早期(编译期)优化
该文章中的部分内容摘自于周志明版的《深入理解Java虚拟机》
一、概述
从计算机程序出现的第一天起,对效率的追逐就是程序员天生的信仰。
在Java语言中运行一个Java程序,包括:
- 编译期:使用编译器如javac把*.java文件转换成*.class文件的过程;
- 运行期:使用虚拟机的运行期编译器(JIT编译器,Just In Time Compiler)如HotSpot VM的C1、C2编译器把*.class文件转换成机器码的过程(猜想:使用java *.class命令后最终调用的就是根据Java虚拟机规范而具体实现的不同厂商自带的编译器);
在编译期,javac这类编译器对代码的运行效率几乎没有任何优化措施。虚拟机设计团队把对性能的优化集中到了运行期,这样就可以让那些不是由javac产生的*.class文件(如Groovy语言的*.class文件)也同样能享受到编译期优化所带来的的好处。但是javac做了许多针对编码过程的优化措施来改善程序员的编写风格和提高编码效率。总结:运行期的编译器的优化过程对程序运行来说更重要,而编译期的编译器的优化过程对于程序编码来说关系更加密切。
二、编译期过程
编译期的过程大致可以分为三个过程,分别是:
- 解析与填充符号表过程
- 插入式注解处理器的注解处理过程
- 语义分析与字节码生成过程
而第3个过程的语义分析包括:标注检查、数据及控制流分析、解语法糖;
1、语法糖
什么是语法糖呢?语法糖是指在计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。它的作用是增加程序的可读性,从而减少程序代码出错的机会。Java中常见的语法糖包括:泛型、自动装箱拆箱、变长参数、枚举等。由于虚拟机运行时不支持这些语法,它们在编译阶段被还原回简单地基础语法结构,这个过程称为解语法糖。下面分别对这三个语法糖进行简单解释:
1)、泛型
一般的类和方法,只用使用具体的类型:要么是基本类型,要么是引用类型。如果要编写可以应用于多种类型的代码,有两种方案:
a、将参数类型设为基类,那么该方法就可以接受从这个基类导出的任何类作为参数。但缺点是Java只支持单继承,局限性较大。
b、为了解决局限性问题,可以将方法的参数设为一个接口,那么该方法就可以接受任何实现了该接口的类都可以参数。但其也有缺点,因为一旦指明了接口,它就要求你的代码必须使用特定的接口。
有许多原因促成了泛型的出现,而最重要的一个原因,就是为了创造容器类。容器,就是存放要使用的对象的地方。数组也是如此,不过它不能动态扩容。
我们先来看看一个只能持有单个对象的类。当然了,这个类可以明确指定其持有的对象的类型:
public class Holder {
private Bean bean;
public Holder(Bean bean) {
this.bean = bean;
}
public Bean getBean() {
return bean;
}
public void setBean(Bean bean) {
this.bean = bean;
}
}
class Bean {
}不过,这个类的可重用性就不怎么样了,它无法持有其他类型的任何对象。为了优化,可以让这个类直接持有Object类型的对象:
public class Holder {
private Object o;
public Holder(Object o) {
this.o = o;
}
public Object get() {
return o;
}
public void set(Object o) {
this.o = o;
}
public static void main(String[] args) {
Holder h = new Holder(1);
int i = (int) h.get();
h.set("a");
String s = (String) h.get();
}
}现在Holder就可以存储任何类型的对象了。
有些情况下,我们确实希望容器能够同时持有多种类型的对象。但是,通常而言,我们只会使用容器来存储一种类型的对象。泛型的主要目的之一就是用来指定容器要持有什么类型的对象,而且由编译器来保证类型的正确性。
因此,与其使用Object,我们更喜欢暂时不指定类型,而是稍后再决定使用什么类型。要达到这个目的,我们需要使用类型参数,用尖括号括住,放在类名后面。然后在使用这个类的时候,再用实际的类型替换此类型参数。在下面的例子中,T就是类型参数:
public class Holder {
private T value;
public Holder(T value) {
this.value = value;
}
public T get() {
return value;
}
public void set(T value) {
this.value = value;
}
public static void main(String[] args) {
Holder h = new Holder<>("a");
String s = h.get();//不用强制转换
h.set(1);//报错
}
} 需要注意的是,对如上代码进行反编译的结果会令人感到吃惊,它的最终实现原理也是将T类型转换成Object类型,然后由编译器保证类型的正确性
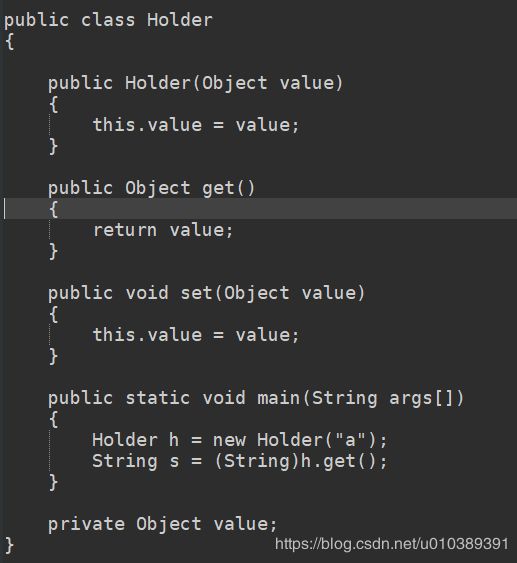
以上就是泛型的使用方式,在Java SE5中提供,泛型的本质是参数化类型(Parameterized Type)的应用,也就是说所操作的数据类型被指定为一个参数。这种参数可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口和泛型方法。
泛型技术在C#和Java之中的实用方式看似相同,但实现上却有着根本性的分歧,C#里面泛型在编译期和运行期都是切实存在的,List
下面是一段简单地Java泛型例子,看一下它编译后的结果是怎样的?
public static void main(String[] args) {
Map map = new HashMap<>();
map.put("key1","hello");
map.put("key2","world");
System.out.println(map.get("key1"));
System.out.println(map.get("key2"));
}
把这段Java代码编译成字节码文件,然后再用字节码反编译工件进行反编译后,将会发现泛型都不见了
public static void main(String args[])
{
Map map = new HashMap();
map.put("key1", "hello");
map.put("key2", "world");
System.out.println((String)map.get("key1"));
System.out.println((String)map.get("key2"));
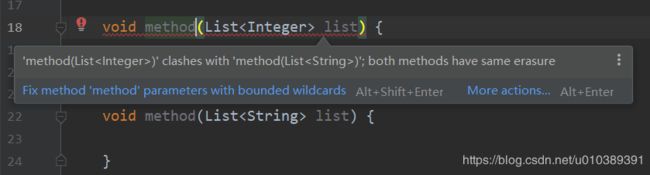
}同样,如下代码也是无法编译的,因为List
2)、自动装箱拆箱
首先解释一下什么是装箱和拆箱,我们都知道,Java中有八种基本数据类型:char、boolean、byte、short、int、long、float、double。Java语言是一个面向对象的语言,但是Java中的基本数据类型却不是面向对象的,这在实际使用时存在很多的不便,为了解决这个不足,在设计类时为每个基本数据类型设计了一个对应的类进行代表,这样的类统称为包装类(Wrapper Class)。基本数据类型和包装类的对应关系如下表所示
| 基本数据类型 | 包装类 |
| char |
Character |
| boolean | Boolean |
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
那么,有了基本数据类型和包装类,当需要在他们之间进行转换时,比如把一个基本数据类型的int转换成一个包装类型的Integer对象,把基本数据类型转换成包装类的过程就是打包装,英文对应于boxing,中文翻译为装箱。反之,把包装类转换成基本数据类型的过程就是拆包装,英文对应于unboxing,中文翻译为拆箱。
在Java SE5之前,要进行装箱,可以通过以下代码:
Integer i = new Integer(1);
在Java SE5中,为了减少开发人员的工作,Java提供了自动拆箱与自动装箱功能。
自动装箱: 就是将基本数据类型自动转换成对应的包装类。
自动拆箱:就是将包装类自动转换成对应的基本数据类型。
Integer i =1; //自动装箱
int j= i; //自动拆箱既然Java提供了自动拆装箱的能力,那么,我们就来看一下,到底是什么原理,Java是如何实现的自动拆装箱功能。
我们有以下自动拆装箱的代码:
public static void main(String[] args) {
Integer i= 1;
int j = i;
}
对以上代码进行反编译后可以得到如下代码:
public static void main(String args[])
{
Integer i = Integer.valueOf(1);
int j = i.intValue();
}可以看出,int的自动装箱都是通过Integer.valueOf()方法来实现的,Integer的自动拆箱都是通过integer.intValue来实现的,以上两个方法的源码如下:


3)、变长参数
在Java SE5中提供了变长参数(varargs),用...表示,也就是在方法定义中可以使用个数不确定的参数,对于同一方法可以使用不同个数的参数调用。例如有如下变长参数的方法,可以有多种调用方式: method("1");method("1","2")等
static void method(String... args) {
System.out.println(args.length);
}
public static void main(String[] args) {
method("1");
method("1","2");
}
反编译后的结果如下,可以看出参数类型变成了数组:
static transient void method(String as[])
{
}
public static void main(String args[])
{
method(new String[] {
"1"
});
method(new String[] {
"1", "2"
});
}
4)、foreach循环
在Java SE5中提供了foreach循环,也叫增强型的for循环,看如下代码:
public static void main(String[] args) {
List list = Arrays.asList(1,2,3);
for (Integer i : list) {
System.out.println(i);
}
} 反编译后的结果如下:
public static void main(String args[])
{
List list = Arrays.asList(new Integer[] {
Integer.valueOf(1), Integer.valueOf(2), Integer.valueOf(3)
});
Integer i;
for(Iterator iterator = list.iterator(); iterator.hasNext(); System.out.println(i))
i = (Integer)iterator.next();
}可以看出使用了迭代器,这也是为何遍历循环需要被遍历的类实现Iterable接口的原因
2、字节码生成
字节码生成阶段是编译期的最后一个过程,该阶段不仅仅是把前面各个步骤所生成的信息(语法树,符号表)转换成字节码写到磁盘中,编译期还进行了不少的代码添加和转换工作,例如实例构造器
public class OuterClass {
private int m = 1;
private class InnerClass {
private int n = 2;
}
}通过jad反编译后的结果:
public class OuterClass
{
private class InnerClass
{
private int n;
final OuterClass this$0;
private InnerClass()
{
this$0 = OuterClass.this;
super();
n = 2;
}
}
public OuterClass()
{
m = 1;
}
private int m;
}可以看出,外部类自动生成了一个用public修饰的构造方法,内部类的构造方法则是private,并且都将成员变量的赋值操作放在了构造方法中。
除了生成构造器以外,还有其他的一些代码替换工作用于优化程序的实现逻辑,如把字符串的加操作替换成StringBuilder的append操作等,如下:
public class StringAddTest {
public static void main(String[] args) {
String s1 = "a";
String s2 = "b";
String s3 = s1 + s2;
}
}反编译后的结果
public class StringAddTest
{
public StringAddTest()
{
}
public static void main(String args[])
{
String s1 = "a";
String s2 = "b";
String s3 = (new StringBuilder()).append(s1).append(s2).toString();
}
}