C正则
简介
第一部分:C/C++如何使用正则;
第二部分:正则介绍
第三部分:C中使用部分正则的函数(sccanf,sprintf等)
第一部分:C/C++如何使用正则
一.介绍:
核心: 标准的C和C++都不支持正则表达式,但函数库提供该功能:函数如下:
1)编译正则表达式 regcomp()
2)匹配正则表达式 regexec()
3)释放正则表达式 regfree()
4)获取regcomp 或者regexec 产生错误,获取包含错误信息的字符串
- 函数声明
int regcomp (regex_t *compiled, const char *pattern, int cflags)
参数1: regex_t *compiled—》一种特定的数据格式。
参数2: const char *pattern—》指定的正则表达式
参数3: 有如下4个值或者是它们或运算(|)后的值:
REG_EXTENDED 以功能更加强大的扩展正则表达式的方式进行匹配。
REG_ICASE 匹配字母时忽略大小写。
REG_NOSUB 不用存储匹配后的结果。
REG_NEWLINE 识别换行符,'$'从行尾开始匹配,'^'从行开头开始匹配。
作用: 将正则表达式编译成regex_t结构体格式。下面函数会处理编译的正则表达式。
返回值:成功返回0.
- int regexec (regex_t *compiled, char *string, size_t nmatch, regmatch_t matchptr [], int eflags)
作用: 使用编译好的正则表达式,进行匹配字符串—》找到想要的字符串
参数1: compiled 是用regcomp函数编译好的正则表达式。
参数2: string 是目标文本串。
参数3: nmatch 是regmatch_t结构体数组的长度。
参数4: matchptr regmatch_t类型的结构体数组,存放匹配文本串的位置信息。
即:用于把匹配结果返回给调用程序。
参数5:eflags 有两个值
取值1: REG_NOTBOL不匹配行的开头,除非在 regcomp 编译时 cflag 设置 REG_NEWLINE。
'^'匹配行的开头 , 不管 regexec 中是否设置 eflags 为 REG_NOTBOL 。
取值2: REG_NOTEOL不匹配行的结束,除非在 regcomp 编译时 cflag 设置
REG_NEWLINE 。'$' 匹配行的末尾 , 不管 regexec 中是否设置 eflags 为
REG_NOTEOL 。
返回值:执行成功返回0。
- void regfree (regex_t *compiled)
作用: 清空compiled指向regex_t结构体内容。如重新编译,一定先清空regex_t结构体。 - size_t regerror (int errcode, regex_t *compiled, char *buffer, size_t length)
作用:执行前两个函数产生错误的时候,就可调用该函数而返回包含错误信息的字符串。
参数1: errcode 是由regcomp 和 regexec 函数返回的错误代号。
参数2: compiled 是已经用regcomp函数编译好的正则表达式,这个值可以为NULL。
参数3:buffer 指向用来存放错误信息的字符串的内存空间。如果不需要,可为空
参数4: length 指明buffer的长度。如果该值小于错误信息长度:
函数会自动截断超出的字符串,但他仍然会返回完整的字符串的长度。
size_t length = regerror (errcode, compiled, NULL, 0);
添加头文件
#include
#include
第二部分:正则介绍
一.用于字符串操作
定义: 用事先定义好的特定字符组合,进行“字符串匹配”的规律逻辑 。
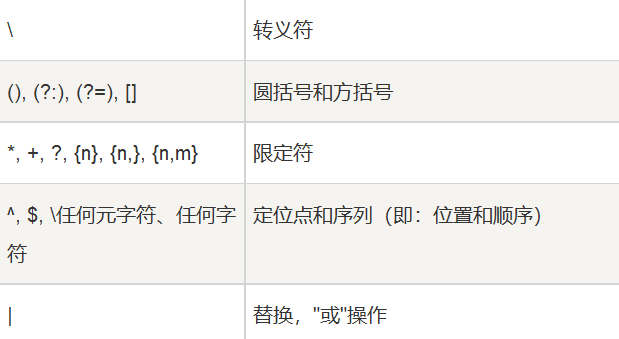
组成: 普通字符+ 元字符(特殊字符,限定符,定位符)
特殊字符—》特殊含义的字符
限定符------》限定出现的次数;
定位符-----》限定出现的位置;
1. 特殊字符
(1)$ 匹配输入字符串的结尾位置。要匹配 $ 字符本身,请使用 \$。
(2)( ) 标记一个子表达式的开始和结束位置。
(3)* 匹配前面的子表达式零次或多次。 要匹配 * 字符请使用 \*。
(4)+ 匹配前面的子表达式一次或多次。 要匹配 + 字符请使用 \+。
(5)? 匹配前面的子表达式零次或一次。要匹配 ? 字符请使用 \?。
(6). 匹配除换行符 \n 之外的任何单字符。要匹配 . 请使用 \. 。
(7)[ 标记一个中括号表达式的开始。 要匹配 [请使用 \[。
集合介绍:
[xyz] 匹配所包含的任意一个字符。
[^xyz] 匹配未包含的任意字符。
[a-z] 字符范围。匹配指定范围内的任意字符。
[^a-z] 负值字符范围。匹配任何不在指定范围内的任意字符。
(8)\ 转移字符,如:\? 就匹配到?
(9)^ (方括号外[])匹配输入字符串的开始位置;
(方括号内[])表示不接受该字符集合。要匹配 ^ 字符本身,请使用 \^。
(10){ 标记限定符表达式的开始。要匹配 {请使用 \{。
(11)| 指明两项之间的一个选择。要匹配 |请使用 \|。
例子:x|y 匹配 x 或 y。
2. 限定符(限定次数)有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m}
* 匹配前面的子表达式零次或多次。 * 等价于{0,}
+ 匹配前面的子表达式一次或多次。 + 等价于 {1,}
? 匹配前面的子表达式零次或一次。 ? 等价于 {0,1}
{n} 匹配确定的 n 次。
{n,} 至少匹配n 次。
{n,m} 其中n <= m。最少匹配 n 次且最多匹配 m 次。
例子:ZO* 可以匹配到Z,ZO,ZOO…,因为可以0次,即:不要前面的单个字符
3. 定位符(描述字符串或单词的边界)
^ 和 $ 分别指字符串的开始与结束,
\b 描述单词的前或后边界,
\B 表示非单词边界
4. 正则的优先级
5. 例子简介
(1)^[a-z][0-9]$ #重点是开头,结束定位符的使用。
首先:[]优先级最高,位置限定^$较低。
即:以一个字母开头 加一个数字结束。
注意:没有限定符,即一次,可以是s5,但不可以是s55。
(2)^[^0-9][0-9]$ #重点是[]内的^ 与 []外的^区别
首先:[]内的^ 是“排除”的意思,不是数字。加上[]外的^ :不以数字开头;
然后:以数字结束的两位字符。
(3)[^\\\/\^] 注意: \ 是转义字符, \\, \/, \^
即:除了(\)(/)(^)之外的所有字符
部分三. C支持正则的函数(部分支持)
一.sscanf
#include
int scanf(const char *format, ...);
int fscanf(FILE *stream, const char *format, ...); #文件输入
int sscanf(const char *str, const char *format, ...);(用于拆分字符串)
相同点:都是可变参数,都是输入函数—》按照一定形式存入到…部分。
不同点:输入原不同—》stdin(标准输入)输入;文件输入;字符串输入;
1. sscanf函数(从字符串提取数据):用于字符串操作!!
* 根据格式从字符串中提取数据。
* 取指定长度的字符串
* 取到指定字符为止的字符串
* 取仅包含指定字符集的字符串
* 取到指定字符集为止的字符串
(1)功能1: sscanf支持格式字符%[]
- 表示范围,如:%[1-9]表示只读取1-9这几个数字
%[a-z]表示只读取a-z小写字 注:遇到不是的停止。
char s[]="hello, my friend”; // 注意, 逗号在不 a-z 之间
sscanf( s, “%[a-z]”, string ) ; // string=hello
^ 表示不取,如:%[^1]表示读取除'1'以外的所有字符
%[^/]表示除/以外的字符
例子: 如果碰到 a-z 之间的字符则停止
char s[]="HELLOkitty” ;
sscanf( s, “%[^a-z]”, string ) ; // string=HELLO
, 范围可以用","相连接 如%[1-9,a-z]表示同时取1-9数字和a-z小写字母
* 表示不保存变量, 跳过此数据不读入. %*[^=] , %*s跳过符合条件的字符串。
char s[]="notepad=1.0.0.1001" ;
int i = sscanf( s, "%*[^=]", string ) ; #为NULL, 因为没保存
int i = sscanf( s, "%*[^=]=%s",string) ;
#为1.0.0.1001等号前不取,取等号后
(2)功能2 取指定长度的字符串—》取最大长度为4字节的字符串。
sscanf("123456 ", "%4s", buf);
printf("%s\n", buf); 结果为:1234
(3)功能3: 取到指定字符为止的字符串---》取遇到空格为止字符串。
sscanf("123456 abcdedf", "%[^ ]", buf); # 遇到空格结束
printf("%s\n", buf); 结果为:123456
(4)功能4: 取仅包含指定字符集的字符串---》取仅包含1到9和小写字母的字符串。
sscanf("123456abcdedfBCDEF", "%[1-9a-z]", buf);
printf("%s\n", buf); 结果为:123456abcdedf
注:遇到不在范围内的就结束
(5)功能5: 取到指定字符集为止的字符串---》取遇到大写字母为止的字符串。
sscanf("123456abcdedfBCDEF", "%[^A-Z]", buf);
printf("%s\n", buf); 结果为:123456abcdedf
历程1:给定一个字符串iios/12DDWDFF@122,获取 / 和 @ 之间的字符串,
先将 "iios/"过滤掉,再将非'@'的一串内容送到buf中
sscanf("iios/12DDWDFF@122", "%*[^/]/%[^@]", buf);
printf("%s\n", buf); 结果为:12DDWDFF
注:%s的结束条件—》遇回车(\n)或空格结束。
2. scanf()从控制台输入
int a,b,c;
printf("输入 a, b, c\n");
scanf("%d,%d,%d", &a, &b, &c);
3. fscanf 从文件输入,存入可变参数中
fscanf按照一定格式从文本中获取内容--》遇到空格和换行时结束(fgets遇到空格不结束)
FILE *fp;
char a[10]; int b; double c;
fscanf(fp,"%s%d%lf",a,&b,&c)
二.man printf 格式化输出
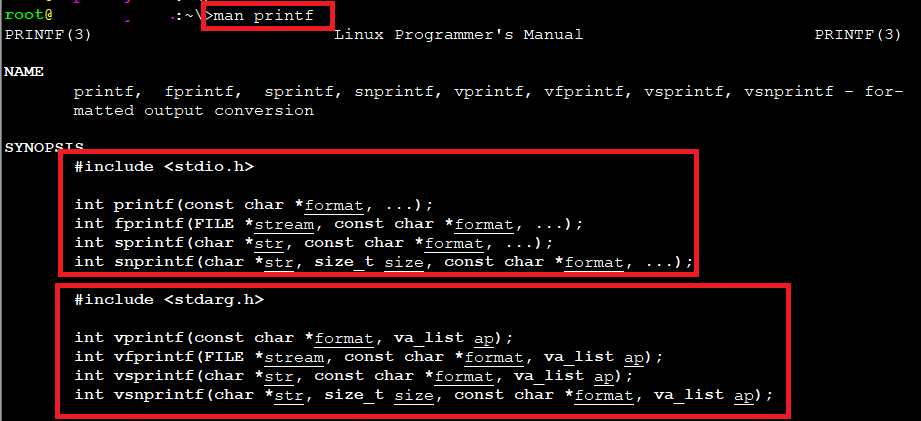
1. 格式化输出
共同点:将format后参数…按照format形式输出;
不同点: 输出到地方不同,分别--》stdout,文件,字符串中。
int printf(const char *format,***) #写入stdout
int fprintf(FILE *steam,const char *format,***) #写入文件
int sprintf(char *str,const char *format,***) #写入到字符串(参数1)中。
- sprintf的使用场景 :
场景1:格式化数字字符串--》 将整数转换为字符串。
场景2:连接字符串--》 组合新的字符串(将几个字符串合并连接)。
场景3: 控制浮点数打印格式
场景4: 打印地址信息
场景5: sprintf的返回值是本次调用打印到字符缓冲区中的字符数目
缺点: 可能出现问题内存溢出,第一个参数长度太短,导致出现内存溢出而程序崩溃。
改善: int snprintf(char *str, size_t n ,const char *format,*** )
#写入n个字符到字符串中。
函数说明:最多从源串中拷贝n-1个字符到字符缓冲区,然后在后面加一个 “\0” 。
函数返回值:若成功返回欲写入的字符串长度,出错返回负值。
注意点:返回值是欲写入的字符串长度,并不是实际写入缓冲区中的长度。
(1)输出格式
b 解释为整数并作为二进制输出
c 解释为整数并作为字符表示输出(ASCII码)
d 解释为整数并作为整数输出
e 解释为浮点数输出
f 解释为双精度并作为浮点数输出
o 解释为整数并作为八进制数输出
s 解释为字符串并为字符串输出
u 解释为无符号整数输出
g 解释自动选择合适的表示法
p 解释为指针的值 --》地址吗
x 解释为整数并作为带有小写字母a-f的十六进制数输出
X 解释为整数并作为带有大写字母A-F的十六进制数输出
1). 可以在%”和字母(样式)之间插进数字—》表示最大宽度。
%3d :表示输出3位整型数, 不够3位右对齐。
%9.2f :表示输出宽度9浮点数, 小数位2, 整数位6, 小数点一位, 不够右对齐。
%8s :表示输出8个字符的字符串, 不够8个字符右对齐。
注: 如果用浮点数表示—》字符或整型量的输出格式,:
小数点后的数字代表最大宽度,
小数点前的数字代表最小宽度。
例如: %6.9s 表示长度不小于6且不大于9字符串。若大于9, 则第9个字符后的内容将被删除。
2). 可以在”%”和字母之间加小写字母l, 表示输出的是长型数。
%ld: 表示输出long整数
%lf : 表示输出double浮点数
3).在”%”和字母之间加入一个”-” 号可说明输出为左对齐, 否则为右对齐。
%-7d: 表示输出7位整数左对齐
4). 一些特殊规定字符
①\n 换行 ②\f 清屏并换页 ③\r 回车 ④\t Tab符
(2)sprintf()使用
用途1: 格式化数字字符串,代替 itoa()
sprintf(s, “%d”, 123); # 产生”123”
可以指定宽度,不足的左边补空格:
sprintf(s, “%8d%8d”, 123, 4567); //产生:“ 123 4567”
也可以左对齐:
sprintf(s, “%-8d%8d”, 123, 4567); //产生:“123 4567”
用途2:控制浮点数打印格式(即:可控制浮点数的位数)
格式: ”%m.nf”,其中m 表示打印的宽度,n 表示小数点后的位数。
sprintf(s, “%10.3f”, 3.1415626); # 产生:” 3.142”
sprintf(s, “%.3f”, 3.1415626); # 不指定总宽度,产生:”3.142”
用途3: 连接字符串(替代strcat),且更强大
char* who = “I”;
char* whom = “you”;
sprintf(s, “%s love %s.”, who, whom); //要求:参数1的要足够大,不溢出
注:也可以前后都只取部分字符:
char a1[] = {‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’};
char a2[] = {‘H’, ‘I’, ‘J’, ‘K’, ‘L’, ‘M’, ‘N’};
sprintf(s, “%.6s%.5s”, a1, a2);//产生:”ABCDEFHIJKL”
注: 指定长度的数字可以是动态的,采用”*”来占用宽度或精度的常数位置
sprintf(s, “%.*s%.*s”, 7, a1, 7, a2);
用途4: 打印地址信息
间接地址打印: 十进制”%u” ,16 进制%x
直接地址打印%p: sprintf(s, “%p”, &i);
用途5: 利用sprintf 的返回值
返回值: 本次函数调用最终打印到字符缓冲区中的字符数目。
所以:其返回值就是偏移量,可以用于计数等,即写入的总长度:
offset += sprintf(s + offset, “%d,”, rand() % 100);
s[offset - 1] = ‘\n’;//将最后的逗号换成回车
- fprintf()的使用---》用于文件操作
int fprintf(FILE *stream, const char *format, ...) 发送格式化输出到流 stream 中
fp = fopen ("file.txt", "w+");
fprintf(fp, "%s %s %s %d", "We", "are", "in", 2014);
fclose(fp);
- 不定数量参数 的格式化输出
int vsprintf(char *string, char *format, va_list param);
例子如下:vsprintf 是sprintf 的一个变形,用于执行有不定数量参数的函数。
参数1: 用于保存结果的字符串缓冲区
参数2: 一个格式化字符串。
参数3: 是指向格式化参数队列的指针。va_list、va_start和va_end宏(STDARG.H)
char buffer[256];
int vsceshi(char *format, ...)
{
va_list aptr;
int ret;
va_start(aptr, format);
ret = vsprintf(buffer, format, aptr); //将结构存储到 buffer中
va_end(aptr);
return(ret);
}
调用如下:vsceshi("%d %s", i, str);
其余:略