本文来源于caoz梦呓公众号高并发专辑,以图形化、松耦合的方式,对互联网高并发问题做了详细解读与分析,“技术在短期内被高估,而在长期中又被低估”,而不同的场景和人员成本又导致了巨头的方案可能并不适合创业公司,那么如何保证高并发问题不成为创业路上的拦路虎,是每一个全栈工程师、资深系统工程师、有理想的程序员必备的技能,希望本文助您寻找属于自己的“成金之路”,发亮发光。
目录:
场景及解决方法解读
认识负载
数据跟踪
脑图、caoz大神公众号分享
参考资料
秉承知其然及其所以然的思路,以拨蝉拔丝的思维,一一解读各个技巧的使用场景:
a.网络通道+前台控制
原因:在当前浮躁社会的大前提下,用户点击一个按钮如果3s内没有反应,基本都会再次刷新,那么因为你网络通道不顺,原本可以正常得到数据,现在却因为延迟造成后台请求量倍增;而当用户因为没有数据而疯狂刷新时,你应该在前台有控制,比如“3秒间隔才能重新点击一个按钮、或者让用户可以疯狂点但是不发送请求(好像360曾经做过这个)”,控制用户不良操作。
方案:后台必须支持双网双通,保证南电信、北网通双边部署,玩过对战游戏的同学,应该都还记得,当初都是分电信专区和网通专区;同时在成本可以接受的范围内,尽量上CDN加速。
b.负载均衡
这个无须多说,但是科普下技术原理,主要难点是
环上节点分布均衡与
节点处理请求数均衡:
使用一致性Hash,全满状态时是长度为2^32(由Hash函数返回值类型决定)的环,服务器节点按名称Hash值放到环中,Web请求分配时根据IP Hash或者URL Hash值,路由到在环中距离最近的服务器上,进行请求应答。
1.服务器Hash值环用红黑树存储,且需要用CRC32_HASH、FNV1_32_HASH、KETAMA_HASH保证服务器Hash值
均匀分布在0到2^32之间,java.util.String的hashCode()则不行;
2.为保证单台服务器上处理请求数的
均衡性,则需要将一个物理服务器虚拟为n个虚拟节点(172.16.6.1:1\172.16.6.1:2...),对所有的虚拟节点构造环,以将一个实点拆为多个均匀分布代理点的方式,来保证请求分配的均衡性。
c.缓存、数据库、数据总线同步异步处理:
1.缓存
其起源于CPU与Memory Bank数据高速处理,将热数据保存进LRU队列中,提高CPU处理速度;
而此处的缓存则是对数据库中高频、小字段进行缓存,保证50%的命中率才值得缓存IO开销。
2.数据库
i.单表
查询慢时,基本由于过滤条件太多造成,使用联合索引加速过滤。索引使用树形结构,时间复杂度大概为lgN,log(10亿)=9,查询10亿数据只需9次单位操作时间,如果索引使用不上,则得先把所有数据查询出来,然后放到内存里,内存放不下,还得部分存储到磁盘里,最后再进行过滤。
另外,控制单次查询数据条数,从源头上进行流量控制,和地铁限流一个套路;另外,超级大的分页也不用考虑,Google、baidu、taobao搜索结果都没有超过100页的。
ii.多表关联表查询太慢
参见 MySQL百万级、千万级数据多表关联SQL语句调优详细的对多表关联的索引使用进行了分析。
iii.海量数据
此业务逻辑只能用单表处理,比如用户表登陆状态表、游戏操作记录表。
另,还可进行分表、分库,这块比较复杂,请自行参考参考资料a。
3.数据总线同步、异步处理:
这里说数据总线,因为目前数据处理基本都是松耦合,以消息驱动,如京东用的kafka、超级灵活性的Rabbitmq、淘宝的metaq:
如果是非核心的非实时性业务,比如排名与PageView数、lastact,可以定时驱动更新缓存队列:对于排名与PageView数,,汇总队列中所有消息,统一更新处理;对于lastact,则取最新的状态,进行更新即可;
同步实时处理时,尽可能的合并操作逻辑,多个操作一条SQL更新(基于同一主键查询、更新的比例多)。
c.从需求层面裁剪
一款好的产品必定让一部分尖叫,另一部分离开的产品;那么在需求层面进行裁剪,以较低的成本满足绝大多数人的使用,是非常合适的。
1.搜索大翻页的问题,百度、淘宝、Google查询结果限定在100页内,来避免使用count(1)计算总条数;
2.雪崩效应处理:缓存扛不住将负载传递给DB,带来过载,可以降级服务,将部分用户请求频次低,价值低但是系统开销不低的功能或者数据临时阻断停止响应,确保整体系统的稳定性;如微博过载暂停冷门订阅,避免全局崩溃;
2.雪崩效应处理:缓存扛不住将负载传递给DB,带来过载,可以降级服务,将部分用户请求频次低,价值低但是系统开销不低的功能或者数据临时阻断停止响应,确保整体系统的稳定性;如微博过载暂停冷门订阅,避免全局崩溃;
3.写主库、读从库的"主从库数据同步问题",提示用户延迟处理(操作完后后,提示3s自动返回),体验略有不好也不会有非常大的困扰。
解决高并发要有
思维宽度,能功能、使用、设计、数据库、缓存、OS各个层面去思考及其解决方法,深入的剖析的各个场景;同时针对高并发也要有一定的
技术深度,比如nio、epoll、java.util.concurrent包各类高效锁、 无锁操作,具备解决高并发的技术深度;但是离“成金之路”还有两个重要的点——高负载怎么定义及跟踪
a.定义:
1.构成:
CPU/内存开销,都有哪些进程和服务占用,SWAP分区大,IO必然低;
IO开销,服务读写频率;
2.增长趋势 线性增加、指数增加(无索引遍历)、收敛增加(支撑性最好);
3.系统阀值(CPU/IO/Mem不高但是请求一次)请求超越了OS阀值:如syn-flood连接占满,https超时太长导致https超过最大值;mysql链接越界;
4.峰谷的规律和预测 原因分析;
5.异常的监控和跟踪 异常比例不超过万分之几可以忽略,而千分之几就要去研究了。
2.增长趋势 线性增加、指数增加(无索引遍历)、收敛增加(支撑性最好);
3.系统阀值(CPU/IO/Mem不高但是请求一次)请求超越了OS阀值:如syn-flood连接占满,https超时太长导致https超过最大值;mysql链接越界;
4.峰谷的规律和预测 原因分析;
5.异常的监控和跟踪 异常比例不超过万分之几可以忽略,而千分之几就要去研究了。
b.跟踪
1.数据服务器:
1.1每分钟cron记录CPU监控,连接超过阀值256时记录,不用root用户(root用户比普通用户多一个连接,连接占满时用此链接进行排错);
1.2binlog分析:写入更新的日志,复制到线下机器mysqldump分析:每秒数据更新请求、更新请求最多的表、最多更新请求SQL格式、短时间大量重复主键更新;
1.3慢查询日志分析,explain
2.web服务器:
2.1web日志:打开执行时间监控,分析不同动态脚本执行频次及时间分布,找到时间长、频次高的;
2.2针对时间长、频次高的程序做埋点分析;
2.3SQL查询输出:调用汇总函数,分析每秒查询请求、最多查询表及SQL、是否同一主键大量重复查询;
2.4错误异常日志分析,极大警觉,发现SQL注入猜测;
2.5链接状态监控:当前web链接及消耗的资源,避免请求调用复杂框架形成雪崩。
3.内存、缓存服务器:
3.1链接状态和资源监控;
3.2命中率监控,命中率不高是设计问题,浪费资源。
4.通用监控:内存、CPU、磁盘、SWAP、系统资源(最大文件打开数、最大文件句柄数、syn连接数)占用监控。
5.自恢复系统:对技术不成熟、业务发展迅速平台是特别重要的处理思路,较低成本完成可靠服务,但是后续也要有跟进方案,进程为什么阻塞(数据库链接多、webserver链接过多,crontab清理阻塞的)。
6.监控系统资源占用:高负载尽量不要用netstat -an;埋点分析随机值抽取;定位到/dev/shm用内存而不是物理IO。
附上总结图片,图形化知识点,加深理解,祝各位走上自己的"成金之路"。
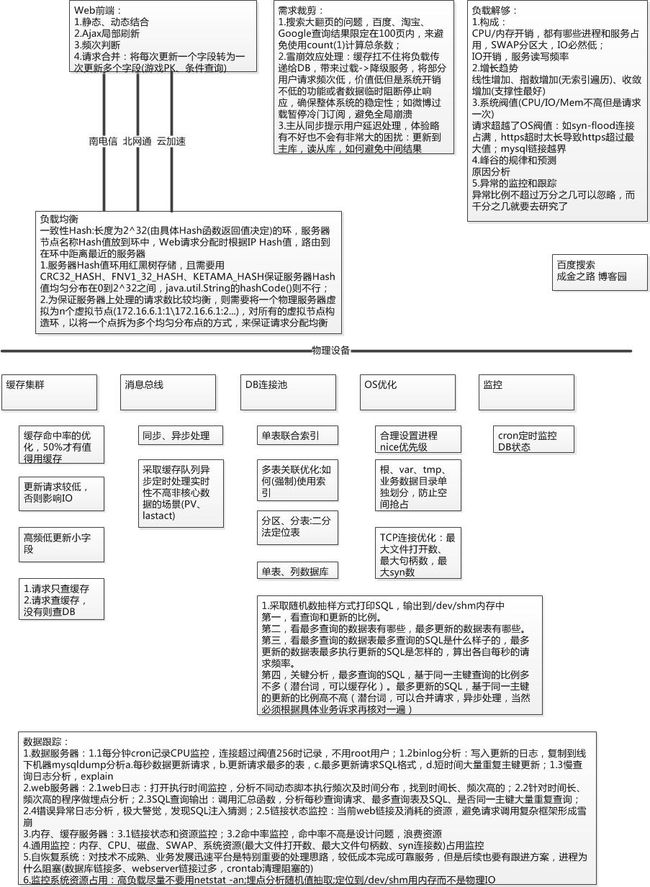
caoz的公众号

参考文档:
a. http://mp.weixin.qq.com/s__biz=MzI0MjA1Mjg2Ng==&mid=401465959&idx=1&sn=8d2116f8d238ccd208160d23f44dbb2c&mpshare=1&scene=1&srcid=0303IcaeoLiMDrg0FZuBZCjG#rd
b. http://www.cnblogs.com/xrq730/p/5186728.html
c. https://yq.aliyun.com/articles/59701
d. http://www.cnblogs.com/uttu/archive/2013/02/07/2908685.html