MySQL为什么第二次查询会快一些?缓存?不一定
最近在公司组织了一次SQL优化大赛,出现了一个问题引起了一位同事的不爽,为什么我优化出来SQL跟他的一样,为什么时间会相差那么大?并且都是加了SQL_NO_CACHE的情况下。
其实在校验结果的时候,那位同事的SQL是第一个跑的,导致后面相同或者相似的SQL会比他的快很多。What?明明都已经禁用了query_cache,为什么还会有那么大的区别呢?也许是大家极少进行SQL优化,对Innodb的结构不太清楚,包括网上很多博客,其实都忽略了一点,就是在Innodb引擎中,不只是query_cache,还有一个buffer pool,翻译成中文就是一个缓存,一个缓冲区。
query_cache到底是个啥?能干嘛?
- query_cache存储SELECT语句的文本以及发送到客户端的相应结果。如果稍后收到相同的语句,则服务器将从查询缓存中检索结果,而不是再次解析和执行语句。查询缓存在会话之间共享,因此可以发送由一个客户端生成的结果集以响应由另一个客户端发出的相同查询。
- 查询缓存在您拥有不经常更改且服务器接收许多相同查询的表的环境中非常有用。这是许多基于数据库内容生成许多动态页面的Web服务器的典型情况。
命中cache的具体要求如下:
1. 查询必须完全相同(字节为字节)才能看作相同。另外,由于其他原因,可以将相同的查询字符串视为不同。使用不同数据库,不同协议版本或不同默认字符集的查询被视为不同的查询,并单独缓存;
2. 查询是外部查询的子查询不会缓存;
3. 在存储的函数,触发器或事件的主体内执行的查询不会使用缓存;
4. query_cache不返回过时数据,如果表更改(包括表结构和数据的更改),则使用该表的所有query_cache都将变为无效并从query_cache中删除。
说了这么多,并不是引导你不去使用query_cache,其实MySQL在从MySQL 5.7.20开始,已经开始废弃query_cache,并在MySQL 8.0中删除,主要原因是不能与多核计算机上的高吞吐量工作负载进行扩展,解释如下:
Assuming that scalability could be improved, the limiting factor of the query cache is that since only queries that hit the cache will see improvement; it is unlikely to improve predictability of performance. For user facing systems, reducing the variability of performance is often more important than improving peak throughput。
假设可以提高可伸缩性,query cache的限制因素是在于只有访问缓存的查询才会看到明显的提升; 它跟提高性能的可预测性并不一样。 对于面向用户的系统,降低性能的可变性通常比提高峰值吞吐量更重要。
也就是说query_cache对于性能的提升可变性太高,比起能够提升峰值的吞吐量,似乎有些得不偿失,当然,我们
介绍了这么多query_cache,也是要退出历史舞台的东西了,要介绍真正的主角应该是buffer pool。
buffer pool又是个嘛呢?
- 缓冲池是主存储器中的一个区域,用于在InnoDB访问时缓存表和索引数据。缓冲池允许直接从内存处理常用数据,从而加快处理速度。在专用服务器上,通常会将最多80%的物理内存分配给缓冲池;
- 为了提高大容量读取操作的效率,缓冲池被分成可以容纳多行的页面。为了提高缓存管理的效率,缓冲池被实现为链接的页面列表; 使用LRU算法的变体,很少使用的数据在缓存中老化 ;
- 了解如何利用缓冲池将频繁访问的数据保存在内存中是MySQL调优的一个重要方面。
缓冲池LRU算法
当需要空间将新页面添加到缓冲池时,最近最少使用的页面被逐出,并且新页面被添加到列表的中间。此中点插入策略将列表视为两个子列表:
-
在头部是最近访问过的新(“ 年轻 ”)页面的子列表
-
在尾部是最近访问的旧页面的子列表
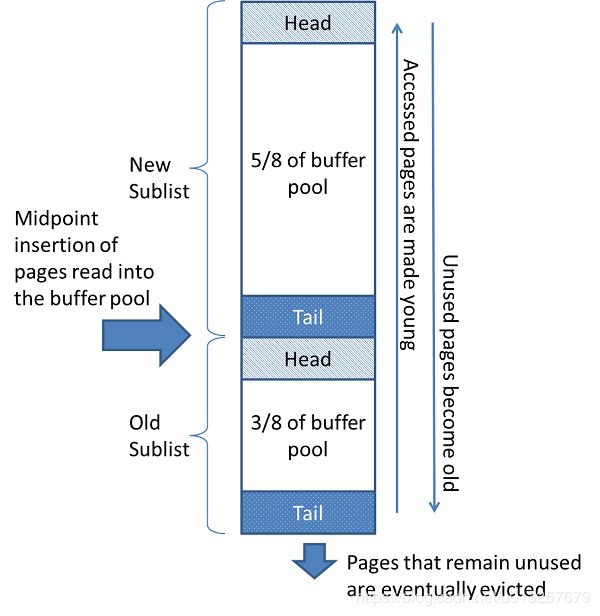
该算法在新子列表中保留了大量页面。旧子列表包含较少使用的页面; 这些页面是驱逐的候选人 。
默认情况下,算法操作如下:
- 3/8的缓冲池专用于旧子列表。
- 列表的中点是新子列表的尾部与旧子列表的头部相交的边界。
- 当InnoDB将页面读入缓冲池时,它最初将其插入中点(旧子列表的头部)。可以读取页面,因为它是用户启动的操作(如SQL查询)所必需的,或者是由自动执行的预读操作的一部分 InnoDB。
- 访问旧子列表中的页面使其 “ 年轻 ”,将其移动到新子列表的头部。如果由于用户启动的操作需要读取页面,则第一次访问立即发生,页面变为年轻。如果由于预读操作而读取了页面,则第一次访问不会立即发生,并且可能在页面被驱逐之前根本不会发生。
- 随着数据库的运行,在缓冲池的页面没有被访问的“ 年龄 ”通过向列表的尾部移动。新旧子列表中的页面随着其他页面的变化而变旧。旧子列表中的页面也会随着页面插入中点而老化。最终,仍然未使用的页面到达旧子列表的尾部并被逐出。
默认情况下,查询读取的页面会立即移动到新的子列表中,这意味着它们会更长时间地保留在缓冲池中。例如,为mysqldump操作或SELECT没有WHERE子句的 语句 执行的表扫描可以将大量数据带入缓冲池并逐出相同数量的旧数据,即使新数据从未再次使用过。类似地,由预读后台线程加载并仅访问一次的页面将移动到新列表的头部。这些情况可以将经常使用的页面推送到旧的子列表中,在那里它们会被驱逐。
但是这里需要清楚我怎么知道我的查询到底是不是在buffer里面查出来的,也给上面那位同事解释清楚两个SQL跑出较大时间差距的原因。
可以通过SHOW ENGINE INNODB STATUS查询有关缓冲池操作的指标。缓冲池指标位于标准监视器输出BUFFER POOL AND MEMORY部分, InnoDB显示类似于以下内容:
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 2198863872
Dictionary memory allocated 776332
Buffer pool size 131072
Free buffers 124908
Database pages 5720
Old database pages 2071
Modified db pages 910
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 4, not young 0
0.10 youngs/s, 0.00 non-youngs/s
Pages read 197, created 5523, written 5060
0.00 reads/s, 190.89 creates/s, 244.94 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not
0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read
ahead 0.00/s
LRU len: 5720, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]解释如下:
| 名称 | 描述 |
|---|---|
| Total memory allocated | 为缓冲池分配的总内存(以字节为单位)。 |
| Dictionary memory allocated | 为InnoDB数据字典分配的总内存(以字节为单位)。 |
| Buffer pool size | 分配给缓冲池的页面的总大小。 |
| Free buffers | 缓冲池空闲列表的页面总大小。 |
| Database pages | 缓冲池LRU列表的页面总大小。 |
| Old database pages | 缓冲池旧LRU子列表的页面总大小。 |
| Modified db pages | 缓冲池中修改的当前页数。 |
| Pending reads | 等待读入缓冲池的缓冲池页数。 |
| Pending writes LRU | 要从LRU列表底部写入的缓冲池中的旧脏页数。 |
| Pending writes flush list | 在检查点期间要刷新的缓冲池页数。 |
| Pending writes single page | 缓冲池中挂起的独立页面写入次数。 |
| Pages made young | 缓冲池LRU列表中的年轻页总数(移动到“ 新 ”页面的子列表的头部)。 |
| Pages made not young | 缓冲池LRU列表中不再年轻的页面总数(保留在“ 旧 ”子列表中的页面,而不是被当做年轻页面)。 |
| youngs/s | 在缓冲池LRU列表中对旧页面的每秒平均访问次数导致页面变得年轻。 |
| non-youngs/s | 在缓冲池LRU列表中对旧页面的每秒平均访问次数导致不使页面变得年轻。 |
| Pages read | 从缓冲池中读取的总页数。 |
| Pages created | 缓冲池中创建的总页数。 |
| Pages written | 从缓冲池写入的总页数。 |
| reads/s | 每秒缓冲池读取的页面数。 |
| creates/s | 每秒缓冲池创建的页面数。 |
| writes/s | 每秒缓冲池写入的页面数。 |
| Buffer pool hit rate | 从缓冲池内存中读取的页面与从磁盘存储中读取的页面的缓冲池页面命中率。 |
| young-making rate | 页面访问的平均命中率导致页面变得年轻。 |
| not (young-making rate) | 页面访问的平均命中率并未导致页面变得年轻。 |
| Pages read ahead | 每秒预读操作的平均值。 |
| Pages evicted without access | 在没有从缓冲池访问的情况下被逐出的页面的每秒平均值。 |
| Random read ahead | 随机预读操作的每秒平均值。 |
| LRU len | 缓冲池LRU列表的页面总大小。 |
| unzip_LRU len | 缓冲池的总页面大小unzip_LRU列表。 |
| I/O sum | 访问的缓冲池LRU列表页面总数,最近50秒。 |
| I/O cur | 访问的缓冲池LRU列表页面的总数。 |
| I/O unzip sum | 访问的缓冲池unzip_LRU列表页面总数。 |
| I/O unzip cur | 访问的缓冲池unzip_LRU列表页面总数。 |
在理想情况下(保证只有你在操作数据库并且扫描的行数可观),可以在执行查询前后执行SHOW ENGINE INNODB STATUS,关注Buffer pool hit rate和I/O sum的变化(需要注意的是I/O sum保存的是最近50秒的数据)。
- 如果Buffer pool hit rate执行前后保持一致,并且I/O sum执行后增大了,基本上就是获取了buffer pool中的数据了;
- 如果Buffer pool hit rate执行后明显降低了,说明有磁盘读取的数据进来了,这种情况基本上是第一次执行该SQL,或者很久没有执行相关SQL,buffer pool中已经淘汰了这部分数据。
但是并不绝对,仅供参考,毕竟这个数据是对整个buffer pool进行分析了,不针对单一SQL。 - 目前没有办法禁用或者直接清除buffer pool,不过可以通过set global innodb_buffer_pool_size=XXX; 把缓冲区的大小调到足够小,并且在验证查询之前先跑一个扫描行数比较可观的查询,把这一部分数据变成新子列表中的数据,这个时候再去执行需要验证的查询,那么很大概率是从磁盘中读取的(不建议在生产环境进行这样的操作,会影响到其它查询性能)。
- 如果是在开发环境进行调优,可以同步生产或者测试环境的数据到本地数据库,通过重启数据库也可以进行buffer pool的清除
参考:https://dev.mysql.com/doc/refman/5.7/en/innodb-buffer-pool.html
https://dba.stackexchange.com/questions/199397/why-query-with-sql-no-cache-runs-slower-on-the-first-run
https://mysqlserverteam.com/mysql-8-0-retiring-support-for-the-query-cache/
![]()