前面我们准备好了所有的软件硬件,现在是时候开始正在的业务逻辑功能的实现了。
语音数据的格式
语音遥控器走的是BLE, 对于Voice Over BLE有多种方案,不同的厂家和方案商都不同的实现。下面我们使用TI的来说明,其他的也是类似的。
这里面主要是说明了各种格式,以及传递协议。 我们需要接受和decoder语音,那么就需要搞明白这些东西。
具体而言,语音的Profile如下:

交互过程如下:
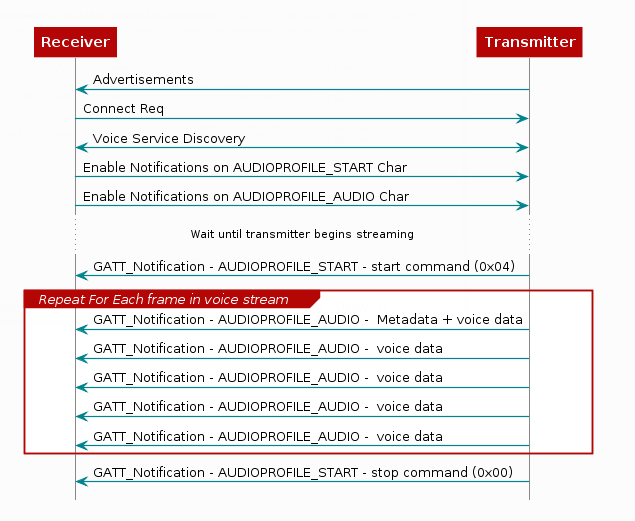
注意第一包语音数据有头部:
语音数据从Gatt Notification中获取过来,我们先说一下这个压缩后的语音格式ADPCM。
具体可以参考:
简单而言,使用的是差分压缩:

下面是ADPCM的压缩与解压图:
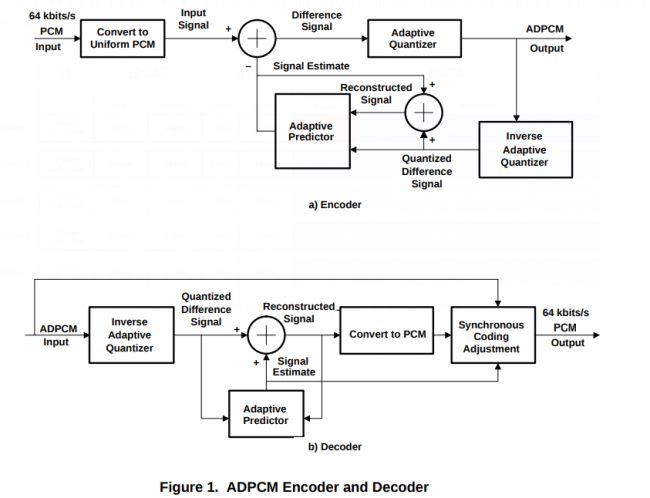
解压后我们得到的是PCM audio data, 格式为PCM S16_LE, 16Kps的采样率。 adpcm到pcm的解压函数可以参考:https://github.com/dbry/adpcm-xq/blob/master/adpcm-xq.c
BlueZ的D-Bus API的使用 前面是假设得到了ADPCM数据后的解压代码, 我们还需用对前面指定的Characteristic进行notification enable与获取数据。
这些需要借助BlueZ的功能, BlueZ将控制与交互使用D-Bus暴露出来。
具体的文档位于 bluez/doc下面。例如对于我们需要使用的gatt api就在文件gatt-api.txt中。对应的代码可以参考gatttool.c,例如我们需要的notification就在下面这个event中处理:

参考这个代码,我们可以完成notification data的获取。PCM用于语音识别获取了PCM数据后,我们可以将PCM convert 到wav 文件,这个比较容易,直接加头部即可。代码如下:
unsigned char RiffHeader[] = {
'R' , 'I' , 'F' , 'F' , // Chunk ID (RIFF)
0x70, 0x70, 0x70, 0x70, // Chunk payload size (calculate after rec!)
'W' , 'A' , 'V' , 'E' , // RIFF resource format type
'f' , 'm' , 't' , ' ' , // Chunk ID (fmt )
0x10, 0x00, 0x00, 0x00, // Chunk payload size (0x14 = 20 bytes)
0x01, 0x00, // Format Tag ()
0x01, 0x00, // Channels (1)
0x80, 0x3e, 0x00, 0x00, // Byte rate 32.0K
//0x40, 0x1f, 0x00, 0x00, // Sample Rate, = 8.0kHz
0x00, 0x7d, 0x00, 0x00, // Sample Rate, = 16.0kHz
0x02, 0x00, // BlockAlign == NumChannels * BitsPerSample/8
0x10, 0x00 // BitsPerSample PCM_16
};
unsigned char RIFFHeader504[] = {
'd' , 'a' , 't' , 'a' , // Chunk ID (data)
0x70, 0x70, 0x70, 0x70 // Chunk payload size (calculate after rec!)
};
void pcm2wav(const char *pcm_file, const char *wav_file) {
FILE *fpi,*fpo;
unsigned long iLen,temp;
unsigned long i = 0;
unsigned long j;
int headflag = -1;
fpi=fopen(pcm_file,"rb");
if(fpi==NULL) {
printf("\nread error!\n");
printf("\n%ld\n",i);
exit(0);
}
fseek(fpi,0,SEEK_END);
temp = ftell(fpi);
printf("temp:%lu\n", temp);
fpo=fopen(wav_file,"w+");
if(fpo==NULL) {
printf("\nwrite error!\n");
exit(0);
}
fseek(fpo,0,SEEK_SET);
fwrite(RiffHeader,sizeof(RiffHeader),1,fpo);
fwrite(RIFFHeader504,sizeof(RIFFHeader504),1,fpo);
fseek(fpi,0,SEEK_SET);
fread(savedata,1,temp,fpi);
fwrite(savedata,temp,1,fpo);
// ChunkSize
RiffHeader[4] = (unsigned char)((36 + temp)&0x000000ff);
RiffHeader[5] = (unsigned char)(((36 + temp)&0x0000ff00)>>8);
RiffHeader[6] = (unsigned char)(((36 + temp)&0x00ff0000)>>16);
RiffHeader[7] = (unsigned char)(((36 + temp)&0xff000000)>>24);
fseek(fpo,4,SEEK_SET);
fwrite(&RiffHeader[4],4,1,fpo);
RIFFHeader504[4] = (unsigned char)(temp&0x000000ff);
RIFFHeader504[5] = (unsigned char)((temp&0x0000ff00)>>8);
RIFFHeader504[6] = (unsigned char)((temp&0x00ff0000)>>16);
RIFFHeader504[7] = (unsigned char)((temp&0xff000000)>>24);
fseek(fpo,40,SEEK_SET);
fwrite(&RIFFHeader504[4],4,1,fpo);
fclose(fpi);
fclose(fpo);
从语音到文字
得到了wav文件后,我们需要做的就是使用百度语音识别来做语音识别了。前面的文章中,我们已经下载了sdk, 然后我们找到对应的Rest API 文档:
了解其调用流程:
设置key --> 填充json数据(包括格式,length, language, wav文件) --> post出去 --> 得到识别结果。
下面是百度识别核心的代码:
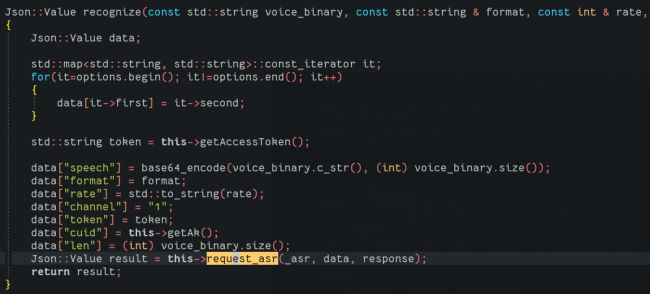
我们需要做的是将wav文件和格式等各种参数填入到JSON中,然后post出去。
然后我们会得到results,这个result为response为string:
Json::Value result = this->request_asr(_asr, data, response);
需要注意的是我们需要设置语言,以及格式,下面是英语识别的相关代码:
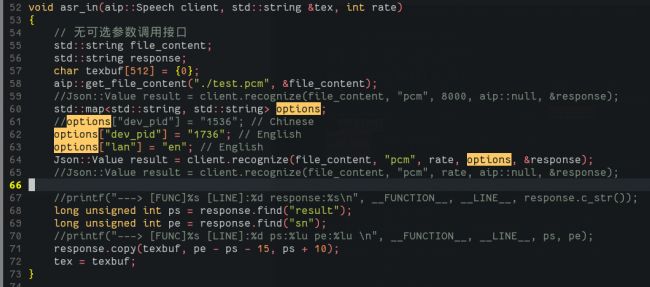
重新编译libbaidu_voice, 我们做一个测试,得到的结果如下, 和我们说话符合:

从文字到交互控制
得到result string后,我们就可以用来做控制了。简单的控制,我们可以对string中的字符做判断来处理。
类似于:
if (string.contains(substring) ) {
do xxxx
} else if(string.contains(substring2) ) {
do YYYYY
}
MYdev板子上面有一个LED:

这个LED的sys 控制interface位于:
/sys/devices/platform/leds/leds/cpu/brightness
例如echo 0过去就可以将其关闭,1可以将其turn on:
echo 0 > /sys/devices/platform/leds/leds/cpu/brightness
因此我们可以使用这个LED作为被控制的对象来集合进语音控制部分:
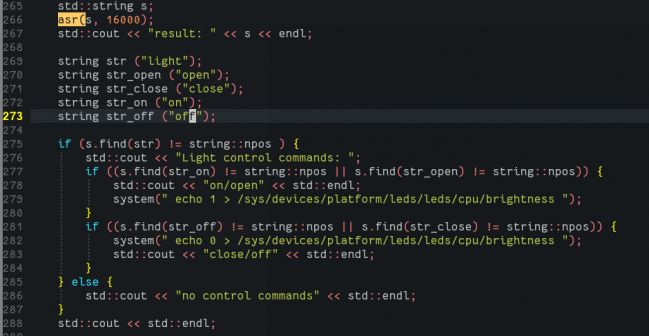
编译运行并测试:
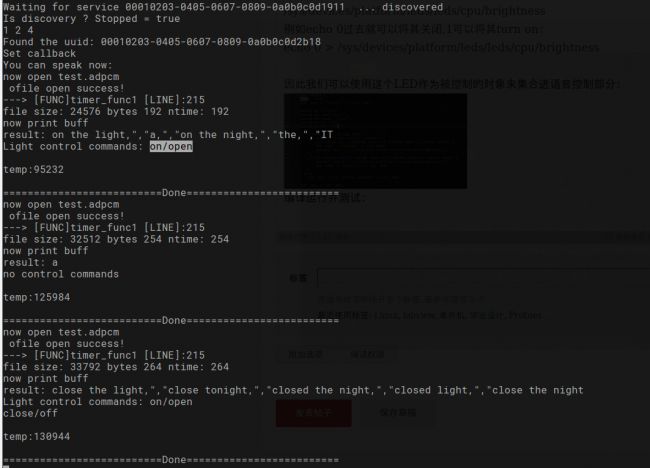
可以看到我们已经可以控制LED的ON OFF, 其他复杂的控制也是类似的。下面是实际测试效果的视频:
http://v.youku.com/v_show/id_XMzUxMTIyNzYzNg==.html?x&sharefrom=android&sharekey=a861aa19b6c632d4aab08ff4889359d37
另外,实际上我们还可以添加语音合成,对结果进行播放提醒,还可以添加网络远程控制。 |