Python数据分析:快速制作餐饮行业商业化报告
前些天有个朋友向我求救,他们公司最近要针对餐饮行业做数据分析,并为某些商家做出线上营销方案。但是他一头雾水,不知道该从哪方面下手。
我提醒他,是否先从商家的线上评价作为数据分析的入口例如美团、大众点评、饿了么等等。 朋友点头称是:”是个好主意,但是具体怎么做呢?“
于是我花了点时间用Python帮他做了一个基于线上商家评价的数据分析演示。
本章知识点
商家评价数据源的获取
pyecharts 柱状图数据分析
pyecharts 饼图数据分析
Python的Counter使用方法
商家评价数据源的获取
首先我们要找到合适的商家评价,在本文以大众点评的数据为例,我随机选择一家餐厅的评价数据作为数据源。
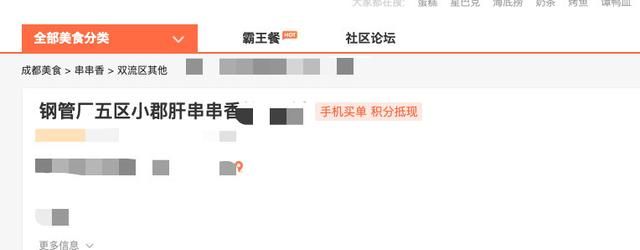
因为隐私的关系,我隐去了商家具体的店名和地址,最终我通过线上的API接口拿到了一部分用户评价数据,用于本次演示,如果出于真正的商业目的需要获得更完整的数据,还需要大家自己去想办法。
拿到的商家评价演示数据如下:
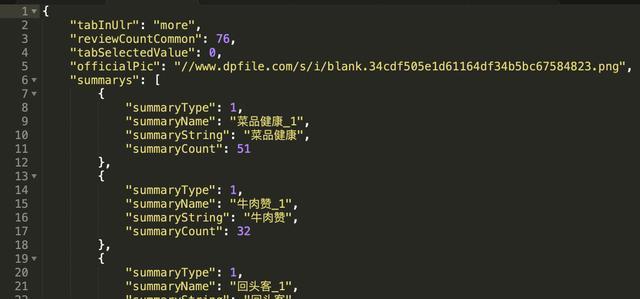
需要注意的是,我们需要对返回的数据内容做一下处理,把数据里的true、false、null分别转换为Python语言所需要的True、False和None。原因在于这里线上数据API接口返回时是按照javascript的数据类型来的(true、false、null)。
数据清洗了之后,我们发现这个数据在Python其实就是一个大的字典,那么我们按照字典的格式对其中的数据进行解析即可。
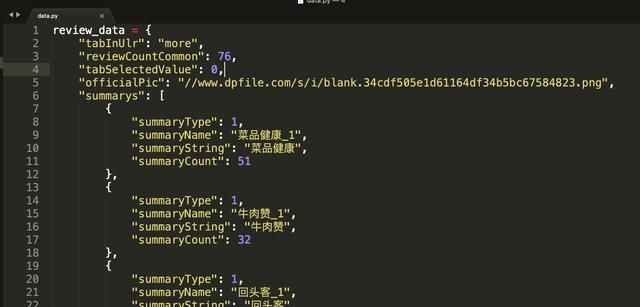
现在我给这个大字典命名为review_data,并保存为data.py文件,方便在正式的数据分析程序里进行import使用。
随后我新建了一个名为analysis.py的文件用于数据分析,并导入刚才的数据源测试一下数据是否正常。
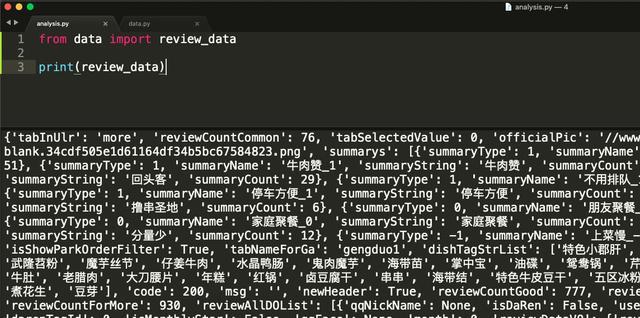
OK,至此我们的数据准备工作已经做好,开始进行实战吧。
个性化的pyecharts柱状图
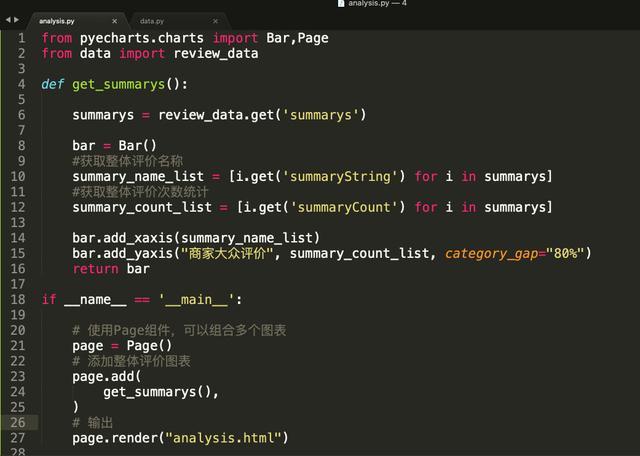
首先我们来获取概要性的数据分析,就是用户对于该商家的整体印象嘛,这部分数据在review_data的summarys里,让我们写一段程序把它取出来进行展示。
最后图表显示效果如下:
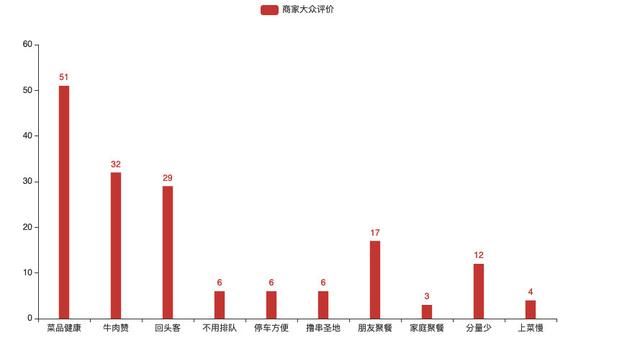
看来这家店菜品比较新鲜、牛肉也不错、老顾客也相对较多,不过分量好像挺少,哈哈。 接着我们来解析下我们的代码:
程序入口从18行开始,Page组件就不多说了,上一章讲过,作用是在一个页面里显示多个图表。
get_summarys()函数主要用于创建一个商家整体评价的柱状图,需要讲的是第10行和12行
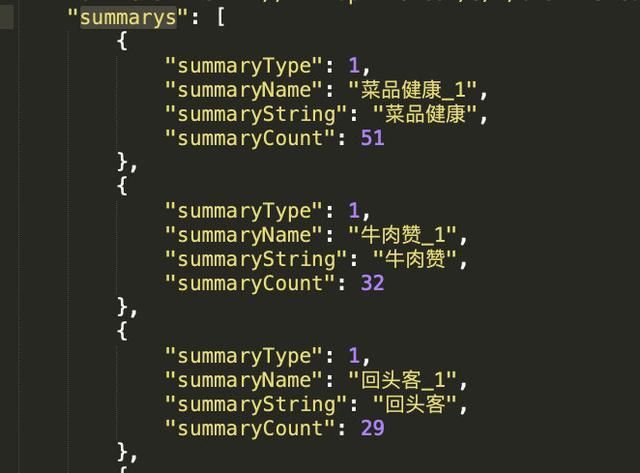
我们发现sumarrys的数据其实是一个list(列表)包含着多个dict(字典)数据。
那么我们的柱状图希望得到的格式数据应该是下面这样:
X轴数据 [‘菜品健康’,'牛肉赞','回头客'] ,X轴数据用于显示名称。
Y轴数据[51,32,29],Y轴数据用于显示数量。
所以我们就用Python的列表推导式分别得到了X,Y轴的数据。
#获取整体评价名称
summary_name_list = [i.get('summaryString') for i in summarys]
#获取整体评价次数统计
summary_count_list = [i.get('summaryCount') for i in summarys]关于add_yaxis()函数里有个category_gap需要解释一下,它的作用是设置同一系列的柱间距离,默认为类目间距的 20%,可设固定值。在这里我设置为80%,就显得柱子比较远,看起来更清晰一点。
拿到X,Y轴的数据后就没什么好说的了,直接添加即可。
个性化的pyecharts饼图
接下来我想获取该商家的用户打分比例,我们知道在很多点评网站上,用户的分数从1-5颗星星不等。
那么在本文中这些数据是怎么体现的呢?
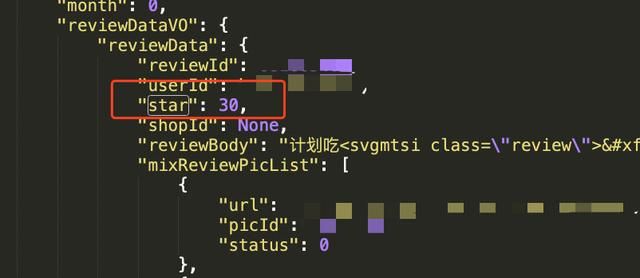
通过分析数据,我们可以发现每个用户的评论里都包含一个叫star的数据,这里就是用户的打分,30分代表3星。
现在我们写一段代码来把打分数据做成饼图。
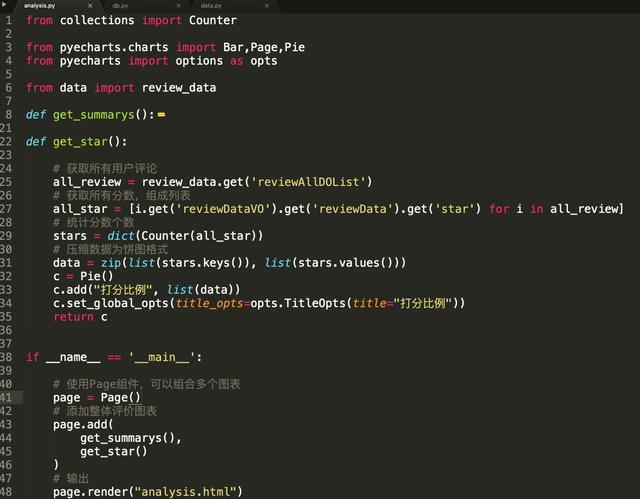
在截图里为了看起来方便我隐藏了之前get_summarys()函数,大家只需要关心get_star()函数即可。
Python的Counter使用方法
Counter库是Python自带的一个计数工具,主要用于对序列里的数据进行计数,非常方便快捷,不用我们自己造轮子了。
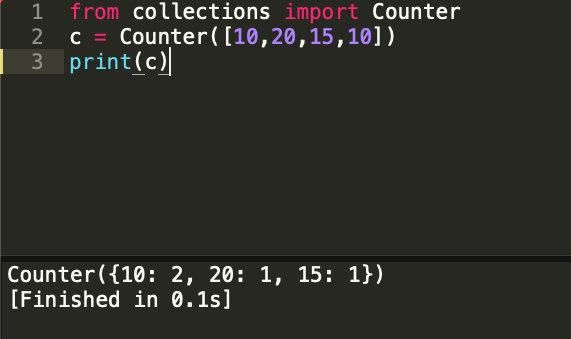
以上三行代码可以很快帮助我们明白Counter的用途,经过它的统计,我们可以发现列表里10数字有2个,其他数字只有1个。
那么回到刚才的打分数据里,我们通过
all_star = [i.get('reviewDataVO').get('reviewData').get('star') for i in all_review]这段代码获取到了所有的打分数据。看起来像这样:
[30, 50, 10, 20, 35, 50, 30, 20, 50, 20]那么我们可以很方便的用Counter对其进行统计即可。
stars = dict(Counter(all_star))在这里之所以要用dict对Counter结果进行转换成字典,是为了方便我们获取字典的keys和values,正好可以作为饼图所需的数据。大家也可以通过其他方式获取所需内容,不用拘泥于这一种方式。
饼图所需数据
最后的数据压缩代码里:
data = zip(list(stars.keys()), list(stars.values()))stars.keys()和starts.values()其实分别就是分数和该分数的个数 stars这个字典原始数据如下:
{30: 2, 50: 3, 10: 1, 20: 3, 35: 1}之所以要用list把keys()和values()的结果转换成列表,也是因为直接获取字典的keys()和values()得到的数据没办法直接使用,需要先转换成列表才行。
到现在为止,我们基本上可以熟练的使用本章学到的知识来对数据进行各种分析了。
最后我得到了四个图表,用于对一家店铺的初步数据分析。
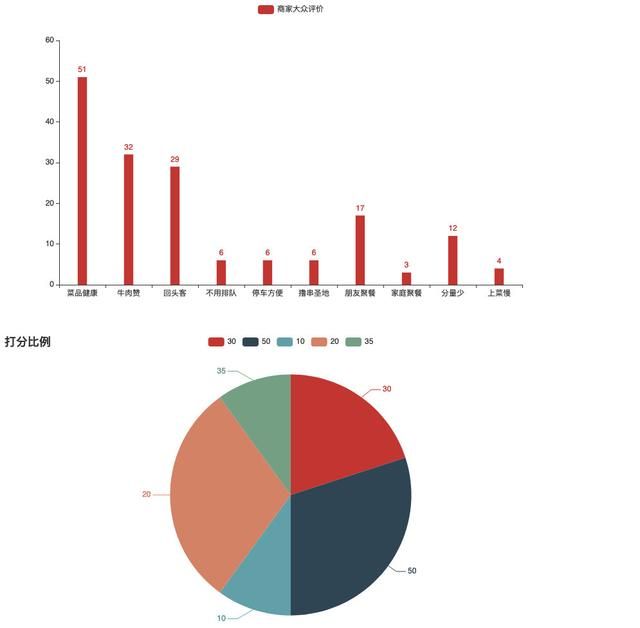
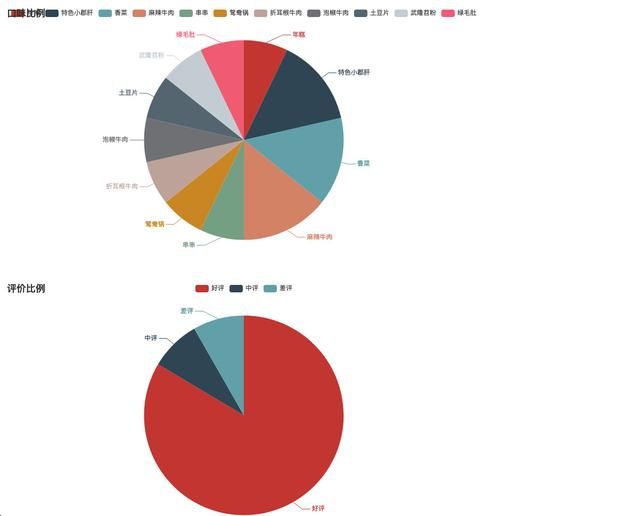
通过对pyecharts的深度学习,以及Python自带的各种统计工具的配合使用,我们可以做出更多有价值的数据分析案例,当这些案例慢慢成型后,就变成了一套完整的商业解决方案,希望大家可以从中得到启发。
文源网络,仅供学习之用,侵删。
在学习Python的道路上肯定会遇见困难,别慌,我这里有一套学习资料,包含40+本电子书,800+个教学视频,涉及Python基础、爬虫、框架、数据分析、机器学习等,不怕你学不会! https://shimo.im/docs/JWCghr8prjCVCxxK/ 《Python学习资料》
关注公众号【Python圈子】,优质文章每日送达。
