时候,里面判断如果已经 checkpoint 过, 对分区和依赖的处理都是使用的 RDD 内部的 checkpointRDD 变量,具体实现是 ReliableCheckpointRDD 类型。 这个是在 checkpoint 写流程中创建的,依赖和获取分区方法中先判断是否已经checkpoint, 如果已经checkpoint了,就切断依赖,使用ReliableCheckpointRDD, 来处理依赖和获取分区
如果没有,才往前回溯依赖,依赖就是没有依赖, 因为已经斩断了依赖, 获取分区数据就是读取 checkpoint 到 hdfs目录中不同分区保存下来的文件
【5】 总结
1、开发中如何保证数据的安全性性及读取效率?
可以对频繁使用且重要的数据,先做缓存/持久化,再做checkpoint操作
2、持久化和Checkpoint的区别
1)位置
Persist 和 Cache 只能保存在本地的磁盘和内存中(或者堆外内存–实验中)
Checkpoint 可以保存数据到 HDFS 这类可靠的存储上
2)生命周期
Cache和Persist的RDD会在程序结束后会被自动删除或者手动调用unpersist方法删除
Checkpoint的RDD在程序结束后依然存在,不会被自动删除,需要手动删除
3)Lineage(血统、依赖链--其实就是依赖关系)
Persist和Cache,不会丢掉RDD间的依赖链/依赖关系,因为这种缓存是不可靠的,如果出现了一些错误(例如 Executor 宕机),需要通过回溯依赖链重新计算出来
Checkpoint会切断依赖链,因为Checkpoint会把结果保存在HDFS这类存储中,更加的安全可靠,出现错误直接从checkpoint中读取即可,一般不需要回溯依赖链
4)Lineage
RDD的Lineage(血统、依赖链)会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
在进行故障恢复时,Spark会对读取Checkpoint的开销和重新计算RDD分区的开销进行比较,从而自动选择最优的恢复策略