本教程基于4台机器(预装有CentOS7 Linux系统)完成Hadoop集群及其相关组件的搭建,1个master,3个slave。
1 Linux环境准备
1.1 基础设置
- 修改主机名
hostnamectl set-hostname master
reboot
依次将其他3台机器设置为slave1,slave2,slave3。
- 修改IP地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="c35b7341-8921-48f5-ad7a-08cb5af4ba54"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=xxx.xxx.xxx.xxx
NETMASK=255.255.255.0
GATEWAY=xxx.xxx.xxx.xxx
DNS1=8.8.8.8
DNS2=8.8.4.4
service network restart
- 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
- ssh通信
// 生成密钥
ssh-keygen -t rsa
// 将公钥追加到验证表中
cat id_rsa.pub >> ~/.ssh/authorized_keys
// 将公钥追加到其他主机验证表中
ssh-copy-id -i ~/.ssh/id_rsa.pub root@slave1
ssh-copy-id -i ~/.ssh/id_rsa.pub root@slave2
ssh-copy-id -i ~/.ssh/id_rsa.pub root@slave3
- 网络配置
推荐使用桥接模式,且IP与宿主机处于同一区段,网关、子页掩码、DNS与宿主机保持一致,IP采用静态或DHCP均可,推荐使用静态模式,以防IP经常变化,频繁修改/etc/hosts等配置文件。需要注意的是,IP设置使用静态模式时,需要在宿主机上ping一下相关IP,以防IP已被占用,设置之后引起冲突。
- 配置hosts,以便DNS解析主机名
vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
xxx.xxx.xxx.xxx master
xxx.xxx.xxx.xxx slave1
xxx.xxx.xxx.xxx slave2
xxx.xxx.xxx.xxx slave3
拷贝给其他主机:
scp /etc/hosts root@slave1:/etc/
1.2 Java环境
1.2.1 安装包拷贝、解压
将压缩包拷贝至Linux系统中,移动到/usr/software/java目录下,并解压:
mv jdk-8u191-linux-x64.tar.gz /usr/software/java
tar -zxvf jdk-8u191-linux-x64.tar.gz
1.2.2 设置环境变量
vim /etc/profile
export JAVA_HOME=/usr/software/java/jdk1.8.0_191
export JRE_HOME=$JAVA_HOME/jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export CLASS_PATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
Esc[:wq]保存后,执行以下命令让其当即生效:
source /etc/profile
输入:
java -version
出现以下信息则表明hadoop安装成功:
java version "1.8.0_191"
Java(TM) SE Runtime Environment (build 1.8.0_191-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)
2 Hadoop全家桶
2.1 Hadoop集群
2.1.1 安装包拷贝、解压
将压缩包拷贝至Linux系统中,移动到/usr/software/hadoop目录下,并解压:
mv hadoop-3.0.3.tar.gz /usr/software/hadoop
tar -zxvf hadoop-3.0.3.tar.gz
2.1.2 设置环境变量
vim /etc/profile
export HADOOP_INSTALL=/usr/software/hadoop/hadoop-3.0.3
export PATH=$PATH:$HADOOP_INSTALL/bin:$HADOOP_INSTALL/sbin
Esc[:wq]保存后,执行以下命令让其当即生效:
source /etc/profile
2.1.3 修改启动文件
主要为hadoop指定java环境:
vim vim /usr/software/hadoop/hadoop-3.0.3/etc/hadoop/hadoop-env.sh
添加如下内容后保存:
JAVA_HOME=/usr/software/java/jdk1.8.0_191
使其当即生效:
source /usr/software/hadoop/hadoop-3.0.3/etc/hadoop/hadoop-env.sh
输入:
hadoop version
出现以下信息则表明hadoop安装成功:
Hadoop 3.0.3
Source code repository https://[email protected]/repos/asf/hadoop.git -r 37fd7d752db73d984dc31e0cdfd590d252f5e075
Compiled by yzhang on 2018-05-31T17:12Z
Compiled with protoc 2.5.0
From source with checksum 736cdcefa911261ad56d2d120bf1fa
This command was run using /usr/software/hadoop/hadoop-3.0.3/share/hadoop/common/hadoop-common-3.0.3.jar
2.1.3 修改配置文件
- core-site.xml
主要配置HDFS的地址和端口号。
vim /usr/software/hadoop/hadoop-3.0.3/etc/hadoop/core-site.xml
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
/usr/software/hadoop/tmp
- hdfs-site.xml
主要配置分布式文件系统。
vim /usr/software/hadoop/hadoop-3.0.3/etc/hadoop/hdfs-site.xml
dfs.namenode.http-address
master:50070
dfs.namenode.secondary.http-address
slave1:50090
dfs.namenode.name.dir
/usr/software/hadoop/dfs/name
dfs.datanode.data.dir
/usr/software/hadoop/dfs/data
dfs.replication
3
- mapred-site.xml
主要是配置JobTracker的地址和端口。
vim /usr/software/hadoop/hadoop-3.0.3/etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
- yarn-site.xml
主要设置resourcemanager以及reducer取数据的方式。
vim /usr/software/hadoop/hadoop-3.0.3/etc/hadoop/yarn-site.xml
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
- master和slaves
vim /usr/software/hadoop/hadoop-3.0.3/etc/hadoop/master
master
#######################################################
vim /usr/software/hadoop/hadoop-3.0.3/etc/hadoop/slaves
slave1
slave2
slave3
# 需要注意的是:hadoop3.0之后,默认配置文件中无slaves,以workers替代,设置方式与slaves等同。
2.1.4 启动集群
- 格式化集群的文件系统
hadoop namenode -format
- 启动hadoop集群
start-all.sh
- 关闭hadoop集群
stop-all.sh
HDFS的web界面端口:50070
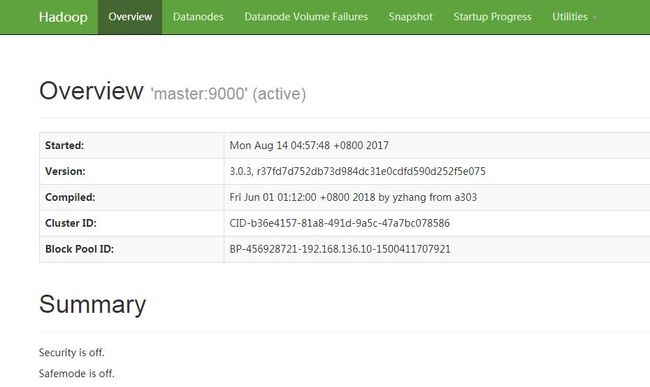
YARN的web界面端口:8088
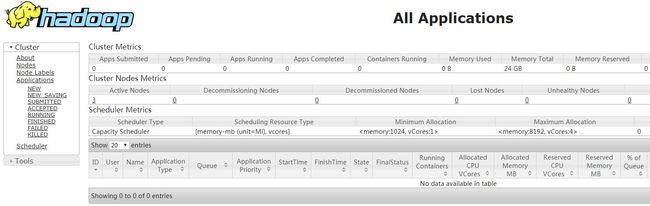
2.2 Spark安装
2.2.1 Scala环境
- 安装包拷贝、解压
将压缩包拷贝至Linux系统中,移动到/usr/software/scala目录下,并解压:
mv scala-2.12.7.tgz /usr/software/scala
tar -zxvf scala-2.12.7.tgz
- 设置环境变量
vim /etc/profile
export SCALA_HOME=/usr/software/scala/scala-2.12.7
export PATH=$PATH:$SCALA_HOME/bin
Esc[:wq]保存后,执行以下命令让其当即生效:
source /etc/profile
输入:
scala
出现以下信息则表明hadoop安装成功:
Welcome to Scala 2.12.7 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_191).
Type in expressions for evaluation. Or try :help.
scala>
2.2.2 Spark集群
- 安装包拷贝、解压
将压缩包拷贝至Linux系统中,移动到/usr/software/spark目录下,并解压:
mv spark-2.3.2-bin-hadoop2.7.tgz /usr/software/spark
tar -zxvf spark-2.3.2-bin-hadoop2.7.tgz
- 设置环境变量
vim /etc/profile
export SPARK_HOME=/usr/software/spark/spark-2.3.2-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
Esc[:wq]保存后,执行以下命令让其当即生效:
source /etc/profile
- 配置spark参数
cd /usr/software/spark/spark-2.3.2-bin-hadoop2.7/conf/
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
添加如下内容:
export JAVA_HOME=/usr/software/java/jdk1.8.0_191
export SCALA_HOME=/usr/software/scala/scala-2.12.7
export SPARK_MASTER_IP=xxx.xxx.xxx.xxx
export SPARK_WORKER_MEMORY=8g
export HADOOP_CONF_DIR=/usr/software/hadoop/hadoop-3.0.3/etc/hadoop
vim slaves
slave1
slave2
slave3
2.2.3 spark集群启动
cd /usr/software/spark/spark-2.3.2-bin-hadoop2.7/sbin/
./start-all.sh
注意:spark和hadoop的启动脚本名称是相同的,又因为hadoop已经将sbin目录配置进Path环境变量中去了,所以启动spark时,需要进入spark的sbin目录。
web界面端口:8080
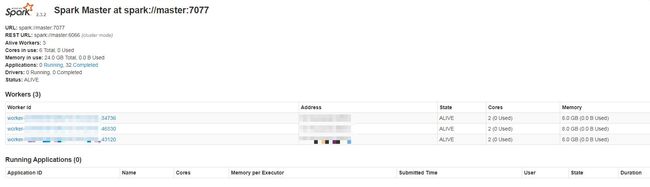
2.3 Zookeeper集群
本教程中,我们使用slave1,slave2,slave3三台机器搭建zookeeper集群。
首先在slave1上进行相关安装,然后将配置好的目录复制到其他机器上(slave2, slave3)即可。
- 安装包拷贝、解压
将压缩包拷贝至Linux系统中,移动到/usr/software/zookeeper目录下,并解压:
mv zookeeper-3.4.10.tar.gz /usr/software/zookeeper
tar -zxvf zookeeper-3.4.10.tar.gz
- 配置文件修改
cd /usr/software/zookeeper/zookeeper-3.4.10/conf
cp ./zoo_sample.cfg ./zoo.cfg
vim zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/software/zookeeper/zookeeper-3.4.10/data # 修改存放zookeeper数据的目录
clientPort=2181
# 添加3个节点的信息
server.1=slave1:2888:3888
server.2=slave2:2888:3888
server.3=slave3:2888:3888
- 配置参数说明
tickTime:zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是说每个tickTime时间就会发送一个心跳。
initLimit:配置zookeeper接受客户端(这里所说的客户端不是用户连接zookeeper服务器的客户端,而是zookeeper服务器集群中连接到leader的follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。
当已经超过10个心跳的时间(也就是tickTime)长度后 zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 10*2000=20秒。
syncLimit:标识leader与follower之间发送消息,请求和应答时间长度,最长不能超过多少个tickTime的时间长度,总的时间长度就是5*2000=10秒。
dataDir:zookeeper保存数据的目录,默认情况下zookeeper将写数据的日志文件也保存在这个目录里;
clientPort:客户端连接Zookeeper服务器的端口,Zookeeper会监听这个端口接受客户端的访问请求;
server.A=B:C:D中的A是一个数字,表示这个是第几号服务器,B是这个服务器的IP地址,C第一个端口用来集群成员的信息交换,表示这个服务器与集群中的leader服务器交换信息的端口,D是在leader挂掉时专门用来进行选举leader所用的端口。
- 创建ServerID标识
除了修改zoo.cfg配置文件外,zookeeper集群模式下还要配置一个myid文件,这个文件需要放在dataDir目录下。
/usr/software/zookeeper/zookeeper-3.4.10/data
vim myid
1
[ESC] + wq保存即可
同时在slave2,slave3相同路径下创建myid文件,并分别输入2, 3保存。
- 集群启动
在每台机器上分别执行以下命令:
cd /usr/software/zookeeper/zookeeper-3.4.10/bin/
./zkServer.sh start
可以输入以下命令查看机器zookeeper的状态:
[root@slave1 bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/software/zookeeper/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
可以看出,当前节点为zookeeper的从节点。
2.4 Hbase集群
本案例基于4台机器搭建Hbase集群:
- 安装包拷贝、解压
将压缩包拷贝至Linux系统中,移动到/usr/software/hbase目录下,并解压:
mv hbase-1.2.8-bin.tar.gz /usr/software/hbase
tar -zxvf hbase-1.2.8-bin.tar.gz
- hbase-site.xml
cd /usr/software/hbase/hbase-1.2.8/conf
vim hbase-site.xml
hbase.master
master:60000
hbase的主节点与端口号
hbase.master.maxclockskew
180000
时间同步允许的时间差
hbase.rootdir
hdfs://master:9000/hbase
hbase共享目录,持久化hbase数据
hbase.cluster.distributed
true
是否为分布式
hbase.zookeeper.quorum
slave1,slave2,slave3
指定zookeeper
dfs.replication
3
备份数
- regionservers
cd /usr/software/hbase/hbase-1.2.8/conf
vim regionservers
slave1
slave2
slave3
将配置好的hbase目录同步到另外3台机器。
- 启动hbase
cd /usr/software/hbase/hbase-1.2.8/bin
./start-hbase.sh
启动后,在master节点jps看到HMaster进程,slave节点多出HRegionServer进程。
Hbase的Web管理界面:16010
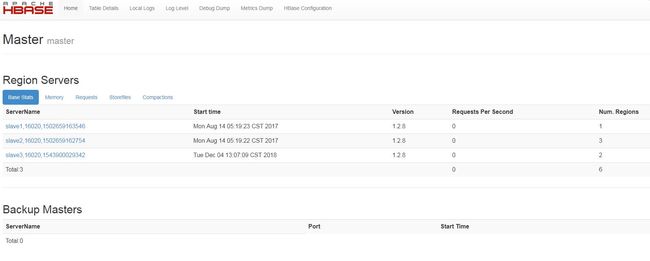
2.5 Kafka集群
本案例基于4台机器搭建Kafka集群:
- 安装包拷贝、解压
将压缩包拷贝至Linux系统中,移动到/usr/software/kafka目录下,并解压:
mv kafka_2.12-2.0.1.tgz /usr/software/kafka
tar -zxvf kafka_2.12-2.0.1.tgz
- 修改配置文件
cd /usr/software/kafka/kafka_2.12-2.0.1/config
vim vim server.properties
broker.id=0
listeners=PLAINTEXT://master:9092
# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3
# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
log.dirs=/usr/software/kafka/kafka_2.12-2.0.1/logs
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended for to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168
sage.max.byte=5242880
# 消息保存的最大值5M
default.replication.factor=3
# kafka保存消息的副本数,如果一个副本失效了,另两个还可以继续提供服务
replica.fetch.max.bytes=5242880
# 取消息的最大直接数
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=slave1:2181,slave2:2181,slave3:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
############################# Group Coordinator Settings #############################
# The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance.
# The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms.
# The default value for this is 3 seconds.
# We override this to 0 here as it makes for a better out-of-the-box experience for development and testing.
# However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup.
group.initial.rebalance.delay.ms=0
# 主要修改broker.id,log.dirs,zookeeper.connect
将配置好的hbase目录同步到另外3台机器,并修改配置文件中的broker.id。
- 启动
/usr/software/kafka/kafka_2.12-2.0.1/bin
./kafka-server-start.sh -daemon ../config/server.properties
- kafka manager安装
安装详情
kafka manager安装时默认的Web端口为9000,与hadoop的RPC端口冲突,故启动时需要指定另外一个端口号,如:
bin/kafka-manager -Dhttp.port=9002

欢迎您扫一扫上面的二维码,关注我的微信公众号!
更多内容请访问http://ruanshubin.top.