提供推荐--集体智慧编程
背景:购物平台商品推荐算法介绍
数据:影评者对几部影片的打分情况,寻找人们在品味上的相似程度。通过相似度评价值进行推荐。评价值体系:欧几米德距离和皮尔逊相关度
critics = {‘Lisa Rose’:{‘Lady in the Water’:2.5,‘Snakes on a Plane’:3.5,‘Just My Luck’:3.0,‘Superman Returns’:3.5,‘You, Me and Dupree’:2.5,‘The Night Listener’:3.0},
‘Gene Seymour’:{‘Lady in the Water’:3.0,‘Snakes on a Plane’:3.5,‘Just My Luck’:1.5,‘Superman Returns’:5.0,‘The Night Listener’:3.0,‘You, Me and Dupree’:3.5},
‘Michael Phillips’:{‘Lady in the Water’:2.5,‘Snakes on a Plane’:3.0,‘Superman Returns’:3.5,‘The Night Listener’:4.0},
‘Claudia Puig’:{‘Snakes on a Plane’:3.5,‘Just My Luck’:3.0,‘The Night Listener’:4.5,‘Superman Returns’:4.0,‘You, Me and Dupree’:3.5},
‘Mick LaSalle’:{‘Lady in the Water’:3.0,‘Snakes on a Plane’:4.0,‘Just My Luck’:2.0,‘Superman Returns’:3.0,‘The Night Listener’:3.0,‘You, Me and Dupree’:2.0},
‘Jack Matthews’:{‘Lady in the Water’:3.0,‘Snakes on a Plane’:4.0,‘The Night Listener’:3.0,‘Superman Returns’:5.0,‘You, Me and Dupree’:3.5},
‘Toby’:{‘Snakes on a Plane’:4.5,‘You, Me and Dupree’:1.0,‘Superman Returns’:4.0}}
数学公式:
欧几米德距离:通过考察距离的远近来评价是否相似

Python代码:
from math import sqrt
def sim_distance(prefs,person1,person2):
#得到shared_items的列表
si={}
for item in prefs[person1]:
if item in prefs[person2]:
si[item]=1
if len(si)==0: return 0 #如果两者没有共同之处,则返回0
sum_of_squares= sum([pow(prefs[person1][item]-prefs[person2][item],2) #math.pow(100, 2) =10000
for item in prefs[person1] if item in prefs[person2]])
return 1/(1+sqrt(sum_of_squares)) #计算所有差值的平方和
sim_distance(critics, ‘Lisa Rose’, ‘Toby’) #0.348
sim_distance(critics, ‘Lisa Rose’, ‘Jack Matthews’) #0.340
越接近1,相似度越高。
皮尔逊相关度评价:两位影评者对电影的评价基本相同,但评分值

python代码:
def sim_pearson (prefs,person1,person2):
si={}
for item in prefs[person1]:
if item in prefs[person2]: si[item]=1
n=len(si)
if n==0:return 1
sum1=sum([prefs[person1][it] for it in si])
sum2=sum([prefs[person2][it] for it in si])
sum1Sq=sum([pow(prefs[person1][it],2)for it in si])
sum2Sq=sum([pow(prefs[person2][it],2)for it in si])
pSum=sum([prefs[person1][it]prefs[person2][it] for it in si])
num=pSum-(sum1sum2/n)
den=sqrt((sum1Sq-pow(sum1,2)/n)*(sum2Sq-pow(sum2,2)/n))
if den==0: return 0
r=num/den
return r
sim_pearson(critics, ‘Lisa Rose’, ‘Toby’) #0.99
sim_pearson(critics, ‘Lisa Rose’, ‘Jack Matthews’) #0.74
值越大相似度越高
为评论者打分:根据刚刚的皮尔逊相关系数,算出与Toby最相近的3个人推荐给Toby
def topMatches(prefs,person,n=5,similarity=sim_pearson):
scores=[(similarity(prefs,person,other),other) for other in prefs if other!=person]
scores.sort() #对列表进行排序,评价值最高者排在最前面
scores.reverse()
return scores[0:n]
topMatches(critics, ‘Toby’, n=3)#排名前3
[(0.9912407071619299, ‘Lisa Rose’),
(0.9244734516419049, ‘Mick LaSalle’),
(0.66284898035987, ‘Jack Matthews’)]
可以看出lisa和toby品味相近,可推荐lisa的影评给toby
推荐物品
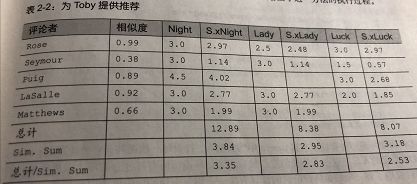
给toby提供推荐的计算步骤:先算出每个人和toby的相似度,
推荐值=(相似度评分值)总和/评论人数。推荐值高的可以推给toby
python 代码
def getRecommendations(prefs,person,similarity=sim_pearson):
totals={}
simSums={}
for other in prefs:
#不要和自己做比较
if other==person: continue
sim=similarity(prefs,person,other)
if sim<=0: continue #忽略评价值为零或小于零的情况
for item in prefs[other]:
#只对自己还未曾看过的影片进行评价
if item not in prefs[person] or prefs[person][item] == 0:
#相似度评价值
totals.setdefault(item,0)
totals[item]+=prefs[other][item]*sim
#相似度之和
simSums.setdefault(item,0)
simSums[item]+=sim
#建立一个归一化的列表
rankings=[(total/simSums[item],item) for item,total in totals.items()]
#返回经过排序的列表
rankings.sort()
rankings.reverse()
return rankings
getRecommendations(critics, ‘Toby’,similarity=sim_distance)
[(3.410726936917388, ‘The Night Listener’),
(2.778584003814924, ‘Lady in the Water’),
(2.38361164037425, ‘Just My Luck’)]
推荐值最高的三部电影就出来了。
基于物品的过滤
物品比较集:当像京东一样数以百万计商品时,按照上述方法计算,计算速度基本不能接受。由于物品间的比较不会像用户一样频繁,先建立物品间的加权列表。只有频繁执行该函数,才能令物品相似度不至于过期。随着用户的增长,物品间的相似度评价值会越来越稳定。
Python代码:
def calculateSimilarItems(prefs,n=10):
创建字典,以给出与这些物品最为相近的所有其他物品
result={}
itemPrefs=transformPrefs(prefs)
c=0
for item in itemPrefs:
# 针对大数据集更新状态变量
c+=1
if c%100==0: print ("%d / %d" % (c,len(itemPrefs)))
# 寻找最近相近的物品 scores=topMatches(itemPrefs,item,n=n,similarity=sim_distance)
result[item]=scores
return result
itemsim=calculateSimilarItems(critics)
itemsim
获得推荐
为toby提供基于物品的推荐
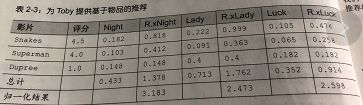
Python代码:
def getRecommendedItems(prefs,itemMatch,user):
userRatings=prefs[user]
scores={}
totalSim={}
循环遍历由当前用户评分的物品
for (item,rating) in userRatings.items( ):
#循环遍历与当前物品相似的物品
for (similarity,item2) in itemMatch[item]:
#如果该用户已对当前物品做过评价,则将其忽略
if item2 in userRatings: continue
# 评价值与相似度的加权之和
scores.setdefault(item2,0)
scores[item2]+=similarity*rating
# 全部相似度之和
totalSim.setdefault(item2,0)
totalSim[item2]+=similarity
合计加权值除以合计相似度
rankings=[(score/totalSim[item],item) for item,score in scores.items( )]
rankings.sort( )
rankings.reverse( )
return rankings
getRecommendedItems(critics,itemsim,‘Toby’)
[(2.9798348812430424, ‘The Night Listener’),
(2.9366294028444346, ‘Just My Luck’),
(2.868767392626467, ‘Lady in the Water’)]