用labelme制作自己的语义分割数据集
用labelme制作自己的语义分割数据集
最近打算做一个自己的语义分割数据集,故在此记录一下自己的制作过程,
希望能帮助到后面的人。
我是Windows8.1,事先采集两张图作为范例,用来演示整个过程。
1.安装anaconda
Anaconda 官网下载地址:https://www.anaconda.com/download/
根据自己的需求选择下载对应的程序。
安装指令正常安装就好了
安装过程可以参考:https://zhuanlan.zhihu.com/p/61639212
2.安装labelme
按win+R 或者打开“运行” 输入“cmd”就可以打开了指令窗口。
先进入你的anaconda的虚拟环境,输入:
pip install labelme
安装好了就可以使用了
直接在虚拟环境中 输入 labelme就可以调用了。
下面是标注的过程:
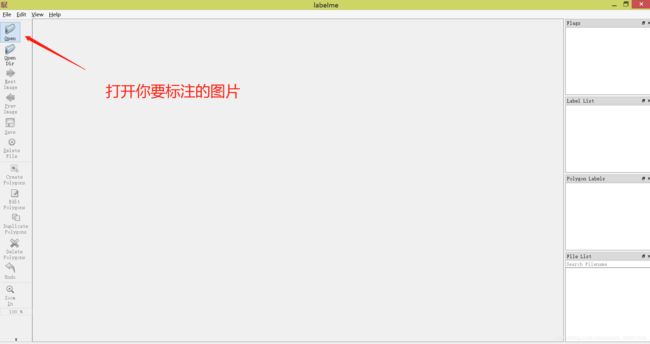

然后点击右侧工具栏的“保存”,就可以保存成**.json**格式的文件。
我将事先准备的两幅图都进行标注,生成如下的json文件
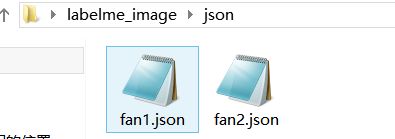
3.将json文件转换成分割的可视化图像
在你安装labelme文件下有一个json_to_dataset.py文件
我的文件位置在:
E:\Anaconda2\Lib\site-packages\labelme\cli\json_to_dataset.py
执行以下python指令:
python json_to_dataset.py D:\json\fan1.json D:\json\output
其中,json_to_dataset.py是自带的py文件,D:\json\fan1.json是我保存的json文件路径,D:\json\output是我要保存输出的文件路径。
根据你的具体路径去改变,以下是生成的结果:
4.批量转换json文件
上面的步骤是转换单个json文件,但我们在制作数据集的时候,如果一个个转换json文件是很耗时间的也没有这个必要。所以需要对python文件进行修改
import argparse
import json
import os
import os.path as osp
import warnings
import copy
import numpy as np
import PIL.Image
from skimage import io
import yaml
from labelme import utils
def main():
parser = argparse.ArgumentParser()
parser.add_argument('json_file')
parser.add_argument('-o', '--out', default=None)
args = parser.parse_args()
json_file = args.json_file
list = os.listdir(json_file)
for i in range(0, len(list)):
path = os.path.join(json_file, list[i])
filename = list[i][:-5] # .json
if os.path.isfile(path):
data = json.load(open(path))
img = utils.image.img_b64_to_arr(data['imageData'])
lbl, lbl_names = utils.shape.labelme_shapes_to_label(img.shape, data['shapes']) # labelme_shapes_to_label
captions = ['%d: %s' % (l, name) for l, name in enumerate(lbl_names)]
lbl_viz = utils.draw.draw_label(lbl, img, captions)
out_dir = osp.basename(list[i]).replace('.', '_')
out_dir = osp.join(osp.dirname(list[i]), out_dir)
if not osp.exists(out_dir):
os.mkdir(out_dir)
PIL.Image.fromarray(img).save(osp.join(out_dir, '{}.png'.format(filename)))
#PIL.Image.fromarray(lbl).save(osp.join(out_dir, '{}_gt.png'.format(filename)))
utils.lblsave(osp.join(out_dir, '{}_gt.png'.format(filename)), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, '{}_viz.png'.format(filename)))
with open(osp.join(out_dir, 'label_names.txt'), 'w') as f:
for lbl_name in lbl_names:
f.write(lbl_name + '\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=lbl_names)
with open(osp.join(out_dir, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
print('Saved to: %s' % out_dir)
if __name__ == '__main__':
main()
将这个代码替换到你的json_to_dataset.py里的内容,然后保存。
其中:
#PIL.Image.fromarray(lbl).save(osp.join(out_dir, ‘{}_gt.png’.format(filename))) 是生成灰度图
utils.lblsave(osp.join(out_dir, ‘{}_gt.png’.format(filename)), lbl)是生成彩色图
这个地方根据你的需要进行选择。
具体操作:
1.打开cmd,激活anaconda的虚拟环境。并进入到你想要保存的路径位置。
2.输入指令 E:\Anaconda2\Scripts\labelme_json_to_dataset.exe D:\json,如下图。
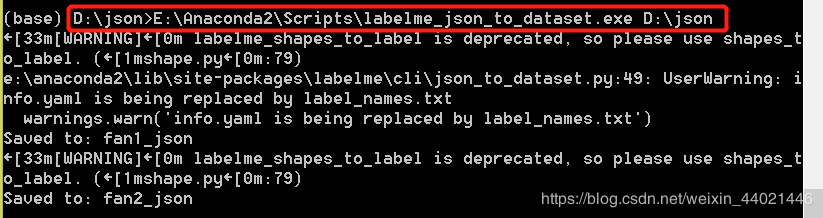
其中,前面的D:\json> :这个地方是你要把批量处理后的文件放入到这个地方,想放到哪里就进入他的路径,然后执行上面的语句。
E:\Anaconda2\Scripts\labelme_json_to_dataset.exe :是我程序所在的路径 。
D:\json :是我labelme手工标注后保存的json文件的路径。
执行上面语句后生成的结果如下:
5.批量提取标签图像
上面的步骤生成的是每个json文件对应的文件夹,如果去每个文件夹提取标签图像,无疑任务量也是巨大的。下面给出批量复制的代码:
import os
import random
import shutil
import re
GT_from_PATH = "D:\json"
GT_to_PATH = "D:\json\gts"
def copy_file(from_dir, to_dir, Name_list):
if not os.path.isdir(to_dir):
os.mkdir(to_dir)
# 1
# name_list = os.listdir(from_dir)
# # 2
# sample = random.sample(pathDir, 2)
# print(sample)
# 3
for name in Name_list:
try:
# print(name)
if not os.path.isfile(os.path.join(from_dir, name)):
print("{} is not existed".format(os.path.join(from_dir, name)))
shutil.copy(os.path.join(from_dir, name), os.path.join(to_dir, name))
# print("{} has copied to {}".format(os.path.join(from_dir, name), os.path.join(to_dir, name)))
except:
# print("failed to move {}".format(from_dir + name))
pass
# shutil.copyfile(fileDir+name, tarDir+name)
print("{} has copied to {}".format(from_dir, to_dir))
if __name__ == '__main__':
filepath_list = os.listdir(GT_from_PATH)
# print(name_list)
for i, file_path in enumerate(filepath_list):
gt_path = "{}\{}_gt.png".format(os.path.join(GT_from_PATH, filepath_list[i]), file_path[:-5])
print("copy {} to ...".format(gt_path))
gt_name = ["{}_gt.png".format(file_path[:-5])]
gt_file_path = os.path.join(GT_from_PATH, file_path)
copy_file(gt_file_path, GT_to_PATH, gt_name)
其中,GT_from_PATH = “D:\json” 这个地方应该设置你json文件的路径
GT_to_PATH = “D:\json\gts” 这个地方应该设置你的存放路径
执行:python extract_gt.py 就可以生成

6.图像和标签同时进行数据处理
在自制数据的时候,如果存在的样本数量较少或者需要对样本进行数据增强处理,可以参考这个方法。这个方法可以保证图像和标签同时进行处理,而不需要在重新标注。
1.使用Augmentor模块
在cmd下,进入anaconda虚拟环境,安装Augmentor
pip install Augmentor
安装完成后就可以使用Augmentor模块了。使用方法如下:
#导入数据增强工具
import Augmentor
#确定原始图像存储路径以及掩码文件存储路径
p = Augmentor.Pipeline("test1")
p.ground_truth("test2")
#图像旋转: 按照概率0.8执行,最大左旋角度10,最大右旋角度10
p.rotate(probability=0.8, max_left_rotation=10, max_right_rotation=10)
#图像左右互换: 按照概率0.5执行
p.flip_left_right(probability=0.5)
#图像放大缩小: 按照概率0.8执行,面积为原始图0.85倍
p.zoom_random(probability=0.3, percentage_area=0.85)
#最终扩充的数据样本数
p.sample(20)
其中,p = Augmentor.Pipeline(“test1”) 是原图的路径
p.ground_truth(“test2”) 是标签图的路径
p.sample(20),这个是需要的样本数,可以根据自己需要设置。
需要注意的是,采用这个方法,需要将原图和标签设置为一样的名称,并且后缀名也是一样的。


数据增强后的保存路径在test1文件下会自动创建一个output文件夹,作为增强后保存的文件夹。
2.使用PIL模块
# -*- coding:utf-8 -*-
"""数据增强
1. 翻转变换 flip
2. 随机修剪 random crop
3. 色彩抖动 color jittering
4. 平移变换 shift
5. 尺度变换 scale
6. 对比度变换 contrast
7. 噪声扰动 noise
8. 旋转变换/反射变换 Rotation/reflection
"""
from PIL import Image, ImageEnhance, ImageOps, ImageFile
import numpy as np
import random
import threading, os, time
import logging
logger = logging.getLogger(__name__)
ImageFile.LOAD_TRUNCATED_IMAGES = True
class DataAugmentation:
"""
包含数据增强的八种方式
"""
def __init__(self):
pass
@staticmethod
def openImage(image):
return Image.open(image, mode="r")
@staticmethod
def randomRotation(image, label, mode=Image.BICUBIC):
"""
对图像进行随机任意角度(0~360度)旋转
:param mode 邻近插值,双线性插值,双三次B样条插值(default)
:param image PIL的图像image
:return: 旋转转之后的图像
"""
random_angle = np.random.randint(1, 360)
return image.rotate(random_angle, mode) , label.rotate(random_angle, Image.NEAREST)
#暂时未使用这个函数
@staticmethod
def randomCrop(image, label):
"""
对图像随意剪切,考虑到图像大小范围(68,68),使用一个一个大于(36*36)的窗口进行截图
:param image: PIL的图像image
:return: 剪切之后的图像
"""
image_width = image.size[0]
image_height = image.size[1]
crop_win_size = np.random.randint(40, 68)
random_region = (
(image_width - crop_win_size) >> 1, (image_height - crop_win_size) >> 1, (image_width + crop_win_size) >> 1,
(image_height + crop_win_size) >> 1)
return image.crop(random_region), label
@staticmethod
def randomColor(image, label):
"""
对图像进行颜色抖动
:param image: PIL的图像image
:return: 有颜色色差的图像image
"""
random_factor = np.random.randint(0, 31) / 10. # 随机因子
color_image = ImageEnhance.Color(image).enhance(random_factor) # 调整图像的饱和度
random_factor = np.random.randint(10, 21) / 10. # 随机因子
brightness_image = ImageEnhance.Brightness(color_image).enhance(random_factor) # 调整图像的亮度
random_factor = np.random.randint(10, 21) / 10. # 随机因1子
contrast_image = ImageEnhance.Contrast(brightness_image).enhance(random_factor) # 调整图像对比度
random_factor = np.random.randint(0, 31) / 10. # 随机因子
return ImageEnhance.Sharpness(contrast_image).enhance(random_factor) ,label # 调整图像锐度
@staticmethod
def randomGaussian(image, label, mean=0.2, sigma=0.3):
"""
对图像进行高斯噪声处理
:param image:
:return:
"""
def gaussianNoisy(im, mean=0.2, sigma=0.3):
"""
对图像做高斯噪音处理
:param im: 单通道图像
:param mean: 偏移量
:param sigma: 标准差
:return:
"""
for _i in range(len(im)):
im[_i] += random.gauss(mean, sigma)
return im
# 将图像转化成数组
img = np.asarray(image)
img.flags.writeable = True # 将数组改为读写模式
width, height = img.shape[:2]
img_r = gaussianNoisy(img[:, :, 0].flatten(), mean, sigma)
img_g = gaussianNoisy(img[:, :, 1].flatten(), mean, sigma)
img_b = gaussianNoisy(img[:, :, 2].flatten(), mean, sigma)
img[:, :, 0] = img_r.reshape([width, height])
img[:, :, 1] = img_g.reshape([width, height])
img[:, :, 2] = img_b.reshape([width, height])
return Image.fromarray(np.uint8(img)), label
@staticmethod
def saveImage(image, path):
image.save(path)
def makeDir(path):
try:
if not os.path.exists(path):
if not os.path.isfile(path):
# os.mkdir(path)
os.makedirs(path)
return 0
else:
return 1
except Exception, e:
print str(e)
return -2
def imageOps(func_name, image, label, img_des_path, label_des_path , img_file_name, label_file_name, times=5):
funcMap = {"randomRotation": DataAugmentation.randomRotation,
"randomCrop": DataAugmentation.randomCrop,
"randomColor": DataAugmentation.randomColor,
"randomGaussian": DataAugmentation.randomGaussian
}
if funcMap.get(func_name) is None:
logger.error("%s is not exist", func_name)
return -1
for _i in range(0, times, 1):
new_image , new_label = funcMap[func_name](image,label)
DataAugmentation.saveImage(new_image, os.path.join(img_des_path, func_name + str(_i) + img_file_name))
DataAugmentation.saveImage(new_label, os.path.join(label_des_path, func_name + str(_i) + label_file_name))
opsList = {"randomRotation", "randomColor", "randomGaussian"}
def threadOPS(img_path, new_img_path, label_path, new_label_path):
"""
多线程处理事务
:param src_path: 资源文件
:param des_path: 目的地文件
:return:
"""
#img path
if os.path.isdir(img_path):
img_names = os.listdir(img_path)
else:
img_names = [img_path]
#label path
if os.path.isdir(label_path):
label_names = os.listdir(label_path)
else:
label_names = [label_path]
img_num = 0
label_num = 0
#img num
for img_name in img_names:
tmp_img_name = os.path.join(img_path, img_name)
if os.path.isdir(tmp_img_name):
print('contain file folder')
exit()
else:
img_num = img_num + 1;
#label num
for label_name in label_names:
tmp_label_name = os.path.join(label_path, label_name)
if os.path.isdir(tmp_label_name):
print('contain file folder')
exit()
else:
label_num = label_num + 1
if img_num != label_num:
print('the num of img and label is not equl')
exit()
else:
num = img_num
for i in range(num):
img_name = img_names[i]
print img_name
label_name = label_names[i]
print label_name
tmp_img_name = os.path.join(img_path, img_name)
tmp_label_name = os.path.join(label_path, label_name)
# 读取文件并进行操作
image = DataAugmentation.openImage(tmp_img_name)
label = DataAugmentation.openImage(tmp_label_name)
threadImage = [0] * 5
_index = 0
for ops_name in opsList:
threadImage[_index] = threading.Thread(target=imageOps,
args=(ops_name, image, label, new_img_path, new_label_path, img_name, label_name))
threadImage[_index].start()
_index += 1
time.sleep(0.2)
if __name__ == '__main__':
threadOPS("test1",
"test1",
"test2",
"test2")
保存为PIL_augment_image.py
其中,threadOPS(“test1”,
“test1”,
“test2”,
“test2”)
第一个test1是图像所在的路径
第二个test1是数据增强后保存的路径
第一个test2是标签所在的路径
第二个test2是数据增强后保存的路径
执行:python PIL_augment_image.py

对图像进行高斯噪声处理时,出现这个错误。
解决方法:pip install numpy==1.15.4
最后的结果如下图:

7.更改指定标签颜色
需要在你安装的anaconda的目录下找到 …\labelme\utils\draw.py
我的路径在E:\Anaconda2\Lib\site-packages\labelme\utils\draw.py
因为我的任务是只要标注一类对象,故用下面的代码
import io
import os.path as osp
import numpy as np
import PIL.Image
import PIL.ImageDraw
import PIL.ImageFont
def label_colormap(N=256):
def bitget(byteval, idx):
return ((byteval & (1 << idx)) != 0)
cmap = np.zeros((N, 3))
for i in range(0, N):
id = i
r, g, b = 0, 0, 0
for j in range(0, 8):
if i==1:
r=64
g=128
b=192
else:
r = np.bitwise_or(r, (bitget(id, 0) << 7 - j))
g = np.bitwise_or(g, (bitget(id, 1) << 7 - j))
b = np.bitwise_or(b, (bitget(id, 2) << 7 - j))
id = (id >> 3)
cmap[i, 0] = r
cmap[i, 1] = g
cmap[i, 2] = b
cmap = cmap.astype(np.float32) / 255
return cmap
def _validate_colormap(colormap, n_labels):
if colormap is None:
colormap = label_colormap(n_labels)
else:
assert colormap.shape == (colormap.shape[0], 3), \
'colormap must be sequence of RGB values'
assert 0 <= colormap.min() and colormap.max() <= 1, \
'colormap must ranges 0 to 1'
return colormap
# similar function as skimage.color.label2rgb
def label2rgb(
lbl, img=None, n_labels=None, alpha=0.5, thresh_suppress=0, colormap=None,
):
if n_labels is None:
n_labels = len(np.unique(lbl))
colormap = _validate_colormap(colormap, n_labels)
colormap = (colormap * 255).astype(np.uint8)
lbl_viz = colormap[lbl]
lbl_viz[lbl == -1] = (0, 0, 0) # unlabeled
if img is not None:
img_gray = PIL.Image.fromarray(img).convert('LA')
img_gray = np.asarray(img_gray.convert('RGB'))
# img_gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# img_gray = cv2.cvtColor(img_gray, cv2.COLOR_GRAY2RGB)
lbl_viz = alpha * lbl_viz + (1 - alpha) * img_gray
lbl_viz = lbl_viz.astype(np.uint8)
return lbl_viz
def draw_label(label, img=None, label_names=None, colormap=None, **kwargs):
"""Draw pixel-wise label with colorization and label names.
label: ndarray, (H, W)
Pixel-wise labels to colorize.
img: ndarray, (H, W, 3), optional
Image on which the colorized label will be drawn.
label_names: iterable
List of label names.
"""
import matplotlib.pyplot as plt
backend_org = plt.rcParams['backend']
plt.switch_backend('agg')
plt.subplots_adjust(left=0, right=1, top=1, bottom=0,
wspace=0, hspace=0)
plt.margins(0, 0)
plt.gca().xaxis.set_major_locator(plt.NullLocator())
plt.gca().yaxis.set_major_locator(plt.NullLocator())
if label_names is None:
label_names = [str(l) for l in range(label.max() + 1)]
colormap = _validate_colormap(colormap, len(label_names))
label_viz = label2rgb(
label, img, n_labels=len(label_names), colormap=colormap, **kwargs
)
plt.imshow(label_viz)
plt.axis('off')
plt_handlers = []
plt_titles = []
for label_value, label_name in enumerate(label_names):
if label_value not in label:
continue
fc = colormap[label_value]
p = plt.Rectangle((0, 0), 1, 1, fc=fc)
plt_handlers.append(p)
plt_titles.append('{value}: {name}'
.format(value=label_value, name=label_name))
plt.legend(plt_handlers, plt_titles, loc='lower right', framealpha=.5)
f = io.BytesIO()
plt.savefig(f, bbox_inches='tight', pad_inches=0)
plt.cla()
plt.close()
plt.switch_backend(backend_org)
out_size = (label_viz.shape[1], label_viz.shape[0])
out = PIL.Image.open(f).resize(out_size, PIL.Image.BILINEAR).convert('RGB')
out = np.asarray(out)
return out
def draw_instances(
image=None,
bboxes=None,
labels=None,
masks=None,
captions=None,
):
import matplotlib
# TODO(wkentaro)
assert image is not None
assert bboxes is not None
assert labels is not None
assert masks is None
assert captions is not None
viz = PIL.Image.fromarray(image)
draw = PIL.ImageDraw.ImageDraw(viz)
font_path = osp.join(
osp.dirname(matplotlib.__file__),
'mpl-data/fonts/ttf/DejaVuSans.ttf'
)
font = PIL.ImageFont.truetype(font_path)
colormap = label_colormap(255)
for bbox, label, caption in zip(bboxes, labels, captions):
color = colormap[label]
color = tuple((color * 255).astype(np.uint8).tolist())
xmin, ymin, xmax, ymax = bbox
draw.rectangle((xmin, ymin, xmax, ymax), outline=color)
draw.text((xmin, ymin), caption, font=font)
return np.asarray(viz)
我用的rgb值分别是64,128,192.更改后的结果如下图:

如果你有两类及以上对象,可以根据代码修改你要的值。
好了,暂时就先到这里,如果后面有其他的操作,我会及时更新!
以上操作可以参考以下链接
1.json文件批量转化
2.用labelme制作语义分割数据集
3.Augmentor增强数据
4.PIL增强数据的方法
5.labelme制作语义分割数据集改变掩码(mask)的颜色