ElasticSearch非权威完整指南
ElasticSearch非权威完整指南
原创博客不易,如若转载请注明来源。
如有错误及问题,欢迎评论指出。一起学习
文章目录
- ElasticSearch非权威完整指南
- 前言
- 感谢
- 技术栈说明
- 简介
- 带着问题上路 - ES是如何产生的?
- ES基础
- 什么是es
- lucene和es的关系
- es解决的问题
- es的工作原理
- es的核心概念
- 安装
- 快速开始
- 安装ik分词插件
- 集群搭建
- 集群管理
- 需要多大的集群规模
- 集群节点角色分配
- 防脑裂
- 索引分片数量设置
- 分片副本数量设置
- 性能优化
- 加大jvm内存分配
- 避免内存交换
- 分片策略
- 杀手锏:Filesystem Cache
- 数据预热
- 冷热分离
- 索引拆分
- 查询详解
- 查询Demo
- 集群状态
- 集群健康状态
- 集群节点状态
- 获取所有
- 复合查询
- 分页查询
- 指定返回的FIELD
- 排序
- 查询统计
- operator操作
- 精确度匹配
- 多FIELD匹配
- `range`查询
- `term`查询
- `terms`查询
- `exists` 查询和 `missing` 查询
- `match_phrase`查询
- `scroll`查询
- 通配符查询
- 正则表达式查询
- 前缀查询
- issues
- ES集群节点宕机导致shard unassigned解决方案
- 在springboot项目中使用需要制定es版本
- max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
- max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
- max virtual memory areas vm.max_map_count [65530] is too low
- at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes]...
- system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
前言
感谢
这里感谢,网络上的无名大佬的无私分享。我们正站在巨人的肩膀上!Standing on the shoulders of giants
- elastic官方文档
- ElasticSearch权威指南(翻译)
- ElasticSearch权威指南(pdf)
- <漫谈ElasticSearch>关于ES性能调优几件必须知道的事
- ES 在数据量很大的情况下如何提高查询效率
- 有赞搜索系统的技术内幕
- 超详细的Elasticsearch高性能优化实践
- ElasticSearch 按照一定规则分割index
- 有赞搜索系统的技术内幕
- ES集群管理|快乐成长
- Elasticsearch数据添加,查询
技术栈说明
简介
带着问题上路 - ES是如何产生的?
-
大规模数据如何检索?
如:当系统数据量上了10亿、100亿条的时候,我们在做系统架构的时候通常会从以下角度去考虑问题:
- 用什么数据库好?(mysql、sybase、oracle、达梦、神通、mongodb、hbase…)
- 如何解决单点故障;(lvs、F5、A10、Zookeep、MQ)
- 如何保证数据安全性;(热备、冷备、异地多活)
- 如何解决检索难题;(数据库代理中间件:mysql-proxy、Cobar、MaxScale等;)
- 如何解决统计分析问题;(离线、近实时)
-
传统数据库的应对解决方案
对于关系型数据,我们通常采用以下或类似架构去解决查询瓶颈和写入瓶颈:
- 通过主从备份解决数据安全性问题。
- 通过数据库代理中间件心跳监测,解决单点故障问题。
- 通过代理中间件将查询语句分发到多个slave节点,再对查询结果汇总
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T0oEHuuK-1589796555961)(http://minio.hujinwen.com/joe-data/pic-bed/2020-04-29/b952cdef2b29b20792e0ee51ac65b328.png)]
-
非关系型数据库的解决方案
对于Nosql数据库,以mongodb为例,其它原理类似:
- 通过副本备份保证数据安全性
- 通过节点竞选机制解决单点问题
- 先从配置库检索分片信息,然后将请求分发到各个节点,最后由路由节点合并汇总结果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9NRoNNj4-1589796555962)(http://minio1.hujinwen.com/joe-data/pic-bed/2020-04-29/0360ad43f52602fdf21837f5bcbbf0de.png)]
-
另辟蹊径 - 完全把数据放到内存会怎么样?
我们知道,完全把数据放在内存中是不可靠的,实际上也不太现实,当我们的数据达到PB级别时,按照每个节点96G内存计算,在内存完全装满的数据情况下,我们需要的机器是:1PB=1024T=1048576G
节点数=1048576/96=10922个
实际上,考虑到数据备份,节点数往往在2.5万台左右。成本巨大决定了其不现实!
从前面讨论我们了解到,把数据放在内存也好,不放在内存也好,都不能完完全全解决问题。
全部放在内存速度问题是解决了,但成本问题上来了。
为解决以上问题,从源头着手分析,通常会从以下方式来寻找方法:
- 存储数据时按有序存储;
- 将数据和索引分离;
- 压缩数据;
这就引出了Elasticsearch。
ES基础
什么是es
Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
lucene和es的关系
- Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
- Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能(索引的每个分片相当于一个lucene索引),但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单
es解决的问题
- 检索相关数据
- 返回统计结果
- 速度要快
es的工作原理
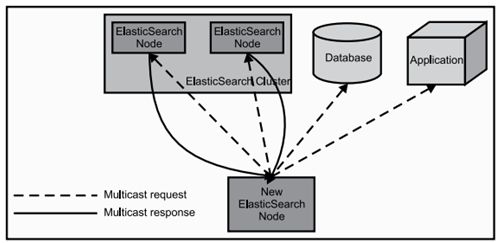
当ElasticSearch的节点启动后,它会利用多播(multicast)(或者单播,如果用户更改了配置)寻找集群中的其它节点,并与之建立连接。这个过程如下图所示:
es的核心概念
-
Cluster(集群)
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
-
Node(节点)
形成集群的每个服务器称为节点。
-
Index(索引)
数据存储在不同的索引中,类似于关系型数据库的database
-
Shard(分片)
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。 -
Replicas(副本)
索引副本,ES可以设置多个索引的副本,副本的作用一是提高系统的容错性,当个某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高ES的查询效率,ES会自动对搜索请求进行负载均衡。
-
Type
索引下的数据存储在不同的Type中,相当于关系型数据库中table。在es7.0之后,Type概念已被废弃。统一使用了
_doc类型,比较官方的说明如下:-
起初,我们说"索引"和关系数据库的“库”是相似的,“类型”和“表”是对等的。
这是一个不正确的对比,导致了不正确的假设。在关系型数据库里,"表"是相互独立的,一个“表”里的列和另外一个“表”的同名列没有关系,互不影响。但在类型里字段不是这样的。 -
在一个Elasticsearch索引里,所有不同类型的同名字段内部使用的是同一个lucene字段存储。也就是说,上面例子中,user类型的user_name字段和tweet类型的user_name字段是存储在一个字段里的,两个类型里的user_name必须有一样的字段定义。
-
这可能导致一些问题,例如你希望同一个索引中"deleted"字段在一个类型里是存储日期值,在另外一个类型里存储布尔值。
-
最后,在同一个索引中,存储仅有小部分字段相同或者全部字段都不相同的文档,会导致数据稀疏,影响Lucene有效压缩数据的能力。
因为这些原因,我们决定从Elasticsearch中移除类型的概念。
-
-
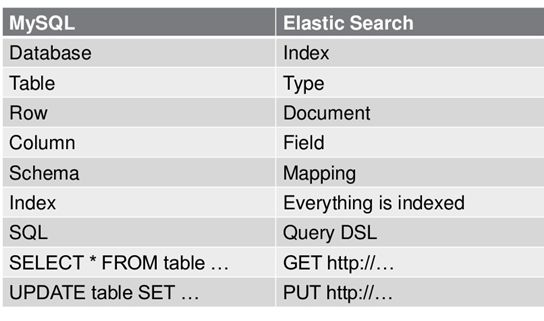
Document
每一条数据,相当于关系型数据库中的Row
-
Field
为数据定义的每一个字段,相当于关系型数据库的Column
附上es和关系型数据库的对比:
安装
快速开始
零配置,快速启动一个单机测试节点
-
去官网下载对应版本的ES -> 传送门
-
直接启动
cd elasticsearch-<version> ./bin/elasticsearch -
浏览器访问
http://<ip>:9200 -
出现以下界面即为成功
you know for search!
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-S2APx43I-1589796555965)(http://minio.hujinwen.com/joe-data/pic-bed/2020-05-18/d624ce7147727d5118cc7fa27f78b69d.png)]
安装ik分词插件
由于ES本身并不支持中文分词。所以需要我们安装中文分词插件。这里介绍比较热门的ik分词插件。
-
github中下载压缩包 -> 传送门
-
将下载的压缩包解压、重命名,并移动到
/plugins中 unzip elasticsearch-analysis-ik-7.1.0.zip -d analysis-ik mv analysis-ik ******/elasticsearch-7.1.0/plugins -
重启ES
-
可以在Kibana中测试分词效果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JECJBOTH-1589796555965)(http://minio.hujinwen.com/joe-data/pic-bed/2020-05-18/a8d8542bceb6dc92fcd2608b0c7cf5d6.png)]
-
IK分词插件还支持一些自定义配置,例如:
- 添加自定义词典
- 设置停用词
具体用法,还请自行了解。
集群搭建
这里只简单的介绍,搭建集群的方式和一些关键的配置。至于为什么及思路请看集群管理
# ---------------------------------- Cluster -----------------------------------
# 集群名称,相同集群名称的节点会组成一个集群
cluster.name: firstbrave-es
# ------------------------------------ Node ------------------------------------
# 节点名称
node.name: node-1
# 该节点是否有资格作为master节点
node.master: true
# 该节点是否作为data节点
node.data: true
# ----------------------------------- Paths ------------------------------------
# 数据存储位置(最好配置该参数,数据不要默认放在es的安装路径中)
path.data: /home/opt/fbitext/elasticsearch-7.6.2/data/data
# 日志文件路径(原因同上)
path.logs: /home/opt/fbitext/elasticsearch-7.6.2/data/log
# ----------------------------------- Memory -----------------------------------
# 禁用内存交换(es性能优化中非常重要的一个点)
bootstrap.memory_lock: true
# ---------------------------------- Network -----------------------------------
# 配置该节点ip
network.host: 10.0.0.27
# 配置该节点端口(在一台机器上,安装多个节点时,该参数起到区分的作用)
http.port: 9200
# --------------------------------- Discovery ----------------------------------
# 节点发现,节点通过该配置发现集群中的其他节点(注意端口配置,不要配成了默认的http端口9200)
discovery.seed_hosts: ["10.0.0.27:9300", "10.0.0.39:9300"]
# 初始化master节点(初始化master节点,将从这几个节点中推举)
cluster.initial_master_nodes: ["node-1", "node-2"]
# 防脑裂配置(集群部分中,最少存在多少个备选master节点,才会推举新的master节点)
discovery.zen.minimum_master_nodes: 1
集群管理
详细的解释在集群搭建过程中需要注意的问题(问题如下):
- 我们需要多大规模的集群?
- 集群中的节点角色如何分配?
- 如何避免脑裂?
- 索引应设置多少个分片?
- 分片应该设置几个副本?
需要多大的集群规模
-
我们需要从以下两个角度来考虑:
- 当前的数据量多大?数据增长情况如何?
- 机器配置如何?cpu?内存?硬盘容量?
-
推算的依据:
ES JVM heap 最大可以设置32G 。
30G heap 大概能处理的数据量 10 T。如果内存很大如128G,可在一台机器上运行多个ES节点实例。备注:集群规划满足当前数据规模+适量增长规模即可,后续可按需扩展。
-
两类应用场景:
- 用于构建业务搜索功能模块,且多是垂直领域的搜索。数据量级几千万到数十亿级别。一般2-4台机器的规模。
- 用于大规模数据的实时OLAP(联机处理分析),经典的如ELK Stack,数据规模可能达到千亿或更多。几十到上百节点的规模。
集群节点角色分配
-
节点分为哪些角色:
-
Master node
主节点。
普通服务器即可(CPU 内存 消耗一般)。
起到集群管理的作用。维护集群状态,索引创建、删除,索引的分片在节点中的分配。
配置文件中配置
node.master: true。表示该节点具有成为主节点的资格。具体角色会由多个具有主节点资格的节点选举产生。 -
Data node
数据节点。
主要消耗磁盘,内存。
配置文件中配置
node.data: true。表示该节点是否存储数据 -
Coordinate node
协调节点。
普通服务器即可(如果要进行分组聚合操作的话,建议这个节点内存也分配多一点)。
某个节点,上述两个配置均为false的情况,那么该节点即为协调节点。协调节点起到接收、转发请求,汇总节点返回的数据,等功能。
-
-
如何分配:
-
默认情况下,每个节点都有成为master、data、coordinate节点的资格。
-
小规模集群不需要严格区分。
-
中大规模集群(十个以上节点),应考虑单独的角色充当。
区分每个节点角色。角色分开的好处是分工分开,不互影响。例如不会因协调角色负载过高而影响数据节点的能力。分配时可如下考虑:- 设置3台以上(奇数个数,防止脑裂)的节点只作为master节点,这些节点只负责成为主节点,维护整个集群状态。(主节点对 CPU、内存 的消耗一般)
-
-
设置一批 data节点。这些节点负责存储数据,后期提供建立索引、查询搜索的功能。这些节点的压力较大(data节点,对内存、磁盘有一定的要求)
- 设置一批 coordinate节点。特别是在并发查询量大、查询的合并量大的时候。这些节点负责处理
用户请求,实现请求转发,负载均衡等功能。
- 设置一批 coordinate节点。特别是在并发查询量大、查询的合并量大的时候。这些节点负责处理
防脑裂
-
什么是脑裂
在es集群中,Master节点起着集群状态管理、分片分配的作用。
且Master节点是在所有有资格成为Master节点的节点中推举而来。
当集群中某些节点无法发现Master节点(可能是网络原因)。那么它就会重新推举新的Master节点。
这种一个集群中出现了多个Master节点的情况。我们称为
脑裂。会导致数据不统一、集群不可用。
-
如何避免,有以下几个要点
-
关键配置
discovery.zen.minimum_master_nodes: (有master资格节点数/2) + 1这个配置的作用是,在最少发现了几个Master候选节点的情况下,才推举Master节点。
这里配置为
有master资格节点数/2) + 1。所以在集群配置中设置奇数个数的资格节点
-
单播发现机制,配置master资格节点:
discovery.zen.ping.multicast.enabled: false —— 关闭多播发现机制,默认是关闭的
discovery.zen.ping.unicast.hosts: [“master1″, “master2″, “master3″] —— 配置单播发现的主节点ip地址,其他从节点要加入进来,就得去询问单播发现机制里面配置的主节点我要加入到集群里面了,主节点同意以后才能加入,然后主节点再通知集群中的其他节点有新节点加入。
-
配置选举发现数,及延长ping master的等待时长
discovery.zen.ping_timeout: 30(默认值是3秒)——其他节点ping主节点多久时间没有响应就认为主节点不可用了
discovery.zen.minimum_master_nodes: 2 —— 选举主节点时需要看到最少多少个具有master资格的活节点,才能进行选举
-
索引分片数量设置
分片数量一旦设定,不可更改。除非重建或拆分索引
-
思考
-
分片对应的存储实体是什么?
每个分片对应的存储实体是lucene索引。
-
分片是不是越多越好?
不是。
-
分片多有什么影响?
浪费存储空间、占用资源、影响性能。
-
-
分片过多的影响
-
每个分片本质上就是一个Lucene索引,因此会消耗对应的文件句柄、内存、CPU资源。
-
每个搜索请求会被调度到索引的每个分片中,如果分片分布在不同的节点(机器)上,那么问题不大。分片一旦在同一个节点(机器)上,便会竞争硬件资源,影响查询速度。
-
ES使用词频统计来计算相关性. 当然这些统计也会分配到各个分片上. 如果在大量分片上只维护了很少的数据, 则将导致最终的文档相关性较差。
-
-
应该为我们的索引设置多少个分片
- ElasticSearch推荐的最大JVM堆空间是30~32G, 所以把你的分片最大容量限制为30GB, 然后再对分片数量做合理估算。例如,你认为你的数据能达到200GB, 推荐你最多分配7到8个分片。
- 在开始阶段, 一个好的方案是根据你的节点数量按照1.5~3倍的原则来创建分片. 例如,如果你有3个节点, 则推荐你创建的分片数最多不超过9(3×3)个。当性能下降时,增加节点,ES会平衡分片的放置。
- 对于基于日期的索引需求, 并且对索引数据的搜索场景非常少. 也许这些索引量将达到成百上千, 但每个索引的数据量只有1GB甚至更小. 对于这种类似场景, 建议只需要为索引分配1个分片。如日志管理就是一个日期的索引需求,日期索引会很多,但每个索引存放的日志数据量就很少。
分片副本数量设置
分片副本的数量是可以随时调整的
-
思考
-
副本的作用是什么?
- 容灾,保证数据不丢失
- 高并发时参与数据查询
-
该如何设置它的副本数?
通常情况下,为分片设置一个副本即可满足数据高可用性的要求。
-
副本过多有什么影响?
过多的副本浪费空间、占用资源、影响性能。
-
-
副本设置的原则
创建新的副本时(分片同理)。主节点会对副本进行均衡分配。尽量保证副本不在同一个节点(机器)上
- 为保证数据高可用,副本数量设为1~2即可。
- 集群中至少需要有3个以上的节点,保证分片和副本被均衡分配在不同的节点上(如果设置了2个副本)。
- 如果发现并发量大,影响了查询效率。可适当的增加副本数量。来提升并发查询能力。
性能优化
详见官方文档
加大jvm内存分配
按照分片配比,详情见官方文档
vim config/jvm.options
避免内存交换
由于操作系统的虚拟内存页交换机制,会给性能带来障碍,如数据写满内存会写入Linux中的Swap分区。
vim config/elasticsearch.yml
# 设置
bootstrap.memory_lock: true
此时启动es会报错
ERROR: [1] bootstrap checks failed
[1]: memory locking requested for elasticsearch process but memory is not locked
需要切换到root权限做以下修改
vim /etc/security/limits.conf
# 添加以下内容,*号代表所有用户,可以指定为具体用户
* soft nofile 65536
* hard nofile 65536
* soft nproc 32000
* hard nproc 32000
* hard memlock unlimited
* soft memlock unlimited
vim /etc/systemd/system.conf
# 添加以下内容
DefaultLimitNOFILE=65536
DefaultLimitNPROC=32000
DefaultLimitMEMLOCK=infinity
执行使权限生效
systemctl daemon-reload
分片策略
选择合适的分片数和副本数。ES的分片分为两种,主分片(Primary Shard)和副本(Replicas)。默认情况下,ES会为每个索引创建5个分片,即使是在单机环境下,这种冗余被称作过度分配(Over Allocation),目前看来这么做完全没有必要,仅在散布文档到分片和处理查询的过程中就增加了更多的复杂性,好在ES的优秀性能掩盖了这一点。假设一个索引由一个分片构成,那么当索引的大小超过单个节点的容量的时候,ES不能将索引分割成多份,因此必须在创建索引的时候就指定好需要的分片数量。此时我们所能做的就是创建一个新的索引,并在初始设定之中指定这个索引拥有更多的分片。反之如果过度分配,就增大了Lucene在合并分片查询结果时的复杂度,从而增大了耗时,所以我们得到了以下结论:
我们应该使用最少的分片!
主分片,副本和节点最大数之间数量存在以下关系:
节点数<=主分片数*(副本数+1)
**控制分片分配行为。**以上是在创建每个索引的时候需要考虑的优化方法,然而在索引已创建好的前提下,是否就是没有办法从分片的角度提高了性能了呢?当然不是,首先能做的是调整分片分配器的类型,具体是在elasticsearch.yml中设置cluster.routing.allocation.type属性,共有两种分片器even_shard,balanced(默认)。even_shard是尽量保证每个节点都具有相同数量的分片,balanced是基于可控制的权重进行分配,相对于前一个分配器,它更暴漏了一些参数而引入调整分配过程的能力。
每次ES的分片调整都是在ES上的数据分布发生了变化的时候进行的,最有代表性的就是有新的数据节点加入了集群的时候。当然调整分片的时机并不是由某个阈值触发的,ES内置十一个裁决者来决定是否触发分片调整,这里暂不赘述。另外,这些分配部署策略都是可以在运行时更新的,更多配置分片的属性也请大家自行Google。
杀手锏:Filesystem Cache
你往 ES 里写的数据,实际上都写到磁盘文件里去了,查询的时候,操作系统会将磁盘文件里的数据自动缓存到 Filesystem Cache 里面去。
ES 的搜索引擎严重依赖于底层的 Filesystem Cache,你如果给 Filesystem Cache 更多的内存,尽量让内存可以容纳所有的 IDX Segment File 索引数据文件,那么你搜索的时候就基本都是走内存的,性能会非常高。
性能差距究竟可以有多大?我们之前很多的测试和压测,如果走磁盘一般肯定上秒,搜索性能绝对是秒级别的,1 秒、5 秒、10 秒。
但如果是走 Filesystem Cache,是走纯内存的,那么一般来说性能比走磁盘要高一个数量级,基本上就是毫秒级的,从几毫秒到几百毫秒不等。
这里有个真实的案例:某个公司 ES 节点有 3 台机器,每台机器看起来内存很多 64G,总内存就是 64 * 3 = 192G。
每台机器给 ES JVM Heap 是 32G,那么剩下来留给 Filesystem Cache 的就是每台机器才 32G,总共集群里给 Filesystem Cache 的就是 32 * 3 = 96G 内存。
而此时,整个磁盘上索引数据文件,在 3 台机器上一共占用了 1T 的磁盘容量,ES 数据量是 1T,那么每台机器的数据量是 300G。这样性能好吗?
Filesystem Cache 的内存才 100G,十分之一的数据可以放内存,其他的都在磁盘,然后你执行搜索操作,大部分操作都是走磁盘,性能肯定差。
归根结底,你要让 ES 性能好,最佳的情况下,就是你的机器的内存,至少可以容纳你的总数据量的一半。
根据我们自己的生产环境实践经验,最佳的情况下,是仅仅在 ES 中就存少量的数据,就是你要用来搜索的那些索引,如果内存留给 Filesystem Cache 的是 100G,那么你就将索引数据控制在 100G 以内。
这样的话,你的数据几乎全部走内存来搜索,性能非常之高,一般可以在1秒以内。
比如说你现在有一行数据:id,name,age … 30 个字段。但是你现在搜索,只需要根据 id,name,age 三个字段来搜索。
如果你傻乎乎往 ES 里写入一行数据所有的字段,就会导致说 90% 的数据是不用来搜索的。
结果硬是占据了 ES 机器上的 Filesystem Cache 的空间,单条数据的数据量越大,就会导致 Filesystem Cahce 能缓存的数据就越少。
其实,仅仅写入 ES 中要用来检索的少数几个字段就可以了,比如说就写入 es id,name,age 三个字段。然后你可以把其他的字段数据存在 MySQL/HBase 里,我们一般是建议用 ES + HBase 这么一个架构。
HBase 的特点是适用于海量数据的在线存储,就是对 HBase 可以写入海量数据,但是不要做复杂的搜索,做很简单的一些根据 id 或者范围进行查询的这么一个操作就可以了。
从 ES 中根据 name 和 age 去搜索,拿到的结果可能就 20 个 doc id,然后根据 doc id 到 HBase 里去查询每个 doc id 对应的完整的数据,给查出来,再返回给前端。
写入 ES 的数据最好小于等于,或者是略微大于 ES 的 Filesystem Cache 的内存容量。
然后你从 ES 检索可能就花费 20ms,然后再根据 ES 返回的 id 去 HBase 里查询,查 20 条数据,可能也就耗费个 30ms。
可能你原来那么玩儿,1T 数据都放 ES,会每次查询都是 5~10s,现在可能性能就会很高,每次查询就是 50ms。
数据预热
假如说,哪怕是你就按照上述的方案去做了,ES 集群中每个机器写入的数据量还是超过了 Filesystem Cache 一倍。
比如说你写入一台机器 60G 数据,结果 Filesystem Cache 就 30G,还是有 30G 数据留在了磁盘上。
其实可以做数据预热。举个例子,拿微博来说,你可以把一些大 V,平时看的人很多的数据,提前在后台搞个系统。
每隔一会儿,自己的后台系统去搜索一下热数据,刷到 Filesystem Cache 里去,后面用户实际上来看这个热数据的时候,他们就是直接从内存里搜索了,很快。
或者是电商,你可以将平时查看最多的一些商品,比如说 iPhone 8,热数据提前后台搞个程序,每隔 1 分钟自己主动访问一次,刷到 Filesystem Cache 里去。
对于那些你觉得比较热的、经常会有人访问的数据,最好做一个专门的缓存预热子系统。
**就是对热数据每隔一段时间,就提前访问一下,让数据进入 Filesystem Cache 里面去。**这样下次别人访问的时候,性能一定会好很多。
冷热分离
ES 可以做类似于 MySQL 的水平拆分,就是说将大量的访问很少、频率很低的数据,单独写一个索引,然后将访问很频繁的热数据单独写一个索引。
最好是将冷数据写入一个索引中,然后热数据写入另外一个索引中,这样可以确保热数据在被预热之后,尽量都让他们留在 Filesystem OS Cache 里,别让冷数据给冲刷掉。
你看,假设你有 6 台机器,2 个索引,一个放冷数据,一个放热数据,每个索引 3 个 Shard。3 台机器放热数据 Index,另外 3 台机器放冷数据 Index。
这样的话,你大量的时间是在访问热数据 Index,热数据可能就占总数据量的 10%,此时数据量很少,几乎全都保留在 Filesystem Cache 里面了,就可以确保热数据的访问性能是很高的。
但是对于冷数据而言,是在别的 Index 里的,跟热数据 Index 不在相同的机器上,大家互相之间都没什么联系了。
如果有人访问冷数据,可能大量数据是在磁盘上的,此时性能差点,就 10% 的人去访问冷数据,90% 的人在访问热数据,也无所谓了。
索引拆分
单索引存储的数据不宜多大,可再次对索引进行拆分。
# 根据日期进行数据拆分
POST _reindex?wait_for_completion=false
{
"source": {
"index": "index_name"
},
"dest": {
"index": "index_name-"
},
"script": {
"inline": "def sf = new SimpleDateFormat(\"yyyy-MM-dd'T'HH:mm:ss\");def o = new SimpleDateFormat(\"yyyy-MM-dd\");def dt = sf.parse(ctx._source.created_at);ctx._index='index_name-' + o.format(dt);"
}
}
# 按照 ID 范围,比如根据ID / 10000000取整,也就是1千万数据放一个index
POST _reindex?wait_for_completion=false
{
"source": {
"index": "index_name"
},
"dest": {
"index": "index_name-"
},
"script": {
"inline": "ctx._index='index_name-' + Long.valueOf(ctx._source.id / 10000000).toString();"
}
}
查询详解
查询Demo
# 创建index
PUT test_index
# 删除index
DELETE flume-6666
# 查询所有的index
GET _cat/indices
# 向指定index的type中POST数据
POST flume-2020-03-31/_doc
{
"content": "null"
}
# 向指定index的指定type的指定id中PUT进数据
PUT flume-2020-03-31/_doc/666
{
"content": "null"
}
# 查询所有数据
GET /flume-2020-03-31/_search
{
"query": {
"match_all": {}
}
}
# 根据index、type、id精确查找
GET /flume-2020-03-31/_doc/QMMjL3EB4usxco8zG808
# 替换一条数据
PUT /flume-2020-03-31/_doc/QMMjL3EB4usxco8zG808
{
"content": "null"
}
# 相似度匹配
GET /flume-2020-04-01/_search
{
"query": {
"match": {
"content": "2020-04-01 08:09:12.390"
}
}
}
# 包含匹配
GET /flume-2020-04-01/_search
{
"query": {
"query_string": {
"default_field": "content",
"query": "7e2c0f7b-64cc-482b-8990-9a78d4cd0254"
}
}
}
# 查询数据统计
GET /flume-2020-04-01/_count
{
"query": {
"match_all": {}
}
}
# 查看集群健康
GET /_cluster/health
集群状态
集群健康状态
GET /_cluster/health
集群节点状态
GET _nodes/stats
获取所有
GET /flume-*/_search
{
"query": {
"match_all": {}
}
}
复合查询
-
must
表示文档一定要包含查询的内容
-
must_not
表示文档一定不要包含查询的内容
-
should
表示文档如果匹配上可以增加文档相关性得分
GET /flume-2020-04-07/_search
{
"query": {
"bool": {
"must": [
{"match": {
"name": "phone"
}}
]
, "must_not": [
{"match": {
"color": "red"
}}
]
, "should": [
{"match": {
"price": 5000
}}
]
, "filter": {
"term": {
"label": "phone"
}
}
}
}
}
分页查询
不要进行深度分页,会有性能问题。
假设你的一个index有10个分片。分页每次取10条。
当取第一页时,会从每个分片取出10条,一共10*10=100条。再汇总,返回得分最高的10条。
当取第100页时,会从每个分片取出100*10=1000条,一共1000*10=10000条。再汇总。深度分页时查询速度会非常慢。
GET /flume-*/_search
{
"query": {
"match_all": {}
},
"from": 1,
"size": 2
}
指定返回的FIELD
GET /flume-*/_search
{
"query": {
"match_all": {}
},
"_source": ["name","price"]
}
排序
GET /ad/phone/_search
{
"query": {
"match": {
"ad": "white"
}
},
"sort": [
{
"price": {
"order": "asc"
}
}
]
}
查询统计
GET /flume-*/_count
{
"query": {
"match_all": {}
}
}
operator操作
match 查询还可以接受 operator 操作符作为输入参数,默认情况下该操作符是 or 。我们可以将它修改成 and 让所有指定词项都必须匹配
GET /flume-*/_search
{
"query": {
"match": {
"content": {
"query": "a red",
"operator": "and"
}
}
}
}
精确度匹配
match 查询支持 minimum_should_match 最小匹配参数, 可以指定必须匹配的词项数用来表示一个文档是否相关。我们可以将其设置为某个具体数字(指需要匹配倒排索引的词的数量),更常用的做法是将其设置为一个百分数,因为我们无法控制用户搜索时输入的单词数量
GET /flume-*/_search
{
"query": {
"match": {
"ad": {
"query": "a red",
"minimum_should_match": "2"
}
}
}
}
多FIELD匹配
多字段查询,比如查询color和ad字段包含单词red的文档
GET /ad/phone/_search
{
"query": {
"multi_match": {
"query": "red",
"fields": ["color","ad"]
}
}
}
range查询
范围查询,查询价格大于4000小于6000的文档
GET /ad/phone/_search
{
"query": {
"range": {
"price": {
"gt": 4000,
"lt": 6000
}
}
}
}
term查询
精确值查询,查询price字段等于6000的文档
GET /ad/phone/_search
{
"query": {
"term": {
"price": {
"value": "6000"
}
}
}
}
查询name字段等于phone 8的文档
GET /ad/phone/_search
{
"query": {
"term": {
"name": {
"value": "phone 8"
}
}
}
}
返回值如下,没有查询到名称为phone 8的文档
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 0,
"max_score": null,
"hits": []
}
}
为什么没有查到phone 8的这个文档那,这里需要介绍一下term的查询原理
term查询会去倒排索引中寻找确切的term,它并不会走分词器,只会去配倒排索引 ,而name字段的type类型是text,会进行分词,将phone 8 分为phone和8,我们使用term查询phone 8时倒排索引中没有phone 8,所以没有查询到匹配的文档
term查询与match查询的区别
term查询时,不会分词,直接匹配倒排索引match查询时会进行分词,查询phone 8时,会先分词成phone和8,然后去匹配倒排索引,所以结果会将phone 8和xiaomi 8两个文档都查出来
还有一点需要注意,因为term查询不会走分词器,但是回去匹配倒排索引,所以查询的结构就跟分词器如何分词有关系,比如新增一个/ad/phone类型下的文档,name字段赋值为Oppo,这时使用term查询Oppo不会查询出文档,这时因为es默认是用的standard分词器,它在分词后会将单词转成小写输出,所以使用oppo查不出文档,使用小写oppo可以查出来
GET /ad/phone/_search
{
"query": {
"term": {
"name": {
"value": "Oppo" //改成oppo可以查出新添加的文档
}
}
}
}
terms查询
terms查询与term查询一样,但它允许你指定多直进行匹配,如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件
GET /ad/phone/_search
{
"query": {
"terms": {
"ad": ["red","blue"]
}
}
}
exists 查询和 missing 查询
用于查找那些指定字段中有值 (exists) 或无值 (missing) 的文档
-
指定
name字段有值GET /ad/phone/_search { "query": { "bool": { "filter": { "exists": { "field": "name" } } } } } -
指定
name字段无值GET /ad/phone/_search { "query": { "bool": { "filter": { "missing": { "field": "name" } } } } }
match_phrase查询
短语查询,精确匹配,查询a red会匹配ad字段包含a red短语的,而不会进行分词查询,也不会查询出包含a 其他词 red这样的文档
GET /ad/phone/_search
{
"query": {
"match_phrase": {
"ad": "a red"
}
}
}
scroll查询
类似于分页查询,不支持跳页查询,只能一页一页往下查询,scroll查询不是针对实时用户请求,而是针对处理大量数据,例如为了将一个索引的内容重新索引到具有不同配置的新索引中
POST /ad/phone/_search?scroll=1m
{
"query": {
"match_all": {}
},
"size": 1,
"from": 0
}
返回值包含一个 "_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAAAQFlV6T3VqY2NaVDBLRG5uZXdiZ0hFYUEAAAAAAAAAERZVek91amNjWlQwS0RubmV3YmdIRWFBAAAAAAAAABIWVXpPdWpjY1pUMEtEbm5ld2JnSEVhQQAAAAAAAAATFlV6T3VqY2NaVDBLRG5uZXdiZ0hFYUEAAAAAAAAAFBZVek91amNjWlQwS0RubmV3YmdIRWFB"
下次查询的时候使用_scroll_id就可以查询下一页的文档
POST /_search/scroll
{
"scroll" : "1m",
"scroll_id" : "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAAAYFlV6T3VqY2NaVDBLRG5uZXdiZ0hFYUEAAAAAAAAAGRZVek91amNjWlQwS0RubmV3YmdIRWFBAAAAAAAAABYWVXpPdWpjY1pUMEtEbm5ld2JnSEVhQQAAAAAAAAAXFlV6T3VqY2NaVDBLRG5uZXdiZ0hFYUEAAAAAAAAAFRZVek91amNjWlQwS0RubmV3YmdIRWFB"
}
通配符查询
{
'query':{
'wildcard':{
'title':'cr?me'
}
}
}
正则表达式查询
{
'query':{
'regex':{
'title':{
'value':'cr.m[ae]',
'boost':10.0
}
}
}
}
前缀查询
{
'query':{
'match_phrase_prefix':{
'title':{
'query':'crime punish',
'slop':1
}
}
}
}
issues
ES集群节点宕机导致shard unassigned解决方案
-
查看文档
- ES集群节点宕机导致shard unassigned解决方案
- ES 集群不健康red解决办法
-
总结一下
- 查看原因
- 手动routing分配分片
在springboot项目中使用需要制定es版本
7.6.1
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
- 参考文档
vim /etc/security/limits.conf
# 添加如下配置,* 代表所有用户。也可指定某个用户
* soft nofile 65536
* hard nofile 65536
# 执行如下命令生效
sysctl -p
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
- 参考文档
vim /etc/security/limits.conf
# 添加如下配置,* 代表所有用户,也可配置为指定某个用户
* soft nproc 4096
* hard nproc 4096
# 执行如下命令生效
sysctl -p
max virtual memory areas vm.max_map_count [65530] is too low
- 参考文档
# 编辑配置文件
vi /etc/sysctl.conf
# 添加配置
vm.max_map_count=655360
# 让配置生效
sysctl -p
at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes]…
- 参考文档
# 编辑配置文件
vim config/elasticsearch.yml
# 修改
cluster.initial_master_nodes: ["node-1"]
system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
-
原因:
这是在因为Centos6不支持SecComp,而ES5.2.0默认bootstrap.system_call_filter为true进行检测,所以导致检测失败,失败后直接导致ES不能启动。 -
解决:
在elasticsearch.yml中配置bootstrap.system_call_filter为false,注意要在Memory下面: -
查看 issues
https://github.com/elastic/elasticsearch/issues/22899
bootstrap.memory_lock: false
bootstrap.system_call_filter: false