prometheus-operator自定义配置实践详解
文章目录
- 一、prometheus-operator的基本原理
- 二、部署前的准备工作
- 三、自定义抓取target
- 举个例子
- 遇到的问题
- 再举一个例子:
- 四、自定义告警规则rule
- 1、 告警规则对应关系
- 2、添加告警规则
- 3、修改或删除告警规则
- 五、自定义告警方式alertmanager
- 1、 自定义alertmanager
- 2、邮件模板
- 3、 配置钉钉告警
- 3.1 配置钉钉 webhook
- 3.2 修改钉钉通知模板
- 3.3 模板中的外链问题
- 4、 prometheus如何同时多个方式发送
- 六、自定义Prometheus配置文件
- 七、其他遇到的问题
- 1、 grafana使用的持久化存储是阿里云nas,以静态pv的形式创建grafana-deploy后,报错
- proemtheus无法创建 “ContainerCreating”报错:secret "etcd-https" not found
- 2、prometheus-k8s-0 notready 503,如下
一、prometheus-operator的基本原理
二、部署前的准备工作
- 给node打标签,让Prometheus,alertmanager,grafana都部署到同一台机器上
kubectl label node node1 kubernetes.io/app=prometheus
- 监控数据的持久化(pv)
使用动态还是静态?建议动态。
阿里云环境下可以使用阿里云nas来存储。提前创建好持久化存储
- 创建命名空间
kubectl create namespace monitoring
三、自定义抓取target
当我们一键安装完operator后,可以看到已经监控了一些target,它是怎么实现的?怎么自定义呢?

三个步骤:servicemonitor + service + endpoint
举个例子
1) 执行manifest目录下的prometheus-serviceMonitorKubeScheduler.yaml
会生成这个
![]()
2)vim kube-scheduler-svc.yml,填入3个master的IP
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler
spec:
#selector:
# component: kube-scheduler
type: ClusterIP
ports:
- name: http-metrics
port: 10251
targetPort: 10251
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
name: kube-scheduler
namespace: kube-system
labels:
k8s-app: kube-scheduler
# component: kube-scheduler
subsets:
- addresses:
- ip: x.x.x.x
#nodeName: master1
- ip: x.x.x.x
#nodeName: master2
- ip: x.x.x.x
#nodeName: master3
ports:
- name: http-metrics
port: 10251
protocol: TCP
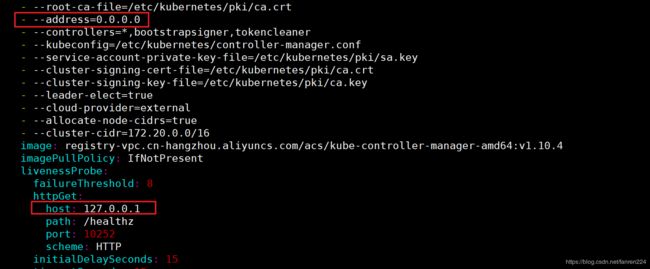
遇到的问题
1、get 。。。。 connection refused

解决办法:
vim /etc/kubernetes/manifests/kube-controller-manager.yaml
将address=127.0.0.1改为
再举一个例子:
如何监控etcd?在etcd是二进制部署的情况下
参考: http://www.mydlq.club/article/18/
1、查看etcd的service文件找到证书路径
cat /etc/systemd/system/multi-user.target.wants/etcd.service
查到路径为
--ca-file=/var/lib/etcd/cert/ca.pem
--cert-file=/var/lib/etcd/cert/etcd-server.pem
--key-file=/var/lib/etcd/cert/etcd-server-key.pem
2、将三个证书文件存入 Kubernetes 的 Secret 资源下
kubectl create secret generic etcd-certs --from-file=/var/lib/etcd/cert/etcd-server.pem --from-file=/var/lib/etcd/cert/etcd-server-key.pem --from-file=/var/lib/etcd/cert/ca.pem -n monitoring
3、将证书挂入 Prometheus
kubectl edit prometheus k8s -n monitoring
.....
secrets: #------新增证书配置,将etcd证书挂入
- etcd-certs
完成后进入 Pod 中查看:
# kubectl exec -it prometheus-k8s-0 /bin/sh -n monitoring
/prometheus $ ls /etc/prometheus/secrets/etcd-certs/
ca.pem etcd-server-key.pem etcd-server.pem
4、创建 Etcd Service + Endpoints + servicemonitor
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: etcd-k8s
labels:
k8s-app: etcd
spec:
type: ClusterIP
ports:
- name: http-metrics
port: 2379
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
namespace: kube-system
name: etcd-k8s
labels:
k8s-app: etcd
subsets:
- addresses:
- ip: 10.x.x.125
nodeName: etcd1
- ip: 10.x.x.21
nodeName: etcd2
- ip: 10.x.x.97
nodeName: etcd3
ports:
- name: http-metrics
port: 2379
protocol: TCP
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd-k8s
labels:
k8s-app: etcd-k8s
namespace: monitoring
spec:
jobLabel: k8s-app
endpoints:
- port: http-metrics
interval: 30s
scheme: https
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-https/ca.pem
certFile: /etc/prometheus/secrets/etcd-https/node-master1.pem
keyFile: /etc/prometheus/secrets/etcd-https/node-master1-key.pem
#use insecureSkipVerify only if you cannot use a Subject Alternative Name
insecureSkipVerify: true
serverName: ETCD
selector:
matchLabels:
k8s-app: etcd
namespaceSelector:
matchNames:
- kube-system
四、自定义告警规则rule
1、 告警规则对应关系
prometheus-operator/contrib/kube-prometheus/manifests/prometheus-rules.yaml 生成
km describe cm prometheus-k8s-rulefiles-0 被引用
prometheus-k8s-0这个pod下的/etc/prometheus/rules/prometheus-k8s-rulefiles-0/monitoring-prometheus-k8s-rules.yaml
2、添加告警规则
创建文件 prometheus-etcdRules.yaml:
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: etcd-rules
namespace: monitoring
spec:
groups:
- name: etcd
rules:
- alert: EtcdClusterUnavailable
annotations:
summary: etcd cluster small
description: If one more etcd peer goes down the cluster will be unavailable
expr: |
count(up{job="etcd"} == 0) > (count(up{job="etcd"}) / 2 - 1)
for: 3m
labels:
severity: critical
注意 label 标签一定至少要有 prometheus=k8s 和 role=alert-rules,创建完成后,隔一会儿再去容器中查看下 rules 文件夹,会自动在上面的 prometheus-k8s-rulefiles-0 目录下面生成一个对应的
kubectl exec -it prometheus-k8s-0 /bin/sh -n monitoring
Defaulting container name to prometheus.
Use 'kubectl describe pod/prometheus-k8s-0 -n monitoring' to see all of the containers in this pod.
/prometheus $ ls /etc/prometheus/rules/prometheus-k8s-rulefiles-0/
monitoring-etcd-rules.yaml monitoring-prometheus-k8s-rules.yaml
可以看到我们创建的 rule 文件已经被注入到了对应的 rulefiles 文件夹下面了,证明我们上面的设想是正确的。然后再去 Prometheus Dashboard 的 Alert 页面下面就可以查看到上面我们新建的报警规则了:
3、修改或删除告警规则
1、 在prometheus-operator/contrib/kube-prometheus/manifests目录下
先备份原来的prometheus-rules.yaml为prometheus-rules.yaml.default
2、修改vim prometheus-rules.yaml,修改完成后apply
3、 进入pod中kubectl exec -it prometheus-k8s-0 /bin/sh -n monitoring
查看上面注释删除掉告警是否已经不存在了
cat /etc/prometheus/rules/prometheus-k8s-rulefiles-0/monitoring-prometheus-k8s-rules.yaml |grep xx
4、进入Prometheus web界面,查看规则是否已经删除。
五、自定义告警方式alertmanager
1、 自定义alertmanager
查看当前配置
km get secret alertmanager-main -o yaml 查看data
或者直接下面的命令提取
km get secret alertmanager-main -o yaml |grep alertmanager.yaml |awk -F: '{print $2}'|sed -e 's/^ //'
echo "Z2Cgxxxxx==" |base64 -d
创建新配置
vim alertmanager.yaml
global:
resolve_timeout: 5m # 当Alertmanager持续多长时间未接收到告警后,标记告警状态为resolved(已解决)
http_config: {}
smtp_smarthost: 'smtp.exmail.qq.com:25'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: '123456'
smtp_hello: 'example.com'
smtp_require_tls: false
route:
receiver: sa_dingtalk
group_wait: 30s
group_interval: 30m
repeat_interval: 5h
group_by: ['alertname','service']
routes:
- receiver: '456'
match:
alertname: "Node状态NotReady超过2分钟了"
routes:
- receiver: 'null' #null有单引号
group_wait: 30s
group_interval: 12h
repeat_interval: 24h
match:
alertname: "Pod当前重启次数超过1000次","Pod状态CrashLoopBackOff,超过1h了" #匹配多个用,隔开
- receiver: 'dba'
group_wait: 10s
match_re:
service: mysql|cassandra
routes:
- receiver: test_dingtalk
group_wait: 10s
match:
team: node
receivers:
- name: test_dingtalk
webhook_configs:
- url: 'http://10.180.3.101:8060/dingtalk/webhook1/send'
send_resolved: true
- name: sa_dingtalk
webhook_configs:
- url: 'http://10.180.3.101:8060/dingtalk/webhook2/send'
send_resolved: true
- name: 'mail'
email_configs:
- to: '[email protected],[email protected]' # 多个邮件地址用逗号分隔
send_resolved: true
receivers:
- name: '456'
email_configs:
- to: '[email protected]'
send_resolved: true
- name: 'null' # 空的receiver,不发送。
templates: []
应用新配置
# 先将之前的 secret 对象删除
$ kubectl delete secret alertmanager-main -n monitoring
secret "alertmanager-main" deleted
$ kubectl create secret generic alertmanager-main --from-file=alertmanager.yaml -n monitoring
secret "alertmanager-main" created
查看是否生效
2、邮件模板
自带的邮件模板效果如下(模板文件在:(https://github.com/prometheus/alertmanager/blob/master/template/default.tmpl))
密密麻麻,看的人头大,其实就算它很好看,没有修改的需求,我们也应该知道该如何自定义

那么怎么自定义呢?
1、创建一个template1.tmpl ,如下
{{ define "template1.html" }}
环境
告警
主机
描述
开始时间
{{ range $i, $alert := .Alerts }}
{{ index $alert.Labels "env" }}
{{ index $alert.Labels "alertname" }}
{{ index $alert.Labels "node" }}
{{ index $alert.message "value" }}
{{ $alert.StartsAt }}
{{ end }}
{{ end }}
2、对这个模板文件进行base64编码
base64 template1.tmpl
或者
https://tool.oschina.net/encrypt?type=3
3、编辑secret,形式如下
km edit secret alertmanager-main
apiVersion:v1
kind:secret
metadata:
name:alertmanager-main
data:
alertmanager.yaml:xxxxxxxxxx
template_1.tmpl:xxxxxxxxxxx
完成后查看是否生成
[root@master1 mail]# km exec -it alertmanager-main-0 /bin/sh
Defaulting container name to alertmanager.
Use 'kubectl describe pod/alertmanager-main-0 -n monitoring' to see all of the containers in this pod.
/etc/alertmanager $ cat config/template1.tmpl
{{ define "template1.html" }}
环境
告警
主机
描述
开始时间
{{ range $i, $alert := .Alerts }}
{{ index $alert.Labels "env" }}
{{ index $alert.Labels "alertname" }}
{{ index $alert.Labels "node" }}
{{ index $alert.message "value" }}
{{ $alert.StartsAt }}
{{ end }}
/etc/alertmanager $ exit
4、alertmanager.yaml中需要有如下字段
templates:
- '*.tmpl'
5、效果大体如下

3、 配置钉钉告警
3.1 配置钉钉 webhook
1、先安装go环境,GOPATH="/root/go"
cd /root/go/src/github.com/timonwong/
git clone https://github.com/timonwong/prometheus-webhook-dingtalk.git
cd prometheus-webhook-dingtalk
make (生成二进制文件prometheus-webhook-dingtalk)
2、启动
nohup ./prometheus-webhook-dingtalk --ding.profile="webhook1=https://oapi.dingtalk.com/robot/send?access_token=691af599f562280274081553f93d7e7c69fdca869361dba14f3dc362c0ab0c" --ding.profile="webhook2=https://oapi.dingtalk.com/robot/send?access_token=8c66d9539a43af9b089deb6d5e19653e1be6d61c872c31fbc2778f0edab234" --template.file="custom723.tmpl" > dingding.log 2>&1 &
netstat -anpt | grep 8060
3、用systemd管理
先写一个启动脚本
cd /data/monitor/custom/k8s-receiver/dingding/
[root@master1 dingding]# vim dingtalk_start.sh
#!/bin/bash
cd /data/monitor/custom/k8s-receiver/dingding/
nohup ./prometheus-webhook-dingtalk --ding.profile=webhook1=https://oapi.dingtalk.com/robot/send?access_token=1902b0032dbfc6b99ca113b71eac1a36354594e747f66f7b2dde04bab888d5 --template.file=default1.tmpl > dingding.log 2>&1 &
vim /usr/lib/systemd/system/prometheus-dingtalk.service
[Unit]
Description=prometheus dingtalk
After=network-online.target
[Service]
Type=forking
ExecStart=/usr/bin/sh /data/monitor/custom/k8s-receiver/dingding/dingtalk_start.sh
Restart=always
RestartSec=20
[Install]
WantedBy=multi-user.target

3.2 修改钉钉通知模板
{{ define "__subject" }}**[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}]** {{ .GroupLabels.SortedPairs.Values | join " " }} {{ if gt (len .CommonLabels) (len .GroupLabels) }}({{ with .CommonLabels.Remove .GroupLabels.Names }}**{{ .Values | join " " }}**{{ end }}){{ end }}{{ end }}
{{ define "__alertmanagerURL" }}{{ .ExternalURL }}/#/alerts?receiver={{ .Receiver }}{{ end }}
{{ define "__text_alert_list" }}{{ range . }}
{{ range .Labels.SortedPairs }}
{{ if eq .Name "severity" }}> 【告警等级】: {{ .Value | markdown | html }}{{ end }}
{{ if eq .Name "env" }}> 【环境】: {{ .Value | markdown | html }}{{ end }}
{{ if eq .Name "namespace" }}> 【命名空间】: {{ .Value | markdown | html }}{{ end }}
{{ if eq .Name "daemonset" }}> 【daemonset】: {{ .Value | markdown | html }}{{ end }}
{{ if eq .Name "deployment" }}> 【deployment】: {{ .Value | markdown | html }}{{ end }}
{{ if eq .Name "pod" }}> 【pod名称】: {{ .Value | markdown | html }}{{ end }}
{{ if eq .Name "container" }}> 【容器】: {{ .Value | markdown | html }}{{ end }}
{{ if eq .Name "node" }}> 【主机名】: {{ .Value | markdown | html }}{{ end }}
{{ end }}
{{ range .Annotations.SortedPairs }}
{{ if eq .Name "message" }}> 【描述】: {{ .Value | markdown | html }}{{ end }}
{{ end }}
> 【触发时间】: {{ .StartsAt.Format "2006-01-02 15:04:05" }}
[查看详情]({{ .GeneratorURL }})
{{ end }}{{ end }}
{{ define "ding.link.title" }}{{ template "__subject" . }}{{ end }}
{{ define "ding.link.content" }}#### \[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}\] **[{{ index .GroupLabels "alertname" }}]({{ template "__alertmanagerURL" . }})**
{{ template "__text_alert_list" .Alerts.Firing }}
{{ end }}
3.3 模板中的外链问题
1、修改prometheus-k8s的external-url
km edit statefulset prometheus-k8s
spec:
containers:
- args:
- --web.console.templates=/etc/prometheus/consoles
- --web.console.libraries=/etc/prometheus/console_libraries
- --config.file=/etc/prometheus/config_out/prometheus.env.yaml
- --storage.tsdb.path=/prometheus
- --storage.tsdb.retention=7d
- --web.enable-lifecycle
- --storage.tsdb.no-lockfile
- --web.route-prefix=/
- --web.external-url=http://xxxx:30004
2、修改alertmanager-main的external-url
https://theo.im/blog/2017/10/16/release-prometheus-alertmanager-webhook-for-dingtalk/
https://www.qikqiak.com/post/prometheus-operator-custom-alert/
3、模板效果
告警模板

恢复模板:待验证
{{ define "__subject" }}[{{ if eq .Status "firing" }}告警:{{ .Alerts.Firing | len }}{{ else }}已恢复{{ end }}] {{ .GroupLabels.SortedPairs.Values | join " " }} {{ if gt (len .CommonLabels) (len .GroupLabels) }}({{ with .CommonLabels.Remove .GroupLabels.Names }}**{{ .Values | join " " }}**{{ end }}){{ end }}{{ end }}
{{ define "__alertmanagerURL" }}{{ .ExternalURL }}/#/alerts?receiver={{ .Receiver }}{{ end }}
{{ define "__text_alert_list" }}{{ range . }}
{{ range .Labels.SortedPairs }}
{{ if eq .Name "env" }}> 【环境】: {{ .Value | markdown | html }}{{ end }}
{{ if eq .Name "namespace" }}> 【命名空间】: {{ .Value | markdown | html }}{{ end }}
{{ if eq .Name "daemonset" }}> 【daemonset】: {{ .Value | markdown | html }}{{ end }}
{{ if eq .Name "deployment" }}> 【deployment】: {{ .Value | markdown | html }}{{ end }}
{{ if eq .Name "pod" }}> 【pod名称】: {{ .Value | markdown | html }}{{ end }}
{{ if eq .Name "container" }}> 【容器】: {{ .Value | markdown | html }}{{ end }}
{{ if eq .Name "node" }}> 【主机】: {{ .Value | markdown | html }}{{ end }}
{{ if eq .Name "instance" }}> 【实例】: {{ .Value | markdown | html }}{{ end }}
{{ end }}
{{ range .Annotations.SortedPairs }}
{{ if eq .Name "message" }}> 【描述】: {{ .Value | markdown | html }}{{ end }}
{{ end }}
> 【触发时间】: {{ .StartsAt.Format "2006-01-02 15:04:05" }}
[查看详情]({{ .GeneratorURL }})
{{ end }}{{ end }}
{{ define "ding.link.title" }}{{ template "__subject" . }}{{ end }}
{{ define "ding.link.content" }}#### \[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}\] **[{{ index .GroupLabels "alertname" }}]({{ template "__alertmanagerURL" . }})**
{{ template "__text_alert_list" .Alerts.Firing }}
{{ end }}

4、 prometheus如何同时多个方式发送
背景: 有时我们需要将告警信息同时发送给多个渠道(例如短信或邮件),那么我们的 Alertmanager 该如何配置呢?
使用版本:Alertmanager 版本: 0.13.0
方法一
在同一个 recevier 定义多个接收渠道,例如:
route:
receiver: my-receiver
receivers:
- name: my-receiver
webhook_configs:
- url: 'https://hooks.xxx.com/xxxx'
email_configs:
- to: 'xx@xxxx'
auth_username: 'xxx'
auth_password: 'xxx'
说明: 可以看到同一条消息既使用 webhook 又使用 email 配置,所有在这两个渠道我们都收到消息。
方法二
route:
receiver: email # 默认配置一个
routes:
- match:
severity: Critical
continue: true
receiver: webhook
- match:
severity: Critical
receiver: email
receivers:
- name: webhook
webhook_configs:
- url: 'https://hooks.xxx.com/xxxx'
- name: email
email_configs:
- to: 'xx@xxxx'
auth_username: 'xxx'
auth_password: 'xxx'
定义多个独立的 receiver, 然后使用 routes 中的 continue 选项进行配置:
如果在route中设置continue为false,那么告警在匹配到第一个子节点之后就直接停止。
说明: 我们采用独立的两个 receiver 来接收消息,通过配置多个 routes 进行分发控制。
总结
我们可以使用以上两种方式实现同一条消息发送给不同渠道的效果,但是如果你的告警消息具有多类责任人(组),那么应该采用多个 routes 来分发消息,因为一个 receiver 代表了同一类接收者,这样配置也更灵活。
六、自定义Prometheus配置文件
自带的prometheus.yaml是只读的,没法修改,那怎么搞呢?
以istio为例,istio有个自带的prometheus,跟集群已有的重复了,我想用已有的prometheus抓取istio的监控怎么做。
1、把istio的prometheus配置(在浏览器上直接复制过来,只复制job_name就行了)写入一个文件prometheus-additional.yaml,内容如下
- job_name: istio-mesh
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- istio-system
relabel_configs:
。。。。
2、把这个文件创建为一个secret对象
$ kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoring
secret "additional-configs" created
3、进入 Prometheus Operator 源码的contrib/kube-prometheus/manifests/目录,修改prometheus-prometheus.yaml这个文件,添加additionalScrapeConfigs配置
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
additionalScrapeConfigs:
name: additional-configs
key: prometheus-additional.yaml
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: v2.5.0
添加完成后,apply下这个文件:
$ kubectl apply -f prometheus-prometheus.yaml
prometheus.monitoring.coreos.com “k8s” configured
4、在浏览器上查看配置文件已生效,,但是 targets 页面下却并没有发现对应的监控任务,查看 Prometheus 的 Pod 日志:
$ kubectl logs -f prometheus-k8s-0 prometheus -n monitoring
level=error ts=2018-12-20T15:14:06.772903214Z caller=main.go:240 component=k8s_client_runtime err="github.com/prometheus/prometheus/discovery/kubernetes/kubernetes.go:302: Failed to list *v1.Pod: pods is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list pods at the cluster scope"
level=error ts=2018-12-20T15:14:06.773096875Z caller=main.go:240 component=k8s_client_runtime err="github.com/prometheus/prometheus/discovery/kubernetes/kubernetes.go:301: Failed to list *v1.Service: services is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list services at the cluster scope"
level=error ts=2018-12-20T15:14:06.773212629Z caller=main.go:240 component=k8s_client_runtime err="github.com/prometheus/prometheus/discovery/kubernetes/kubernetes.go:300: Failed to list *v1.Endpoints: endpoints is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list endpoints at the cluster scope"
......
可以看到有很多错误日志出现,都是xxx is forbidden,这说明是 RBAC 权限的问题,通过 prometheus 资源对象的配置可以知道 Prometheus 绑定了一个名为 prometheus-k8s 的 ServiceAccount 对象,而这个对象绑定的是一个名为 prometheus-k8s 的 ClusterRole:(prometheus-clusterRole.yaml)
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus-k8s
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
上面的权限规则与istio监控的所需要权限规则不一样,我们查看istio监控需要的权限clusterrole,是这个prometheus-istio-system,如下,与集群本身的不一样,对比一下
$ ki get clusterrole prometheus-istio-system -o yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
creationTimestamp: 2020-01-13T06:34:24Z
labels:
app: prometheus
name: prometheus-istio-system
ownerReferences:
- apiVersion: istio.alibabacloud.com/v1beta1
blockOwnerDeletion: true
controller: true
kind: Istio
name: istio-config
uid: b1a17482-35ce-11ea-b71f-00163e14c52e
resourceVersion: "197006297"
selfLink: /apis/rbac.authorization.k8s.io/v1/clusterroles/prometheus-istio-system
uid: bd2acac7-35ce-11ea-84cb-00163e116ffe
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- watch
- list
- apiGroups:
- ""
resources:
- configmaps
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
5、在prometheus-clusterRole.yaml中添加没有的权限,然后更新apply下,再重启Prometheus的pod就可以了
6、在浏览器中验证是否生效
参考:https://www.qikqiak.com/post/prometheus-operator-advance/
七、其他遇到的问题
1、 grafana使用的持久化存储是阿里云nas,以静态pv的形式创建grafana-deploy后,报错
mount.nfs: access denied by server while mounting 0a8670-kwv5.cn-hangzhou.nas.aliyuncs.com:/grafana

查看官方帮助文档

解决办法
先 把nas挂载到一个ecs上,然后mkdir grafana。
sudo mount -t nfs -o vers=4,minorversion=0,noresvport 0a60-kwv5.cn-hangzhou.nas.aliyuncs.com:/ /mnt
cd /mnt
mkdir grafana
重新创建deploy后, 报错确变成了,我用的镜像是5.2.4,
[root@iZbp1akZ pv]# km logs grafana-5b584fb868-xj4qz
GF_PATHS_DATA='/var/lib/grafana' is not writable.
You may have issues with file permissions, more information here: http://docs.grafana.org/installation/docker/#migration-from-a-previous-version-of-the-docker-container-to-5-1-or-later
mkdir: cannot create directory '/var/lib/grafana/plugins': Permission denied
参考https://www.qikqiak.com/k8s-book/docs/56.Grafana%E7%9A%84%E5%AE%89%E8%A3%85%E4%BD%BF%E7%94%A8.html ,
5.1镜像之后都会这样
创建job
[root@iZkZ custom]# vim grafana-chown-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: grafana-chown
namespace: monitoring
spec:
template:
spec:
restartPolicy: Never
containers:
- name: grafana-chown
command: ["chown", "-R", "472:472", "/var/lib/grafana"]
image: busybox
imagePullPolicy: IfNotPresent
volumeMounts:
- name: grafana-storage
mountPath: /var/lib/grafana
volumes:
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana-pvc
注意deploy文件是这样

先删除原来的,再创建新的,然后执行job。
proemtheus无法创建 “ContainerCreating”报错:secret “etcd-https” not found

创建文件 vim etcd-https.yaml
apiVersion: v1
data:
ca.pem: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUREakNDQWZhZ0F3SUJBZ0lVSkJza29zU2hCY2MwU1pKQ2FoZzRlTDVyWHFFd0RRWUpLb1pJaHZjTkFRRUwKQlFBd0RURUxNQWtHQTFVRUF4TUNRMEV3SGhjTk1Ua3hNakV6TURnME9UQXdXaGNOTWpReE1qRXhNRGcwT1RBdURDQ0FRb0NnZ0VCCkFPR25LMDB3UTVRMWhYc2tVRUVBcnJHMWQwem03OVhONFM3K1lWR3l4VDl1UlFqWGVjOEU5ZzAxZnUybVJhbEkKSGZ2eDFseHJCOUhjUmkrL01vMFRMQXUyOExhaEpVbnVNdzlHVWo4ME50eGRpTGdRQ1hhTWR4S0NWNENGMGNzSQpRZzJORjZiQm9lWU9GRkZXZXVqblUvNkNzT0o1L29VYnFabkw5TXFvRksxRWdONDVyL01BSzczUU5sMkxOZkQ0Ck1UWTJiOG1EV0p0WE5pektRaFM2b2RCVzlXSHkvMWRWdHpyMVA3ck82bVI0TkhIWkkwdjlkOHpQTUZ2Qnd5S1AKUjFVS1RCQkJrZVkya0o5cVA1L0tqNkdLUm0zOXZsb08zaGJKYkJ3Q3V4WkRpLzMxZVNEQnVOSytabmFManZxSApLekh3c3NSa3ZCS0lCdG9vcXhDMEJFc0NBd0VBQWFObU1HUXdEZ1lEVlIwUEFRSC9CQVFEQWdFR01CSUdBMVVkCkV3RUIvd1FJTUFZQkFmOENBUUl3SFFZRFZSME9CQllFRkl3RFFxOFppb1hPMEc4K1VRVHp4R01LWFRtdU1COEcKQTFVZEl3UVlNQmFBRkl3RFFxOFppb1hPMEc4K1VRVHp4R01LWFRtdU1BMEdDU3FHU0liM0RRRUJDd1VBQTRJQgpBUURkM290NG5BZ2xyMmtuUHVWUHRrcmxZb2RNZElDREs2MlhBWDcyNVBKREh2OVcvOTFpRzNzVXVhaFpJVWFVClFHejB1OCtKZlQ1dGlLNllIcyt3N1M4eE55ZFdSL29jeE9UNUR4RU1tSHo3WFlYUDEzUjZIYVl3YUNXL2JCNVUKUGxIMVJPdGtheitaV1o2Ykx1TWhwYitTV1lQekl6eGdVUzlFeDRRYWhVbi9IU01Ha0ZUcWhTY0E3cUM4eFh5ZApGckc2emFlSHo0Q3BaOENsRGoybUJDOXNDTkxUT09SeXBSZ3YxTTYrYmROMk5QTjVURVdBdjgrMGJLdnZwVFAzCnhrZm1KZGM5Tkx6MVlsT1Vkby83NGhFbTJlektiNGwwK0R2cWwvRUxGeFp5VGZLS0NNeUtCMkVKUmZ2Y1FmTTIKRWZxcDVMaFVHckN6ZmVQdXBrc20vT3EyCi0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS0=
etcd-server-key.pem: LS0tLS1CRUdJTiBSU0EgUFJJVkFURSBLRVktLS0tLQpNSUlFcEFJQkFBS0NBUUVBbUU1NVBFdkwyQlMxQUU5TDZoNVlpLzFjemRsOTdjdVdrMVBSandjYThLVGpTUmNlCkQveG9uSVdYSE5VRm95bjlDYwpsVjNoVmNtcFhhR0JqeC9BNWd5dHFkSncyQ0J2L2tLVEp1SDc2S2tLbzdyYlkyL1VkRmNvS0ZPTVpic1FlOERxClZlK2NXMnpyVEpHTTRscWREOEd4YXFYYk5CVUhxaDlkVm12Z3BuM2ZzWGFFYkQ5M05KempHbW1lWThaZHkvbnIKZEF0Tys5Y29VU0wvZTFZUlNOakJGWjV4YVRyazRmd1B5V0JRL1FJREFRQUJBb0lCQVFDVVJha2Urd2NxaUJZaApoQkQ2amFwVU5rWjNtK2xOYTZwZUtQWlUwR3o0b3YwbHRaeXRvV05TSlhlVU9VQzU0ZkdZM2RYbkZEQUdOQ3pYCmV0UkRLM3FTMk5nN25FRnBqYlF2TjhoT3pzb0lXUHFMNFhQTDh0UzJhYjZJS3BSS1hIZ3kxYWQ0aVpTY1ArNWkKd2cxeUtwWThBb0VpUWdBVlJPc1hCcHhEZ3F6UDk2N2gwZ2owajVmZ1BEU1VweE56M3UxV1pIVlhIR1A1NVRyegptYW12NXBwbnJ4UUNOYlFZOWFvWnpFb1VkcERqNmxwMmRrdThXMElGSlV2TUdUM21taGFYSG5aa0xhc0RjNnNkCjJIOCthSXlsNjg0bkliU0UwL2ViMnlSNEE4UlJHRkoxZW5UVXZMemZtemhLVmtvUlU2QkpWdkg1LzBjeXRrU0wKaURMb3FhQmhBb0dCQU1iRzRKQWh5L0VEc1p6cTFteDN3THl6VjJmZEV5bC9tSmhGNWxVVUpkNUMvV2RDeENncApzUk5BanA5TXBieVdDaDRVNHdqb0dSNklIWUtIL0Y5ZFZlem9hUStCRU50S21WUkMwUldsR0R3MVIvNitMWWdCCkp1MDlva1lmdlNqUTYycis3NUM3UHlDR2lscWliSVJwb0hPTEtEeG15RDVycS9HUFhvY3dKcVpGQW9HQkFNUW0KNTRvQTRoNUp6Y2hPR3NZVTh6cDVPM0Zpa2ZNTDYycTR6Njhzc3NvaVkya3RPRTJIM0draGJiK3hrTDk3aTJtawpMYWJlVExDRWRybEZ5OTBsZFF4M3lMd28wNUhHOE9vOGFQSlU1bkZOSS9kN0N6WVpmUGd1SDVoS3YrMHRtQWF4CkM3V1lmS0cyRUtVUjZUTnBjbzJlZGFGQ2tqRGhRN3BCQ3EvdDdDZFpBb0dBTFdGbUQwSEgvNlFxUG5yV3JUakIKeGRMajE1Qi9PWEFwOUVteEJpZHRaY3JCYzN1b3NNcWo1Sk5PZkV2UllyYVdaTHU4QVdLTHFZN0Z2ZkV4eXN2UwpQQjNyTG1EMjZqbWp1N3J0WlJXbDdNajFRTkZHTDlDamhISVh4QTZtN3RTVGluL2RUWnVTRStqaldVSFBxSU04CjRHUWFzWDk5bzlLTkZMNzRnOENZY2trQ2dZQjlyRU5xcXRnMCthcExyS2NBeEVsMTdGaUdjOVg0dDJsVWppWWEKSVBSSUI3SlRuN0pVRWpqSWJxK0hRdmZ2aHZNeWN3c0F2NnE0NlpXN2JKbUtEY2FwZjFGd0pHUXhJUm9YcVM3QQpIRjhzdG5UVnlkTE1EWmFBMStSTVNaQWdJTGNuaW1Wckt0Q25OeVFBN3JIUHk3Nm1ONkU3K1kvNm0wa3VXeC9DCnloZ2t1UUtCZ1FDRzJxMCtBdU1oNW5Fei94Vy9udmtTTnpNSktNa2N6SGZaOXkyWkV1UFk3NGFtWFk0SXVwRFEKeWxjdnhtZG1ZaE96SG84SjJsM3E5NWlLSmlNY0s1d3AvT2YrM3RFbm1vV3hhSS9PMlJFTVlXTUdiSjE5MEtXTwpSK2dqYkh3NFlITDNjQTV1dmhIODEyazBybWZSRmR2VDQ3WDRGWGxBUFVVQnUrMytzYUs3bVE9PQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQ==
etcd-server.pem: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURRVENDQWltZ0F3SUJBZ0lVYjg3ZFlMOHNoMmd5WTd0WGZ6MERmcVhTZFZZd0RRWUpLb1pJaHZjTkFRRUwKQlFBd0RURUxNQWtHQTFVRUF4TUNRMEV3SUJjTk1Ua3hNakV6TURnME9UQXdXaGdQTWpBMk9URXhNekF3T0RRNQpNREJhTUJZeEZEQVNCZ05WQkFNVEMyVjBZMlF0WTJ4cFpXNTBNSUlCSWpBTkJna3Foa2lHOXcwQkFRRUZBQU9DCkFROEFNSUlCQ2dLQ0FRRUFtRTU1UEA3UwpzMlJ1VU9TeTZueE00Z0J6bnVmUFhJMU8xeWkvenFIYktJZTRPQjBKOHpKY3FVUXRhOGNsL0pHdnNGb3luOUNjCmxWM2hWY21wWGFHQmp4L0E1Z3l0cWRKdzJDQnYva0tUSnVINzZLa0tvN3JiWTIvVWRGY29LRk9NWmJzUWU4RHEKVmUrY1cyenJUSkdNNGxxZEQ4R3hhcVhiTkJVSHFoOWRWbXZncG4zZnNYYUViRDkzTkp6akdtbWVZOFpkeS9ucgpkQXRPKzljb1VTTC9lMVlSU05qQkZaNXhhVHJrNGZ3UHlXQlEvUUlEQVFBQm80R05NSUdLTUE0R0ExVWREd0VCCi93UUVBd0lGb0RBZEJnTlZIU1VFRmpBVUJnZ3JCZ0VGQlFjREFRWUlLd1lCQlFVSEF3SXdEQVlEVlIwVEFRSC8KQkFJd0FEQWRCZ05WSFE0RUZnUVVmK2NWcjF6dlVMalhkdFNzbVlwR1JWZzV5RHd3SHdZRFZSMGpCQmd3Rm9BVQpqQU5DcnhtS2hjN1FiejVSQlBQRVl3cGRPYTR3Q3dZRFZSMFJCQVF3QW9JQU1BMEdDU3FHU0liM0RRRUJDd1VBCkE0SUJBUUNqMmc4cm00bkRrNDRUVGlHelNGaGlVVHF3V3pDNUxBZ3FzcmZTbVZteEp1clFzNkVyVzltQk5TTUMKWW0zQWtjR1ZlOVljWU1rZ05abFVsemtlUzR4bm5DNVlQT3J1VjhtT1QwZjI3NVpEYm1wWmtqd3M5SUJ5bkRLYwpUU0FSR0ZuZzl1UXJZWDRDblBYbjNzQ3UreGI4Y0xNLzhROHFnRnVwUXZtUlhDMFVMa0llYTNmV2xLT3dSZFRZCnlPeXV3Qk40MWlnNGFaMU5yRG51QWRBYzM0MEZPRHVnL3pnQnpCSmh4Tkoydk80ZHUxSmhiM3RVaTZ6S0lKcXAKcGIxNkFUTXJoNExtb3I2VGxzZjJ3WXFOWDRFaDVSL2RFTWVNTEdrc0lIcmpNVWxKSHV0R2F4RVhMaWc5UFdZNQpZb25iWnB4QVJZNnk1Z29CandhSURsOCtSMWF4Ci0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS0=
kind: Secret
metadata:
name: etcd-https
namespace: monitoring
type: Opaque
ca.pem为/etc/kubernetes/pki/etcd/ca.pem的base64编码
etcd-server-key.pem为/etc/kubernetes/pki/etcd/etcd-client-key.pem的base64编码
etcd-server-key.pem为/etc/kubernetes/pki/etcd/etcd-client.pem的base64编码
然后apply这个文件。
2、prometheus-k8s-0 notready 503,如下
1、如果退出码是137,说明是内存不足被oom,在Prometheus所在的node上执行
journalctl -k | grep -i -e memory -e oom来确认,查看机器是否内存不足。
、describe报错为503
![]()
解决办法:在grafana上可以看到prometheus使用的内存超过了limit值,Prometheus所在的node上也有oom的日志。所以可以先稍微提高一下pod的内存限制。
prometheus刚启动的时候占用内存很大,但是过一会就降下来了,到时候就自动恢复了。
在我的机器上prometheus日常情况下使用14G左右,刚启动的时候,有可能会达到23G甚至28G.
