智能计算系统(学习笔记)-第四章编程框架使用
课程链接:智能计算系统第四章
第四章编程框架使用
- 深度学习编程框架的概念
- TensorFlow概述
- TensorFlow编程模型及基本用法
- TensorFlow的几个基本概念
- 计算图
- 操作
- 张量(tensor)
- tensor中支持的dtype类型
- tensor 的shape 属性
- tensor 的device属性
- tensor的常用操作op命令
- tensor的打印
- 会话(session)
- 创建会话(sess=tf.Session())
- 执行会话(sess.run())
- 关闭会话(sess.close())
- 求解张量值的方法
- 变量(variable)
- 创建变量
- 初始化变量
- 更新变量
- 占位符(placeholder)
- 队列(Queue)
- FIFOQueue
- 小结
- 基于TensorFlow的训练及预测实现
- 训练部分[构建模型-损失函数-优化器]
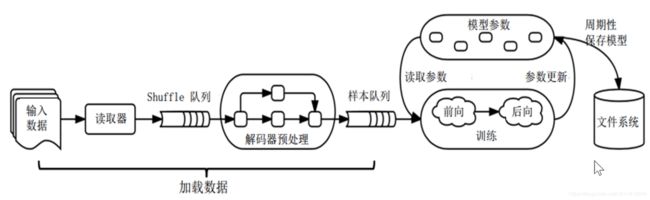
- 加载数据
- 注入feeding:利用feed_dict直接传递输入数据
- 预取pre_load:利用Const和Variable直接读取输入数据
- 基于队列API:基于队列相关的API来构建输入流水线Pipeline
- 主要组成
- 一个典型的输入结构
- 数据的批量处理
- tf.data API:利用tf.data API来构建输入流水线
- 定义损失函数|训练时
- 自定义损失函数
- TensorFlow内置的4个损失函数
- SoftMax交叉熵
- 加了稀疏的SoftMax交叉熵
- sigmoid交叉熵
- 带权重的sigmoid交叉熵
- 创建优化器|训练时
- 定义模型训练方法|训练时
- 最小化损失函数minimize
- 对梯度的处理
- 模型保存|训练时
- 恢复模型
- 预测部分[读取样本-运算单元-神经网络结构]
- 读取输入样本
- 定义基本运算单元
- tf.nn模块简介
- 创建神经网络结构
- 计算模型输出
- 小结
- 总结
导读:
编程框架在整个智能计算系统中起着承上启下的作用,在某种意义上像信息产业里的操作系统,是智能计算系统中非常关键的核心枢纽。
本章首先介绍深度学习编程框架的概念及作用,随后介绍目前应用最广的编程框架 TensorFlow 的基本概念及编程模型,最后通过程序示例来介绍如何基于 TensorFlow 实现 深度学习的预测和训练。
主要是在实现部分:学习到实现深度学习算法所需要的编程框架的简单用法
深度学习编程框架的概念
- 深度学习的广泛使用
- 为什么需要编程框架?
- 算法理论复杂
- 代码实现工作量大
- 深度学习的结果具有模糊性
- 深度学习算法具有多层结构,每层的运算有一些基本操作构成。
- 这些基本操作中存在大量共性运算,如卷积,池化,激活等。将这些共性运算操作封装起来,可以提高编程实现效率。
- 面向这些封装起来的操作,硬件程序员可以基于硬件特征,有针对性的进行充分优化,使其能充分发挥硬件的效率。
- 定义
- 随着深度学习研究的深入,深度学习算法变得愈加复杂,研究人员需要花更多的时间和精力在算法的实现上。
- 深度学习编程框架:将深度学习算法中的基本操作封装成一系列组件,这一系列深度学习组件,即构成一套深度学习框架。
- 编程框架能够帮助算法开发人员更简单的实现已有算法,或设计新的算法。也有助于硬件程序员更有针对性的对关键操作进行优化,使其能充分发挥硬件效率。
| 主流深度学习编程框架 | 支持语言 |
|---|---|
| TensorFlow | Python/C/C++/Java/Go |
| caffe2 | Python/C++ |
| Pytorch | Python |
| Keras | Python |
| cognitive Toolkit | Python/C++/C# |
| MXNet | Python/C++/R/Scala/Julia |
TensorFlow受Google推动,是目前使用人数最多,影响最大的编程框架。应用:AlphaGo
TensorFlow概述
TensorFlow及其变种可以工作于各种类型的异构系统,包括手机,平板电脑等移动设备,数百台机器和数千种计算设备(如GPU)的大规模分布式系统。
-
第1代分布式深度学习平台—DistBelief
- 研究了包括无监督学习,图像分类,视频分类,语音识别,序列预测,行人检测,强化学习等
- 将Google语音识别率提高25%,在Google photos中建立了图片搜索,并驱动了Google的图片字幕匹配实验
- 著名的“猫脸识别”实验-自我学习
- 仅可用于神经网络,且和Google内部基础产品联系紧密,在实际配置和应用中存在局限性
-
第2代大规模机器学习系统—TensorFlow
- 支持多种高级语言作为输入
- 更灵活的编程模型
- 更高的性能支持
- 在更广泛的异构硬件平台上进行训练和使用更大规模的神经网络模型
- 应用:Gmail,Play Recommendation,Search,Translate,Map,AlphaGo,TPU2.0/3.0,IBM PowerAI ,Inter Movidius Myriad , 寒武纪MLU100/270
-
版本历史
| 时间 | 版本号 | 更新内容 |
|---|---|---|
| 2015.11 | 0.5 | 第1个发布版本 |
| 2016.04 | 0.8 | 支持分布式计算,支持大规模智能应用的部署使用。 |
| 2016.06 | 0.9 | 增加了对多平台的支持,包括IOS,Raspberry Pi等 |
| 2016.09 | 0.10 | 提供深度学习高级抽象库TensorFlow-Slim,方便快速定义和训练模型,有效扩大了用户群体。 |
| 2017.02 | 1.0 | 第1个正式版。增加了多个提升性能及易用性的更新,包括线性代数编译器XLA,调试工具TensorFlow Debugger,对安卓的支持等。 |
| 2017.07 | 1.2 | 增加了面向infiniBand等高性能网络的RDMA通信方案,解决了分布式训练时通信开销过大的问题。 |
| 2018.03 | 1.7 | 推出TensorBoard可视化工具,有效辅助用户理解算法模型及工作流程。 |
| 2020.01 | 2.1 | 目前的最新版本,支持静态/动态图 |
TensorFlow编程模型及基本用法
- 命令式编程与声明式编程
- 命令式编程:关注程序执行的具体步骤,计算机按照代码中的顺序一步一步执行具体的运算,整体优化困难。
比如:交互式UI程序,操作系统。 - 声明式编程:告诉计算机想要达到的目标,不指定具体的实现步骤,而是通过函数,推论规则的描述数据之间的关系,优化较容易。
比如:人工智能,深度学习
- 命令式编程:关注程序执行的具体步骤,计算机按照代码中的顺序一步一步执行具体的运算,整体优化困难。
TensorFlow的几个基本概念
计算图
import tensorflow as tf
- 使用有向图来描述计算过程,有向图中包含一组节点和边。例如:y=w*x------>“ * ”需要对应一个节点
- 节点一般用来表示各类操作,包括数学运算,变量读写,数据填充等,也可以表示输入数据,模型参数,输出数据。
- 边表示节点之间的输入输出关系,分为两类:
- 一类是传递具体数据的边。传递的数据就是张量
- 一类是表示节点之间控制依赖关系的边。这类边不传递数据,只是表示节点执行的顺序:必须前序节点计算完成,后序节点才开始计算。
- 支持通过多种高级语言来构建计算图(C++/Python举例)
构建计算图
X=tf.constant([[3.,3.]])
W=tf.constant([[2.],[2.]])
y=tf.matnul(X,W)
执行计算图,创建会话,执行运算。
with tf.Session() as sess:
result=sess.run(y)
print(result)
- 计算图对应了神经网络的结构。
- TensorFlow 1.x:静态图,方便对整个计算图做全局优化,性能较高,但调试困难,影响开发效率。
- TensorFlow 2.x:动态图,调试简单,更适合快速开发,但运行效率低于静态图方法。
操作
- 计算图中的每个计算节点就代表一个操作operation,其接收0个或多个tensor作为输入产生0个或多个tensor作为输出。
- 操作对应了神经网络中的具体计算。
- 操作的主要属性
| 属性名 | 功能说明 |
|---|---|
| tf.operation.name | 操作的名称 |
| tf.operation.type | 操作的类型, 如add |
| tf.operation.inputs | 操作的输入 |
| tf.operation.outputs | 操作的输出 |
| tf.operation.control_inputs | 该操作的控制依赖列表 |
| tf.operation.device | 执行该操作所使用的设备 |
| tf.operation.graph | 操作所属的计算图 |
| tf.operation.traceback | 实例化该操作时的调用栈 |
- TensorFlow中的常用的操作
| 操作类型 | 常用算子 |
|---|---|
| 标量运算 | add,subtract,multiply,div,greater,less,equal,abs,sign,square,pow,log,sin,cos |
| 矩阵运算 | matmul,matrix_inverse,matrix_determinant,matrix_transpose |
| 逻辑操作 | logical_and,is_finite |
| 神经网络运算 | convolution,max_pool,bias_add,softmax,dropout,sigmoid,relu |
| 储存,恢复 | save,restore |
| 初始化操作 | zeros_initializer,random_normal_initializer,orthogonal_initializer |
| 随机运算 | random_gamma,multinomial,random_normal,random_shuffle |
张量(tensor)
- 张量是计算图上的数据载体,用张量统一表示所有的数据,张量在计算图的节点之间传递。
| tensor的常见属性名 | 含义 |
|---|---|
| dtype | tensor存储的数据类型 |
| shape | tensor各阶的长度 |
| name | tensor在计算图中的名称 |
| op | 计算出此tensor的操作 |
| device | 计算出此tensor所用的设备名 |
| graph | 包含此tensor的计算图 |
- 张量中没有实际保存数据,而仅是对计算结果的引用,对应了神经网络中各个节点之间流动的数据。
- 张量可以看作是n维的数组,数组的维数就是张量的阶数。
例如:一张RGB图片可以表示为三阶张量,多张图片组成的数据集可以表示成是接张量。
| 阶数 | 对应的数据形式 |
|---|---|
| 0 | 标量 |
| 1 | 向量 |
| 2 | 矩阵 |
| n | n维数组 |
tensor中支持的dtype类型
| TensorFlow数据类型 | 说明 |
|---|---|
| int8/int16/int32/int64 | 8/16/32/64位有符号整数 |
| float16/float32/float64 | 半精度/单精度/双精度浮点数 |
| bfloat16 | 裁短浮点数 |
| uint8/uint16/uint32/uint64 | 8/16/32/64位无符号整数 |
| bool | 布尔值 |
| string | 字符串 |
| complex64/complex128 | 单精度/双精度复数 |
| qint8/qint16/qint32 | 量化的8位/16位/32位有符号整数 |
| quint8/quint16 | 量化的8位/16位无符号整数 |
例如:X=tf.constant([2,3],dtype=tf.float32)
深度学习不需要全部float32,容忍非精确计算(不同类别的大间距现象)
- 数据位宽与算法精度[不同数据的位宽需求是不同的]
- 每层数据都有其保持网络收敛的最低位宽需求
- 每层数据的位宽需求与数据分布之间存在关系
- 训练时不需要高位宽
- CNN网络,分类,检测,分割任务下的低位宽训练
- 实验中:神经元和权值自适应8bit,梯度8~16bit,可以保证Acc精度无损。
tensor 的shape 属性
- 表示tensot每一阶的长度
tensor 的device属性
- tf.device(device_name)指定计算出此tensor所用的设备名。
- TensorFlow不区分CPU,所有CPU均使用/cpu:0作为设备名称
- 用/gpu:n表示第n个GPU设备(constant),用/mlu:n表示第n个深度学习处理器(“matmul”)
tensor的常用操作op命令
| 函数名称 | 功能 |
|---|---|
| tf.shape(tensor) | 返回tensor的shape值 |
| tf.to_double(x,name=“ToDouble”) | 将x转为64位浮点类型:其他类型写法类似 |
| tf.cast(x,dtype) | 将x转化为dtype类型数据 |
| tf.reshape(tensor,shape) | 修改tensor各阶的长度为shape |
| tf.slice(input,begin,size) | 从由begin指定位置开始的input中提取一个尺寸为size的切片 |
| tf.split(value,num_or_size_splits,axis) | 沿着第axis阶对value进行切割,切割成num_or_size_splits份 |
| tf.concat(values,axis) | 沿着第axis阶对value进行连接操作 |
tensor的打印
print(tensor):只会出现"名称,格式大小,数据类型“
如果需要查看张量tensor的,只需要允许会话session。
会话(session)
- TensorFlow中的计算图描述计算执行的过程,但并没有真正给输入赋值并执行计算
- 真正的神经网络计算过程需要在TensorFlow程序的session部分中定义并执行
- session为程序提供求解张量,执行操作的运行环境,将计算图转化为不同设备上的执行步骤。
创建会话(sess=tf.Session())
| 输入参数 | 功能说明 |
|---|---|
| target | 会话连接的执行引擎,认为进程内引擎。 |
| graph | 执行计算时加载的计算图。默认值为当前代码中唯一的计算图。当代码中定义多幅计算图时,使用graph指定待加载的计算图。 |
| config | 指定相关配置项,如设备数量,并行线程数,GPU配置参数等。 |
sess=tf.Session(target='',graph=None,config=None)
执行会话(sess.run())
- 基于计算图和输入数据,求解张量或执行计算。
| 输入参数 | 功能说明 |
|---|---|
| fetches | 本会话需计算的张量或操作。 |
| feed_dict | 指定会话执行时需填充的张量或操作,及对应的填充数据。 |
| options | 设置会话运行时的控制选项。 |
| run_metadata | 设置会话运行时的非张量信息输出。 |
print(sess.run(x3,feed_dict={x1:[[1,2,3],[4,5,6]],x2:[[1,2],[3,4],[5,6]]}))
关闭会话(sess.close())
- 会话的执行会占用大量硬件资源,因此会话结束时需要关闭会话,以释放这些资源。
- 关闭会话的两种方式
- 使用close语句显式关闭会话
sess.close() - 使用with语句隐式关闭会话
with块结束时,默认会加上close的功能
- 使用close语句显式关闭会话
with ef.Session() as sess:
result=sess.run(y)
print(result)
求解张量值的方法
- 使用run()函数
可以一次进行多个tensor或操作的计算。
import tensorflow as tf
a=tf.placeholder(tf.int32)
b=tf.placeholder(tf.int32)
c=tf.multiply(a,b)
with tf.Session() as sess:
print(sess.run(c,feed_dict={a:100,b:200}))
- tensor.eval()
函数使用前,均需要显示指定求解张量或操作的会话,如用with语句定义会话。每次仅能计算一个tensor。
| 输入参数 | 功能说明 |
|---|---|
| feed_dict | 指定需填充的张量或操作,及对应的填充数据。 |
| session | 指定求解此tensor或操作的会话 |
import tensorflow as tf
a=tf.constant([[1.0,2.0]])
b=tf.constant([[3.0],[4.0]])
c=tf.constant([[5.0],[6.0]])
y1=tf.matmul(a,b)
y2=tf.matmul(a,c)
with tf.Session() as sess:
y1.eval()
y2.eval()
sess.run([y1,y2])
变量(variable)
- 大多数计算中计算图被执行多次每次执行后,其中的值即被释放
- 变量是计算图中的一种有状态节点,用于在多次执行同一计算图时存储并更新指定参数,对应了机器学习和深度学习算法中的模型参数
- 作为有状态节点,其输出有输入,节点操作,节点内部已保存的状态值共同作用。{大概类似循环神经网络里的 h ( t ) h^{(t)} h(t)}
| 常用属性 | 含义 |
|---|---|
| dtype | 变量的数据类型 |
| shape | 变量的长度 |
| name | 变量在计算图中的名称 |
| op | 变量操作 |
| device | 存储此变量所用的设备名 |
| graph | 包含此变量的计算图 |
| initialized_value | 变量的初值 |
| initializer | 为变量赋值的初始化操作 |
| trainable | 是否在训练时被优化器更新 |
创建变量
将一个tensor传递给Variable()构造函数,创建时需要指定变量的形状和数据类型。
(1).使用tf.Variable()函数直接定义
(2).使用TensorFlow内置的函数来定义变量初值,可以是常量或随机值
#以标准差0.35的正态分布,初始化一个状态为[20,40]的变量。
r=tf.Variable(tf.random_normal([20,40],stddev=0.35))
#初始化一个形状为[2,3]的变量,里面的元素值全部为0。
z=tf.Variable(tf.zeros([2,3]))
(3).用其他变量的初始值来定义新变量
#创建一个随机变量
weights=tf.Variable(tf.random_normal([784,200],stddev=0.35),name="weights")
#创建一个与weights的值相同的变量
w2=tf.Variable(weights.initialized_value(),name="w2")
#创建一个值为weights2倍的变量
w_twice=tf.Variable(weights.initialized_value()*2,name="w_twice")
初始化变量
创建变量后还需要进行变量初始化。最简单的变量初始化方法:使用tf.global_variables_initializer()对所有变量初始化
sess.run(tf.global_variables_initializer())
更新变量
- 电量是计算图中的有状态节点,其输出受到输入,操作,节点内部已保存状态的共同影响。
- 变量更新可以通过优化器自动更新完成,也可以通过自定义方法强制赋值更新。
| 更新函数 | 功能说明 |
|---|---|
| tf.assign() | 【强制】更新变量的值 |
| tf.assign_add() | 【强制】加法赋值 |
| tf.assign_sub() | 【强制】减法赋值 |
| tf.train.**Optimizer | 使用多种优化方法【自动】更新参数 |
占位符(placeholder)
- 训练神经网络模型时,需要大量的样本输入,如果每个输入都用常量表示,则每个常量都需要在计算图中增加一个节点,最终的计算图会非常大。
- 计算图表达的是计算的拓扑结构,再向计算图填充数据前,计算图并没有真正执行运算。
- TensorFlow使用占位符来构建计算图中的样本输入节点,而不需要实际分配数据。
- 占位符本身没有初始值,只是在程序中分配了内存。
- 使用占位符则只会在计算图中增加一个节点,并只在执行时向其填充数据。
| tf.placeholder()的输入参数 | 功能说明 |
|---|---|
| name | 在计算图中的名字 |
| dtype | 填充数据的数据类型 |
| shape | 填充数据的shape值 |
使用时需和feed_dict参数配合,用feed_dict提交数据,进行参数传递
#因为需要重复输入x,而每建一个x就会产生一个节点,计算图的效率会低,所以使用占位符。
x=tf.placeholder(tf.float32,shape=(1,2))
#运行y时占位符填上,feed_dict为字典,变量名不可变。
y_1=sess.run(a,feed_dict={x:[[0.7,0.9]]})
队列(Queue)
- TensorFlow提供了队列机制,通过多线程将读取数据与计算数据分开
- 队列是一种有状态的操作机制,用来处理数据读取
- 为了加快训练速度,可以采用多个线程读取数据,一个线程消耗数据
- 队列操作包含了入队,出队操作
- TensorFlow提供多种队列机制,如FIFOQueue,RandomShuffleQueue
FIFOQueue
- 先进先出队列,支持入队,出队操作
- 入队操作将输入输出放到FIFOQueue队尾,出队操作将FIFOQueue队列中首个元素取出
- 当队列满时入队操作会被阻塞,当队列为空时出队操作会被阻塞。
import tensorflow as tf
#创建一个先进先出队列,指定队列中可以保存三个元素,并指定类型为浮点型
q=tf.FIFOQueue(3,'float')
#使用enqueue_many函数来初始化队列中的元素
init=q.enqueue_many(([0.,0.,0.],))
#使用Dequeue函数将队列中第1个元素出队列,这个元素值将被存在变量x中
x=q.dequeue()
y=x+1
#将+1后的值再重新加入队列中
q_inc=q.enqueue([y])
init.run()
q_inc.run()
小结
- 计算图:对应神经网络结构
- 操作:对应神经网络具体计算
- 张量:对应神经网络中的数据
- 会话:执行神经网络真正的训练和预测
- 变量:对应神经网络参数
- 占位符:对应神经网络的训练或预测输入
- 队列:对应神经网络训练样本的多线程并行计算
基于TensorFlow的训练及预测实现

用VGG_19-图像风格迁移训练实现举例【5层conv-pool】
import cv2
import numpy as np
def train_vgg():
sess=tf.Session()
#构建模型,使用与模型推理时相同的网络结构
models=build_vggnet(vgg19_npy_path)
#获取输入的内容图像,风格图像
img_content=load_image('./content,jpg')
img_style=load_image('./style.jpg')
#生成噪音图像
img_random=get_random_img(img_content)
sess.run(tf.global_variables_initializer())
#定义损失函数
total_loss=loss(sess,models,img_content,img_style)
#创建优化器
optimizer=tf.train.AdamOptimizer(2.0)
#定义模型训练方法
train_op=optimizer.minimize(total_loss)
sess.run(tf.global_variables_initializer())
#使用噪声图像进行训练
sess.run(models['input'].assign(img_random))
#训练迭代3000次
for i in range(3000):
#完成一次反向传播
sess.run(train_op)
if i%100==0:
#每完成100次训练, 打印中间结果,从而监测训练效果
img_transfer=sess.run(models['input'])
print('Iteration %d' % (i))
print('cost:',sess.run(total_loss))
#训练结束,保存训练结果,显示图像
...
if __name__ == '__main__':
train_vgg()
训练部分[构建模型-损失函数-优化器]
加载数据
注入feeding:利用feed_dict直接传递输入数据
with tf.Session():
input=tf.placeholder(tf.float32)
classifier=...
print(classifier.eval(feed_dict={input:one_numpy_ndarray}))
预取pre_load:利用Const和Variable直接读取输入数据
利用常量进行数据预取
training_data=... #some data like numpy array
training_labels=...
with tf.Session():
input_data=tf.constant(training_data)
input_labels=tf.constant(training_labels)
利用变量进行数据预取
training_data=... #some data like numpy array
training_labels=...
with tf.Session() as sess:
data_initializer=tf.placeholder(dtype=training_data.dtype,shape=training_data.shape)
label_initializer=tf.placeholder(dtype=training_labels.dtype,shape=training_labels.shape)
input_data=tf.Variable(data_initializer,trainable=False,collections=[])
input_labels=tf.Variable(label_initializer,trainable=False,collections=[])
...
sess.run(input_data.initializer,feed_dict={data_initializer:training_data})
sess.run(input_labels.initializer,feed_dict={label_initializer:training_labels})
...
基于队列API:基于队列相关的API来构建输入流水线Pipeline

主要组成
- 文件名称组成的列表
- 保存文件名的FIFO队列
- 相应文件格式的读取器
- 解码器
- 生成的样本队列(ShuffleQueue)
一个典型的输入结构
使用一个队列作为模型训练的输入,多个线程准备训练样本,一个训练线程执行一个训练操作。
TensorFlow提供了两个类来帮助多线程的实现
- Coordinator类:同时停止多个工作线程。
- QueueRunner类:协调多个工作线程,同时将多个张量推入同一个队列中。
#用来保存文件名称的FIFO队列
filename_queue=tf.train.string_input producer( ["file0.csv"," file1.csv"] )
#根据csv文件选用的读取器,不同种类文件读取器种类也不同
reader=tf.TextLineReader()
key,value=reader.read(filename_queue)
#为处理出现空值情况设置的默认值,以及给定解码器输出的类型
record_defaults = [[1], [1], [1], [1], [1]]
col1,col2,col3,col4,col5=tf.decode_csv(value,record_defaults=record_defaults)
features=tf.stack([col1,co12,col3,col4])
with tf.Session() as sess:
#创建协调器
coord = tf.train.Coordinator()
#在调用run或eva1执行读取之前,必须用tf.train.start_queue_runners来填充队列
threads=tf.train.start_queue_runners(coord=coord)
for i in range(10):
#拿到每次读取的结果
example,label=sess.run([features,col5])
print " example =",example, ",label=",label
coord.request_stop()
coord.join(threads)
#file0.csv,file1.csv的内容
#file0.csv
111,222,333,444,555
222,333,444,555,666
333,444,555,666,777
444,555,666,777,888
#file1.csv
555,444,333,222,111
666,555,444,333,222
777,666,555,444,333
888,777,666,555,444
#随机生成的样本队列
example=[111 222 333 444],label=555
example=[222 333 444 555],label=666
example=[333 444 555 666],label=777
example=[444 555 666 777],label=888
example=[555 444 333 222],label=111
example=[666 555 444 333],label=222
example=[777 666 555 444],label=333
example=[888 777 666 555],label=444
example=[555 444 333 222],label=111
example=[666 555 444 333],label=222
数据的批量处理
def read_my_file_format(filename_queue):
reader=tf.SomeReader()
key,record_string=reader.read(filename_queue)
example,label=tf.some_decoder(record_string)
processed_example=some_processing(example)
return processed_example,label
def input_pipeline(filenames,batch_size,num_epochs=None):
filename_queue=tf.train.string_input_producer(filenames,num_epochs=num_epochs,shuffle=True)
example,label=read_my_file_format(filename_queue)
#出队操作后的所剩数据的最小值
min_after_dequeue=10000
#队列的容量
capacity=min_after_dequeue+3*batch_size
example_batch,label_batch=tf.train.shuffle_batch([example,label],batch_size=batch_size,capacity=capacity,min_after_dequeue=min_after_dequeue)
return example_batch,label_batch
tf.data API:利用tf.data API来构建输入流水线
包含两个基础类:Dataset和Iterator
- Dataset是一类相同类型元素的序列,每个元素由一个或多个张量组成,构建方法有两种:
通过不同的API来读取不同类型的源数据,返回一个Dataset
在已有Dateset基础上通过变换得到新的Dataset,包括map,shuffle,batch和repea等等。 - 利用Iterator类来读取创建好的Dataset中的数据,常用的Iterator:
one-shot iterator:单次迭代器,一次遍历所有元素。
initializable iterator:可初始化迭代器,需要显式运行初始化操作。
reinitializable iterator:可重新初始化迭代器,可以通过多个不同的Dataset对象进行初始化。
feedable iterator:可馈送迭代器,与feed_dict配合使用。
定义损失函数|训练时
自定义损失函数
基本函数
| 类别 | 基本函数及功能说明 |
|---|---|
| 四则运算 | tf.add() , tf.sub() , tf.mul() |
| 科学计算 | tf.abs() , tf.square() , tf.sin() |
| 比较操作 | tf.greater()(返回True/False) |
| 条件判断 | tf.where(condition,tensor_x,tensor_y)(condition是True就返回tensor_x,否则返回tensor_y) |
| 降维操作 | tf.reduce_sum() , tf.reduce_mean() (将高维矩阵元素以 求和 或 均值 的方式 变为一维 ) |
#调用损失函数的示例
loss=tf.reduce_mean(tf.square(y-y_data))
#实际值和预测值的差值平方,再求平均值,训练的目的就是要让这个loss越来越小
应用在图画风格迁移实例的代码
def loss(sess, models, img_content, img_style):
#计算内容损失函数
sess.run(models['input'].assign(img_content))
#内容图像在conv4_2层的特征矩阵
p=sess.run(models['conv4_2'])
#输入图像在conv4_2层的特征矩阵
x = models['conv4_2']
M=p.shape[1]*p.shape[2]
N =p.shape[3]
content_loss=(1.0 /(4*M*N))*tf.reduce_sum(tf.pow(p-x,2))
#计算风格损失函数
sess.run(models['input'].assign(img.style))
style_loss = 0.0
for layer_name,w in STYLE_ LAYERS:
#风格图像在layer_name各层的特征矩阵
a = sess.run(models[layer_name])
#输入图像在layer_name各层的特征矩阵
x=models[layer_name]
M=a.shape[1]*a.shape[2]
N = a.shape[3]
A=gram_matrix(a,M,N)
G=gram_matrix(x,M,N)
style_loss+=(1.0/(4*N**2*M**2))*tf.reduce_sum(tf.pow(G-A, 2))*w
total_lossALPHA * content_loss + BETA * style_loss
return total_loss
def gram_matrix(x, M, N):
x=tf.reshape(x,(M,N))
return tf.matmul(tf.transpose(x),x)
TensorFlow内置的4个损失函数
SoftMax交叉熵
tf.nn.softmax_cross_entropy_with_logits(labels,logits)
加了稀疏的SoftMax交叉熵
tf.nnsparse_softmax_cross_entropy_with_logits(labels,logits)
| 参数 | 含义 |
|---|---|
| logits | 网络最后一层的输出 |
| labels | 标签,分类或分割等问题中的标准答案 |
sigmoid交叉熵
tf.nn.sigmoid_cross_entropy_with_logits(labels,logits)
- 计算公式
l o s s = l a b e l s ∗ − l o g ( s i g m o i d ( l o g i t s ) ) + ( 1 − l a b e l s ) ∗ − l o g ( 1 − s i g m o i d ( l o g i t s ) ) loss=labels*-log(sigmoid(logits))+(1-labels)*-log(1-sigmoid(logits)) loss=labels∗−log(sigmoid(logits))+(1−labels)∗−log(1−sigmoid(logits)) - 令x=logits,z=labels,则有:
l o s s = z ∗ − l o g ( s i g m o i d ( x ) ) + ( 1 − z ) ∗ − l o g ( 1 − s i g m o i d ( x ) ) loss=z*-log(sigmoid(x))+(1-z)*-log(1-sigmoid(x)) loss=z∗−log(sigmoid(x))+(1−z)∗−log(1−sigmoid(x))
= z ∗ − l o g ( 1 1 + e − x ) + ( 1 − z ) ∗ − l o g ( e − x 1 + e − x ) =z*-log(\frac{1}{1+e^{-x}})+(1-z)*-log(\frac{e^{-x}}{1+e^{-x}}) =z∗−log(1+e−x1)+(1−z)∗−log(1+e−xe−x)
= z ∗ l o g ( 1 + e − x ) + ( 1 − z ) ∗ l o g ( 1 + e − x e − x ) =z*log(1+e^{-x})+(1-z)*log(\frac{1+e^{-x}}{e^{-x}}) =z∗log(1+e−x)+(1−z)∗log(e−x1+e−x)
= z ∗ l o g ( 1 + e − x ) + ( 1 − z ) ∗ ( l o g ( 1 + e − x ) − l o g ( e − x ) ) =z*log(1+e^{-x})+(1-z)*(log(1+e^{-x})-log(e^{-x})) =z∗log(1+e−x)+(1−z)∗(log(1+e−x)−log(e−x))
= l o g ( 1 + e − x ) + x ( 1 − z ) =log(1+e^{-x})+x(1-z) =log(1+e−x)+x(1−z)
= x − x z + l o g ( 1 + e − x ) =x-xz+log(1+e^{-x}) =x−xz+log(1+e−x) - 当x<0时,为防止 e − x e^{-x} e−x溢出,此处应为:
l o s s = x − x z + l o g ( 1 + e − x ) = − x z + l o g ( e x ) + l o g ( 1 + e − x ) = − x z + l o g ( 1 + e x ) loss=x-xz+log(1+e^{-x})=-xz+log(e^x)+log(1+e^{-x})=-xz+log(1+e^x) loss=x−xz+log(1+e−x)=−xz+log(ex)+log(1+e−x)=−xz+log(1+ex) - 即
x > 0 : l o s s = x − x z + l o g ( 1 + e − x ) x>0:loss=x-xz+log(1+e^{-x}) x>0:loss=x−xz+log(1+e−x)
x < 0 : l o s s = − x z + l o g ( 1 + e x ) x<0:loss=-xz+log(1+e^x) x<0:loss=−xz+log(1+ex) - 因此,实际计算时,为保证稳定性并防止溢出,使用:
l o s s = m a x ( x , 0 ) − x z + l o g ( 1 + e − ∣ x ∣ ) loss=max(x,0)-xz+log(1+e^{-|x|}) loss=max(x,0)−xz+log(1+e−∣x∣)
带权重的sigmoid交叉熵
tf.nn.weighted_cross_entropy_with_logits(targets,logits,pos_weight)
-
该函数功能及计算方法与tf.nn.sigmoid_cross_entropy_with_logits类似,但加了权重功能,是计算具有权重的sigmoid交叉熵函数
-
目的:增加或减小正样本在计算交叉熵时的loss
-
计算方法:loss=-pos_weight* targets*log(sigmoid(logits))-(1-targets)*log(1-sigmoid(logits))
-
令x=logits,z=targets,q=pos_weight,则有:
l o s s = q z ∗ − l o g ( s i g m o i d ( x ) ) + ( 1 − z ) ∗ − l o g ( 1 − s i g m o i d ( x ) ) loss=qz*-log(sigmoid(x))+(1-z)*-log(1-sigmoid(x)) loss=qz∗−log(sigmoid(x))+(1−z)∗−log(1−sigmoid(x))
= q z ∗ − l o g ( 1 1 + e − x ) + ( 1 − z ) ∗ − l o g ( e − x 1 + e − x ) =qz*-log(\frac{1}{1+e^{-x}})+(1-z)*-log(\frac{e^{-x}}{1+e^{-x}}) =qz∗−log(1+e−x1)+(1−z)∗−log(1+e−xe−x)
= q z ∗ l o g ( 1 + e − x ) + ( 1 − z ) ∗ ( l o g ( 1 + e − x ) − l o g ( e − x ) ) =qz*log(1+e^{-x})+(1-z)*(log(1+e^{-x})-log(e^{-x})) =qz∗log(1+e−x)+(1−z)∗(log(1+e−x)−log(e−x))
= ( q z + 1 − z ) ∗ l o g ( 1 + e − x ) + x ( 1 − z ) =(qz+1-z)*log(1+e^{-x})+x(1-z) =(qz+1−z)∗log(1+e−x)+x(1−z)
= x ( 1 − z ) + ( 1 + ( q − 1 ) ∗ z ) ∗ l o g ( 1 + e − x ) =x(1-z)+(1+(q-1)*z)*log(1+e^{-x}) =x(1−z)+(1+(q−1)∗z)∗log(1+e−x) -
令l=(1+(q-1)*z),为保证稳定性并避免溢出,实现中采用:
l o s s = m a x ( x , 0 ) − x z + l ∗ l o g ( 1 + e − ∣ x ∣ ) loss=max(x,0)-xz+l*log(1+e^{-|x|}) loss=max(x,0)−xz+l∗log(1+e−∣x∣)
创建优化器|训练时
优化器的功能是实现优化算法,可以自动为用户计算模型参数的梯度值
TensorFlow中支持的优化器函数
- tf.train.Optimizer
- tf.train.GradientDescentOptimizer:梯度下降优化器
返回一个优化器,参数为learningRate
train=tf.train.GradientDescentOptimizer(learningRate) - tf.train.AdadeltaOptimizer
- tf.train.AdagradOptimizer
- tf.train.AdagradDAOptimizer
- tf.train.MomentumOptimizer:动量梯度下降优化器
- tf.train.AdamOptimizer:Adam算法优化器
返回一个使用Adam算法的优化器,参数为learningRate
Adam算法:综合了Momentum和RMSProp方法,根据损失函数对每个参数的梯度的一阶矩估计和二阶矩估计动态调整针对于每个参数的学习率
train=tf.train.AdamOptimizer(learningRate) - tf.train.FtrlOptimizer
- tf.train.ProximalGradientDescentOptimizer
- tf.train.ProximalAdagradOptimizer
- tf.train.RMSPropOptimizer
定义模型训练方法|训练时
| 操作 | 功能 |
|---|---|
| tf.train.Optimizer.minimize(loss,global_step=None,var_list=None) | 使用最小化损失函数的方法来训练模型,执行该操作时会内部依次调用compute_gradients和apply_gradients操作 |
| tf.train.Optimizer.compute_gradients(loss,var_list=None) | 对var_list中列出的模型参数计算梯度,返回(梯度,模型参数)组成的列表 |
| tf.train.Optimizer.apply_gradients(grads_and_vars) | 将计算出的梯度更新到模型参数上,返回更新参数的操作 |
最小化损失函数minimize
一般采用最小化损失函数的方法:train_op= tf.train.Optimizer.minimize(loss,global_step=None,var_list=None)
- 可以直接用模型训练,简单有效
- 对于需要对梯度进行其他处理的优化,取、其设计流程为:
- 使用compute_gradients()方法计算出梯度
- 按需求处理梯度,如进行裁剪,加权,平均等
- 使用apply_gradients()方法将处理后的梯度值更新到模型参数中
对梯度的处理
对于模型层次较多的网络,由于输入数据不合法,求导精度限制等原因,可能出现梯度爆炸或梯度消失的问题,使得模型训练无法快速收敛。
解决方法:
- 减小学习率
- 梯度裁剪(Gradient Clipping)–例如对L2范式裁剪
梯度的L2范数为: ∣ ∣ t ∣ ∣ 2 = g r a d ( w 1 ) 2 + g r a d ( w 2 ) 2 + . . . ||t||_2=\sqrt{grad(w_1)^2+grad(w_2)^2+...} ∣∣t∣∣2=grad(w1)2+grad(w2)2+...
设置裁剪阈值c,则
当 ∣ ∣ t ∣ ∣ 2 > c ||t||_2>c ∣∣t∣∣2>c时, g r a d ( w i ) = c ∣ ∣ t ∣ ∣ 2 g r a d ( w i ) grad(w_i)=\frac{c}{||t||_2}grad(w_i) grad(wi)=∣∣t∣∣2cgrad(wi)
当 ∣ ∣ t ∣ ∣ 2 ≤ c ||t||_2\leq c ∣∣t∣∣2≤c时, g r a d ( w i ) grad(w_i) grad(wi)不变
TensorFlow中内置的梯度处理功能
| 方法 | 功能 |
|---|---|
| tf.clip_by_value(t,clip_value_min,clip_value_max) | 将梯度t裁剪到[clip_value_min,clip_value_max]区间 |
| tf.clip_by_norm(t,clip_norm) | 对梯度t的L2范数进行裁剪,clip_norm为裁剪阈值 |
| tf.clip_by_average_norm(t,clip_norm) | 对梯度t的平均L2范数进行裁剪,clip_norm为裁剪阈值 |
| tf.clip_by_global_norm(t_list,clip_norm) | 对梯度t_list进行全局规范化加和裁剪,clip_norm为裁剪阈值 |
| tf.global_norm(t_list) | 计算t_list中所有梯度的全局范式 |
整体流程
#创建Adam优化器
optimizer=tf.train.AdamOptimizer(learning_rate)
#计算梯度
grads=optimizer.compute_gradients(loss)
#对梯度的L2范数进行裁剪
grads=tf.clip_by_norm(grads,clip_norm)
#更新模型参数
train_op=optimizer.apply_gradients(grads)
模型保存|训练时
在模型训练中,使用tf.train.Saver()来保存模型中的所有变量
import tensorflow as tf
weights=tf.Variable(tf.random_normal([30,60],stddev=0.35),name="weights")
w2=tf.Variable(weights.initialized_value(),name="w2")
#实例化saver对象
saver=tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in xrange(1000000):
#执行模型训练
sess.run(training_op)
if step%1000==0:
#将训练得到的变量值保存到检查点文件中
saver.save(sess,'./ckpt/my-model')
恢复模型
当需要基于某个checkpoint继续训练模型参数时,需要从.ckpt文件中恢复出已保存的变量
同样使用tf.train.Saver()来恢复变量,恢复变量时不需要先初始化变量
import tensorflow as tf
weights=tf.Variable(tf.random_normal([30,60],stddev=0.35),name="weights")
w2=tf.Variable(weights.initialized_value(),name="w2")
#模型路径只需要给出文件夹名称
model_path="./ckpt"
#实例化saver对象
saver=tf.train.Saver()
with tf.Session() as sess:
#找到存储变量值的位置
ckpt=tf.train.latest_checkpoint(model_path)
#恢复变量
saver.restore(sess,ckpt)
print(sess.run(weights))
print(sess.run(w2))
预测部分[读取样本-运算单元-神经网络结构]
读取输入样本
def load_image(path):
img=cv2.imread(path,cv2.IMREAD_COLOR)
resize_img=cv2.resize(img,(224,224))
norm_img=resize_img/255.0
return np.reshape(norm_img,(1,224,224,3))#NHWC的四维张量
定义基本运算单元
使用tf.nn模块定义基本运算单元
def basic_calc(caltype,nin,inwb=None):
if caltype=='conv':
#nin:本层输入:inwb:inwb[0],inwb[1]==weights,bias
return tf.nn.relu(tf.nn.conv2d(nin,inwb[0],strides=[1,1,1,1],padding='SAME')+inwb[1])
elif caltype=='pool':
return tf.nn.max_pool(nin,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
def read_wb(vgg19_npy_path,name):
#从vgg_npy_path路径中读取模型参数到数组data_dict
data_dict=np.load(vgg19_npy_path,encoding='latin1').item()
weights=data_dict[name][0]
weights=tf.constant(weights)
bias=data_dict[name][1]
bias=tf.constant(bias)
return weights,bias片
tf.nn模块简介
tf.nn是TensorFlow中用于深度学习计算的核心模块,提供神经网络相关操作的支持,包括卷积,池化,损失,分类等。
- 卷积函数
| 操作 | 说明 |
|---|---|
| tf.nn.conv2d(input,filter,strides,padding) | 在给定的input和filter下计算卷积 |
| tf.nn.depthwise_conv2d(input,filter,strides,padding) | 卷积核能相互独立的在自己的通道上面进行卷积操作 |
| tf.nn.separable_conv2d(input,depthwise_filter,pointwise_filter,strides,padding) | 在纵深卷积depthwise_filter之后进行逐点卷积separable_filter |
| tf.nn.bias_add(value,bias) | 对输入加上偏置 |
- 激活函数
| 操作 | 说明 |
|---|---|
| tf.nn.relu(features) | 计算relu函数 |
| tf.nn.elu(features) | 计算elu函数 |
| tf.nn.dropout(x,keep_prob) | 计算dropout,其中keep_prob是keep概率。 |
| tf.sigmoid(x) | 计算sigmoid函数 |
| tf.tanh(x) | 计算tanh函数 |
- 池化函数
| 操作 | 说明 |
|---|---|
| tf.nn.avg_pool(value,ksize,strides,padding) | 平均方式池化 |
| tf.nn.max_pool(value,ksize,strides,padding) | 最大值方法池化 |
| tf.nn.max_pool_with_argmax(input,ksize,strides,padding) | 返回一个二维元组(output,argmax),最大值pooling,返回最大值及其相应的索引 |
- 损失函数
| 操作 | 说明 |
|---|---|
| tf.nn.l2_loss(t) | output=sum(t**2)/2 |
创建神经网络结构
def build_vggnet(vgg19_npy_path):
models={}
models['input']=tf.Variable(np.zeros((1,224,224,3)).astype('float32'))
models['conv1_1']=basic_calc('conv',models['input'],read_wb(vgg19_npy_path,'conv1_1' ))
models['conv1_2']=basic_calc('conv',models['conv1_1'],read_wb(vgg19_npy_path,'conv1_2'))
models['pool1']=basic_calc('pool',mode1s['conv1_2'])
models['conv2_1']=basic_calc('conv',mode1s['pool1'],read_wb(vgg19_npy_path,'conv2_1'))
mode1s['conv2_2']=basic_calc('conv',models['conv2_1'],read_wb(vgg19_npy_path,'conv2_2'))
models['pool2']=basic_calc('pool',models['conv2_2'])
mode1s['conv3_1']=basic_calc('conv',models['pool2'],read_wb(vgg19_npy_path,'conv3_1'))
mode1s['conv3_2']=basic_calc('conv',models['conv3_1'],read_wb(vgg19_npy_path,'conv3_2'))
models['conv3_3']=basic_calc('conv',mode1s['conv3_2'],read_wb(vgg19_npy_path,'conv3_3'))
models['conv3_4']=basic_calc('conv',models['conv3_3'],read_wb(vgg19_npy_path,'conv3_4'))
mode1s['pool3']=basic_calc('pool',mode1s['conv3_4'])
models['conv4_1']=basic_calc('conv',models['pool3'],read_wb(vgg19_npy_path,'conv4_1'))
mode1s['conv4_2']=basic_calc('conv',models['conv4_1'],read_wb(vgg19_npy_path,'conv4_2'))
mode1s['conv4_3']=basic_calc('conv',models['conv4_2'],read_wb(vgg19_npy_path,'conv4_3'))
mode1s['conv4_4']=basic_calc('conv',models['conv4_3'],read_wb(vgg19_npy_path,'conv4_4'))
models['pool4']=basic_calc('pool',models['conv4_4'])
models['conv5_1']=basic_calc('conv',models['pool4'],read_wb(vgg19_npy_path,'conv5_1'))
models['conv5_2']=basic_calc('conv',mode1s['conv5_1'],read_wb(vgg19_npy_path,'conv5_2'))
models['conv5_3']=basic_calc('conv',models['conv5_2'],read_wb(vgg19_npy_path,'conv5_3'))
models['conv5_4']=basic_calc('conv',mode1s['conv5_3'],read_wb(vgg19_npy_path,'conv5_4'))
models['pool5']=basic_calc('pool',models['conv5_4'])
return models
计算模型输出
#模型文件路径,需要加载
vgg19_npy_path='./vgg_models.npy'
#获取输入的内容图像
img_content=load_image('./content.jpg')
#创建会话进行执行
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())#变量初始化
#开始计算模型输出的部分
models=build_vggnet(vgg19_npy_path)
sess.run(models['input'].assign(img_content))
res=sess.run(models['pool5'])
#接下来对res做其他处理
...
小结
- 训练模型
- 加载数据【注入,预取,队列,API】
- 定义损失函数
- 自定义损失函数
- TensorFlow内置
- 创建优化器【Adam】
- 定义模型训练方法【minimize-梯度处理(裁剪)】
- 保存模型(变量/参数)
- 预测模型
- 读取输入
- 定义运算单元
- 创建神经网络结构
- 计算模型输出
总结
- 深度学习编程框架的概念
深度学习编程框架的概念和分类 - TensorFlow概述
TensorFlow的历史,发展历程 - TensorFlow编程模型及基本用法
TensorFlow中常用的计算图,张量,操作,会话,变量,占位符,队列等概念 - 基于TensorFlow的训练及预测实现
TensorFlow模型训练,预测等
这里因为还没实践,听的云里雾里的,准备开始上手实战看看再来修正
目前就先按课程写个笔记,之后如果遇到问题再来回顾。(感觉这章视频杂音比较多)