Kylin Cube调优
文章目录
- kylin如何确定指标和维度?
- SQL和Cube之间的关系??
- 为什么极大的提高了效率?
- Kylin的工作原理
- N个维度,随机组合可能出现的组合方式有多少种???
- 技术架构
- 理解Cube、Cuboid与Segment的关系
- 全量和增量的区别
- 管理Cube碎片(Segment)
- 使用JDBC连接操作Kylin
kylin如何确定指标和维度?
按照订单渠道名称统计订单总额/总数量
哪个是指标??总额/总数量
哪个是维度??渠道
select
t2.channelid,
t2.channelname,
sum(t1.price) as total_money,
sum(t1.amount) as total_amount
from
dw_sales t1
inner join dim_channel t2
on t1.channelid = t2.channelid
group by t2.channelid, t2.channelname
指标:select后面的:
sum(t1.price) as total_money,
sum(t1.amount) as total_amount
维度:group by后面的:
t2.channelid, t2.channelname
SQL和Cube之间的关系??
1、根据什么写SQL?? 需求
需求决定SQL
2、数据仓库员基于Hive,为什么不用hive直接推介用户/领导(线上系统)
Hive效率慢
3、Hive特别慢,怎么解决慢的问题???
想办法加速查询效率!!
Kylin就是加速Hive查询效率的有效手段。
最终:SQL是确定,不能变的。加速查询效率使用kylin。
所以:根据SQL创建Cube(Cube来源于SQL,辅助SQL),先有sql后有cube
为什么极大的提高了效率?
原因是,kylin将业务需要的数据全局提前计算出来,并保存。当用户查询时,直接在计算的结果中读取,不需要重新计算。
没有使用kylin前,SQL是需要计算的。
有使用kylin后,SQL不需要计算,变成了查询的。
好处:查询速度快
弊端:需要花费时间提前预计算。

Kylin的工作原理
维度就是观察数据的角度,通常是SQL中的group by后面的字段
度量就是被聚合的统计值,也是聚合运算的结果,通常是SQL中的select 后面的字段经过聚和的结果。
N个维度,随机组合可能出现的组合方式有多少种???
2的N次方-1, N代表维度的个数。
在kylin中没有维度也算一个维度,所以2的N次方。
每一种维度的组合(12,24,124,3)称为Cuboid(立方形)

所有维度组合的Cuboid作为一个整体,被称为Cube(立方体)

一个数据表或数据模型上的字段就它们要么是维度,要么是度量(可以被聚合)
工作原理是对数据模型做Cube预计算,并利用计算的结果加速查询
工作过程如下。
1.指定数据模型,定义维度和度量
2.预计算Cube,计算所有Cuboid并保存为物化视图(存储到hbase中)
3.执行查询时,读取Cuboid,运算,产生查询结果
技术架构
Apache Kylin系统可以分为在线查询和离线构建两部分。
在线查询

离线构建


理解Cube、Cuboid与Segment的关系
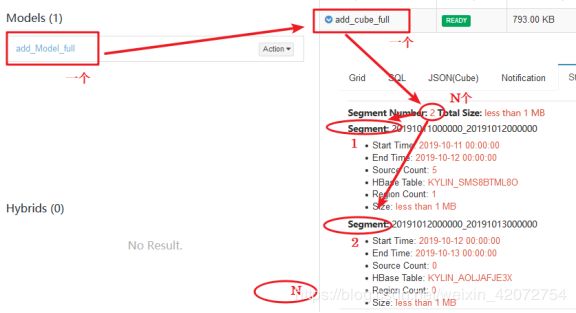
Kylin将Cube划分为多个Segment(对应就是HBase中的一个表),每个Segment用起始时间和结束时间来标志(全量数据使用FULL_BUILD)。Segment代表一段时间内源数据的预计算结果。
全量和增量的区别
全量构建Cube
查询引擎只需向存储引擎访问单个Segment所对应的数据,无需进行Segment之间的聚合
增量构建Cube
由于不同时间的数据分布在不同的Segment之中,查询引擎需要向存储引擎请求读取各个Segment的数据
增量构建的Cube上的查询会比全量构建的做更多的运行时聚合,通常来说增量构建的Cube上的查询会比全量构建的Cube上的查询要慢一些。
小数据量的Cube,或者经常需要全表更新的Cube,使用全量构建。
对于大数据量的Cube,包含两年历史数据的Cube,如果需要每天更新使用增量构建。

在全量构建中,Cube中只存在唯一的一个Segment,
增量构建只会导入新Segment指定的时间区间内的原始数据,并只对这部分原始数据进行预计算。

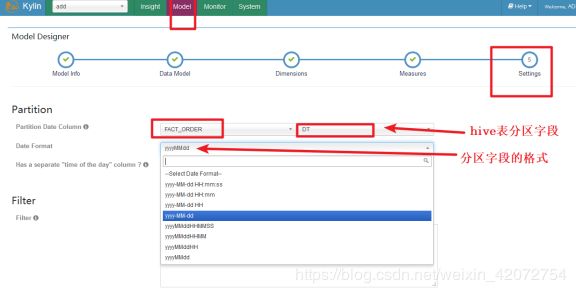
创建cube结束后,在build时设置计算数据的日期

第一天同步成功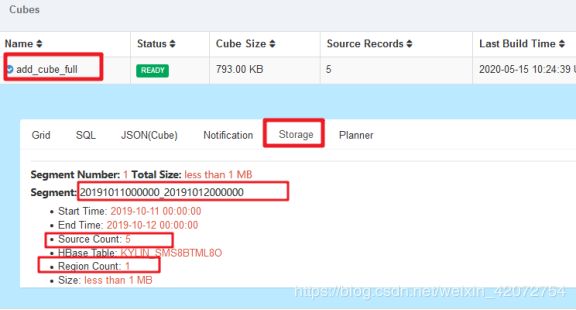
新计算下一个日期的数据


根据层量同步方案,得出一个结论。结论:每天成成一个Segment,一年就有365个Segment。
当用户查询时,系统不知道数据在哪个Segment中,所以需要扫描所有的Segment(扫描356个表),扫描多个表/多个Segment会降低数据查询效率。【增量方案带来的问题】
补充:文件越多效率越慢。
1个文件10G和10000个文件共10G 读取一个文件更快(寻址开销、频繁发开关闭)
一个文件夹内的文件特别多,这个文件夹打开的时间就会特别长。【xxxxxx卫星应用中心】
当系统越来越慢,越来越慢,越来越慢,越来越慢,有可能是某一个目录中的数据没有及时的清空或删除。
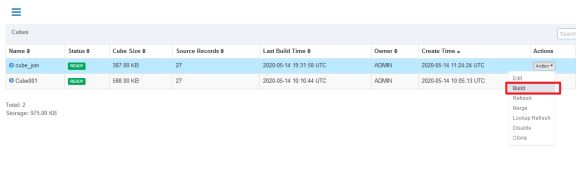
管理Cube碎片(Segment)
方案:(目标:减少Segment的数量)
合并Segment!
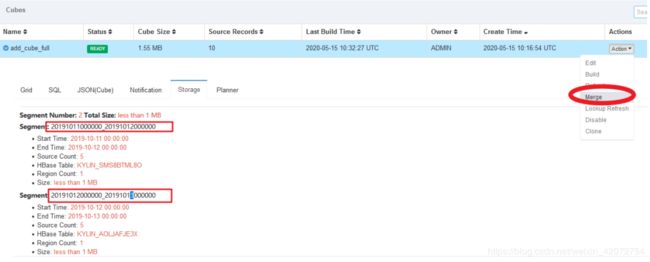
手动合并
选中需要合并的Segment,可以同时合并多个Segment,但是这些Segment必须是连续的
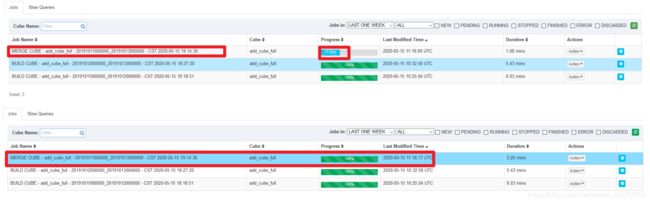
合并过程中不允许提交这个Cube上任何类型的其他构建任务,但是合并的Segment仍然处于可用的状态。

自动合并
合并逻辑:一个segment可以存储一天的数据也可以存储多天的数据,数据内的天数达到了阈值就跳过,没有达到阈值就合并到这个阈值,没满足不合并。

如果不合并,就会产生N个天的segment,合并就会大大减少segment的数量。
部署
设置阈值,可以使一个也可以使多个。


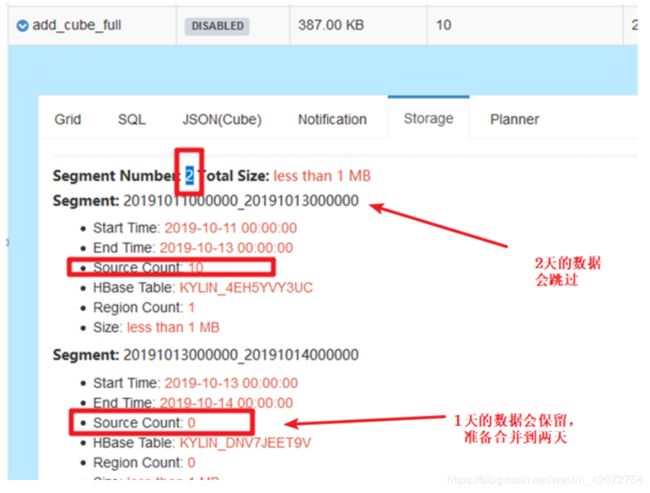
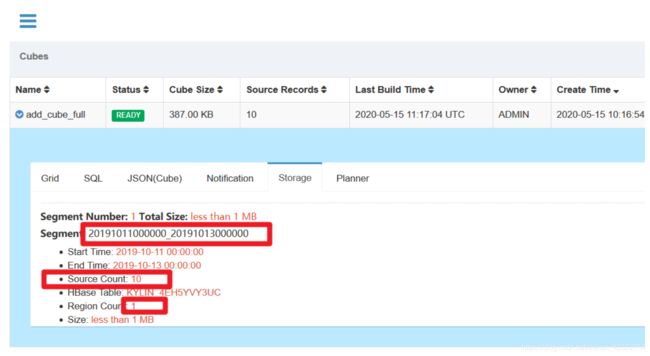
运行完毕以后,生成一天的数据
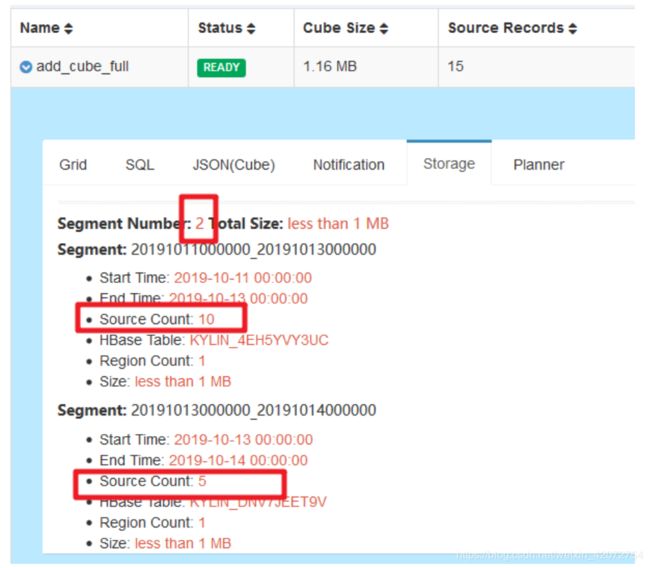
提交下一个一天的数据(1014-1015)

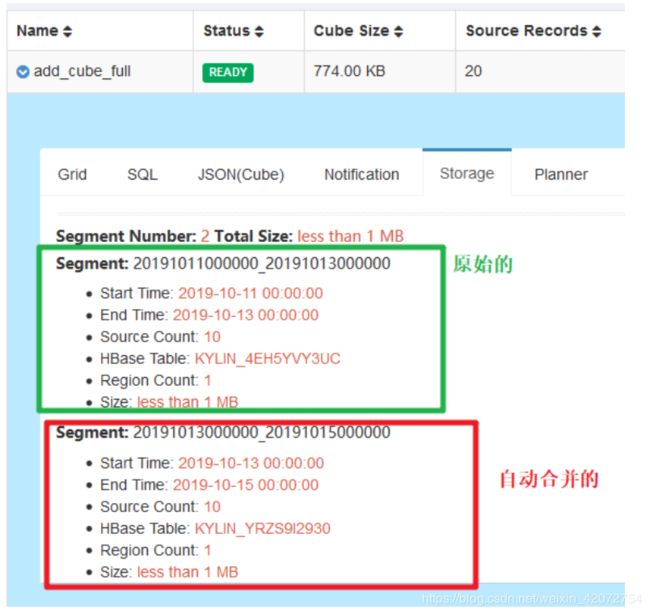
若设置多层次的合并级别,最好是每个层次之间是整倍数关系
删除Segment!
手动删除
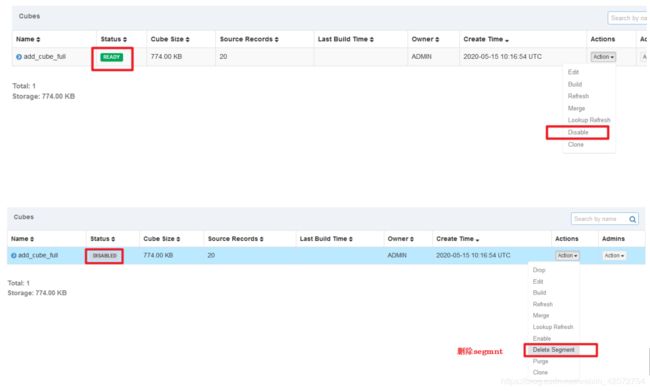

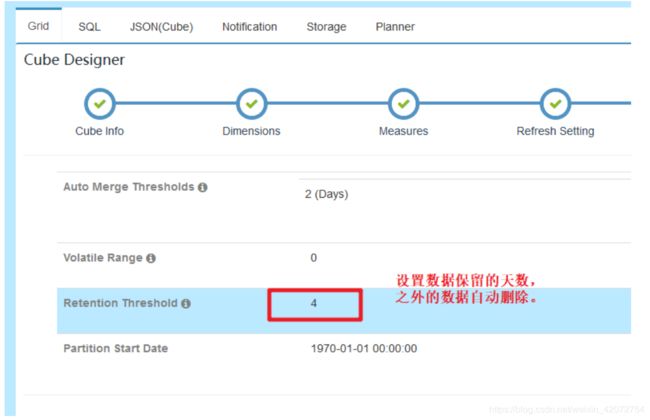
自动删除
使用JDBC连接操作Kylin
使用JDBC链接kylin直接使用。不需要关注kylin中model的名称cube的名称,以及两者之间的关系
import java.sql.*;
public class KylinDemo {
public static void main(String[] args) throws Exception {
// 1、加载驱动
Class.forName("org.apache.kylin.jdbc.Driver");
// 2、创建Connection连接对象
// 连接字符串:jdbc:kylin://ip地址:7070/项目名称(project)
// demo01:kylin中Project的名称
Connection connection = DriverManager.getConnection("jdbc:kylin://node01:7070/demo01",
"ADMIN",
"KYLIN");
// 3、创建Statement对象,并执行executeQuery,获取ResultSet
Statement statement = connection.createStatement();
// 构建SQL和语句
String sql = "select\n" +
"t2.channelid,\n" +
"t2.channelname,\n" +
"sum(t1.price) as total_money,\n" +
"sum(t1.amount) as total_amount\n" +
"from \n" +
"dw_sales t1\n" +
"inner join dim_channel t2\n" +
"on t1.channelid = t2.channelid\n" +
"group by t2.channelid, t2.channelname\n";
ResultSet resultSet = statement.executeQuery(sql);
// 4、打印ResultSet
while(resultSet.next()) {
// 4.1 渠道ID
String date1 = resultSet.getString("channelid");
// 4.2 渠道名称
String regionname = resultSet.getString("channelname");
// 4.3 总金额
String productname = resultSet.getString("total_money");
// 4.4 总数量
String total_money = resultSet.getString("total_amount");
System.out.println(date1 + " " + regionname + " " + productname + " " + total_money );
}
connection.close();
}
}