Mysql索引与sql执行计划
我们在前面探讨了Mysql索引是什么
这一节我们看下如何利用索引,及涉及到的sql执行计划
索引优化
执行计划
参考地址:MySQL
介绍
很多时候,我们想知道sql会怎么执行,那有没有办法呢?explain关键字!Mysql提供了这个关键字让我们优化索引,使查询更快;分析优化器的表连接,使它采用最优的顺序。
除此之外,explain还可以查看表结构
EXPLAIN tb_name等同于
DESCRIBE tb_name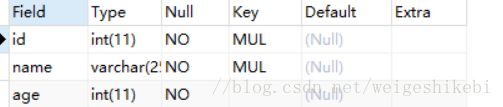
那么,我们就先来看看explain的相关属性

首先是id:
| id | 查询标识符;SELECT的查询序列号 |
| select_type | 可以为如下的其中一种 SIMPLE:简单查询(不是联合或者子查询) PRIMARY:最外层查询 UNION:union中的第二个或后面的语句 DEPENDENT UNION:union中的第二个或后面的语句,依赖外层查询 UNION RESULT:union的结果 SUBQUERY:第一个子查询 DEPENDENT SUBQUERY:第一个子查询,依赖外层查询 DERIVED:Derived table UNCACHEABLE SUBQUERY:每个子查询的结果不能被缓存并且需要重新评估 |
| table | 输出行所引用的表 |
| type | 表连接的类型,效率从高到低 system:表中只有一行记录,是const的特例 const:表中至多匹配一行,会被优化器当作常量处理,只读取一次就能得到。一般主键或者唯一索引 eq_ref:这是除了system,const以外最好的type类型了。比如主键或唯一索引关联 ref:对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取;比如最左匹配或者非主键、唯一索引;匹配的记录越少越好 fulltext:全文索引类型 range:范围查找,比如 index:同all相似,只是查找速度略快,根据索引查找,相应的Extra是Using index all:全表扫描,需要优化了... |
| possible_keys | 可能用到的索引 |
| key | mysql实际选择的索引。如果是从possible_keys中选择,则显示名称相同 |
| key_length | mysql选择键的长度 |
| ref | 哪些列或常数与key比较,用来从表中选择行 |
| rows | mysql分析执行语句必须检查的行。如果是innodb,这通常是一个估计值 |
| Extra | mysql提供的额外信息表明如何执行语句 |
下面我们通过实例来看下
首先建立2张表t1,t2
CREATE TABLE `t1` (
`id` int(11) NOT NULL,
`name` varchar(255) NOT NULL,
`age` int(11) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT '测试表1';CREATE TABLE `t2` (
`id` int(11) NOT NULL,
`name` varchar(255) NOT NULL,
`age` int(11) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT '测试表1';分别插入数据
INSERT INTO t1(name, age) values('tw1',20), ('tw2',22), ('tw3',23);INSERT INTO t2(name, age) values('kb1',20), ('kb2',22), ('kb3',23);简单查询
EXPLAIN SELECT * FROM
t1;
执行计划显示这是一个简单查询select_type=SIMPLE,并且type=ALL,全表扫描,rows=3,正好表里面有3条记录。接下来我们建一个索引。
ALTER TABLE t2
add PRIMARY KEY id_index (id);EXPLAIN SELECT * FROM
t1 WHERE id = 1;
执行计划显示索引这一列,PRIMARY主键索引,type=const,表明只有一条数据
联合查询
EXPLAIN SELECT t1.id FROM t1,t2
WHERE t1.id = t2.id
上面显示t1的type=eq_ref,
EXPLAIN SELECT * FROM t1
UNION
SELECT * FROM t2;

如果是Union,就会显示union,type=all,表明需要优化
范围查找
EXPLAIN SELECT * FROM t2
WHERE id BETWEEN 1 AND 3; type=range,因为id是范围查找,这些还包括in,>,<这些范围查找的操作符
type=range,因为id是范围查找,这些还包括in,>,<这些范围查找的操作符
普通索引(辅助索引)
EXPLAIN SELECT * FROM t2
WHERE name = 'kb';![]()
发现是走了name上的索引,这种比较依赖于查找的数据,比all-全表扫描略快,根据阿里开发手册上的说法,这种也是需要优化的,索引至少要到range级别。
那我们看一下优化索引呢
利用索引有序性
假设有一张表,记录用户购买记录
-- 用户购买记录表
CREATE TABLE `buy_log` (
`user_id` int(11) UNSIGNED NOT NULL,
`create_time` date
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='购买记录表'; 插入测试数据
-- 插入测试数据
INSERT INTO buy_log
VALUES (1, '2018-01-01'),(1, '2018-01-02'), (2, '2018-02-01'), (3, '2018-03-01');创建索引 ,user_id列索引,及联合索引
-- 创建索引
ALTER TABLE buy_log
add INDEX (user_id);
ALTER TABLE buy_log
add INDEX (user_id, create_time); 现在我们只对user_id查询一下
EXPLAIN SELECT * from buy_log
where user_id = 2; 看下执行计划
![]()
发现在可选的索引有2个:user_id,及联合索引user_id_2,但是优化器最终选择了user_id,因为该索引存放了单个键值,理论上一页存放的数据更多
接下来如果一个需求是,查询user_id=1的用户最新的购买记录,可能的sql如下
EXPLAIN SELECT * from buy_log
where user_id = 1 ORDER BY create_time desc LIMIT 1;
我们发现possible_keys是user_id,user_id_2,最终优化器选择了user_id_2。这是为什么呢?这是因为mysql联合索引的有序性,这个时候采用user_id_2,就不用额外的现做一次排序,因为索引存放已经是排序好的。
为了验证这个想法,我们强制采用索引user_id
-- 强制使用索引:force index xx
EXPLAIN SELECT * from buy_log FORCE INDEX (user_id)
where user_id = 1 ORDER BY create_time desc LIMIT 1;
执行计划显示,会Using filesort,会额外做一次文件排序,这是实际中我们要尽量避免
利用覆盖索引
上面说到了联合索引的有序性,比如(a,b,c),如下的sql都是可能直接获得的
select * from table where a = xx order b;
select * from table where a = xx and b=yy order c;但是对于sql
select * from table where a = xx order c;却不能直接得到,这就是所谓的最左原则,因为索引是按a,b,c排序的,所以直接根据a,c是不能直接定位的
但是下面这种情况却是例外
-- 统计购买记录
EXPLAIN SELECT count(*) from buy_log
where create_time > '2018-01-01';
发现在possible_keys为NULL,但是优化器选择了user_id_2,按刚才的分析,where条件应该走不到索引,这是为什么呢?
这就是覆盖索引的作用,因为我们只是按时间统计,并不用查找整行记录,所以选择覆盖索引,因为覆盖索引不用存储整行记录,索引远小于聚集索引,可以减少IO